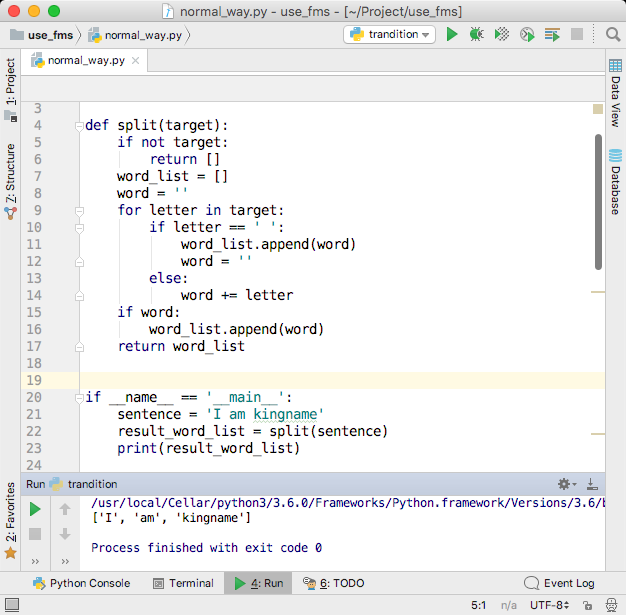
对于只有单词和空格,不含其他符号的英语句子,可以使用空格来切分单词。于是对于句子I am kingname, 一个字符一个字符的进行遍历。首先遍历到I,发现它是一个字母,于是把它存到一个变量word中,然后遍历到空格,于是把变量word的值添加到变量word_list中,再把word清空。接下来遍历到字母a,又把a放到变量word中。再遍历到m,发现它还是一个字母,于是把字母m拼接到变量word的末尾。此时变量word的值为am。再遍历到第二个空格,于是把word的值添加到word_list中,清空word。
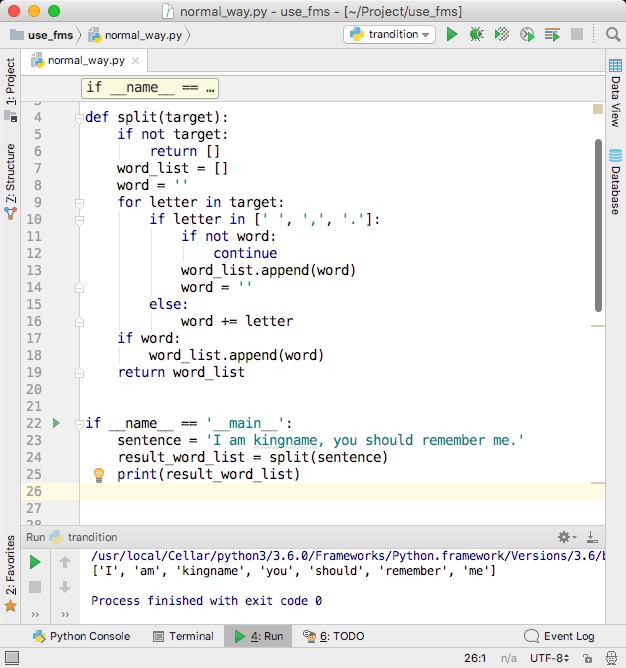
defsplit(target): ifnot target: return [] word_list = [] word = '' for letter in target: if letter == ' ': word_list.append(word) word = '' else: word += letter return word_list
if __name__ == '__main__': sentence = 'I am kingname' result_word_list = split(sentence) print(result_word_list)
运行效果如下图所示。
单词空格与逗号句号
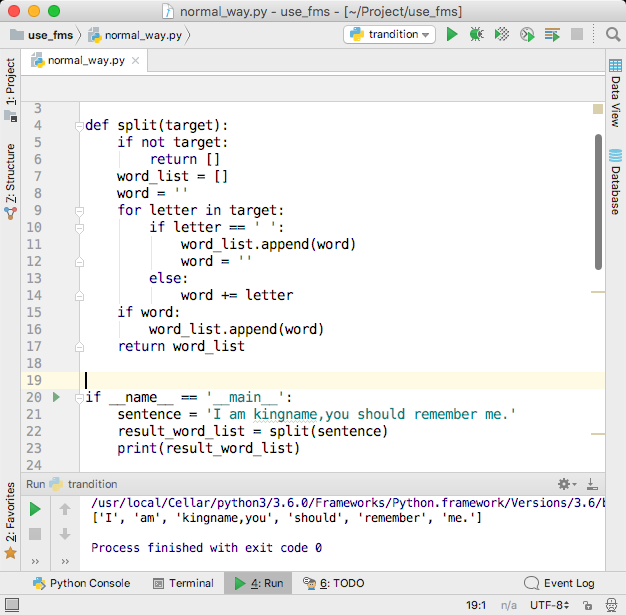
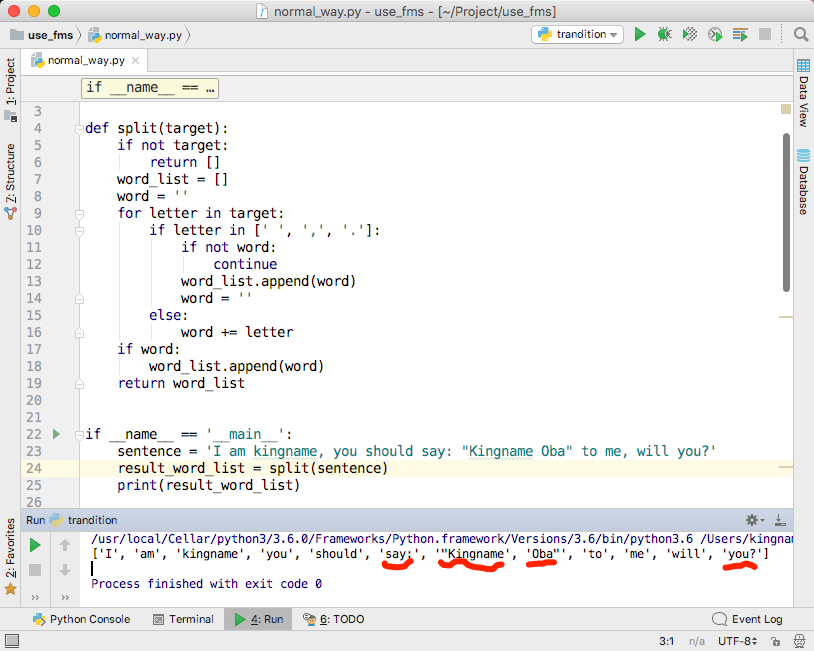
现在不仅仅只有单词和空格,还有逗号和句号。有这样一个句子:”I am kingname,you should remember me.”如果使用上一小节的程序,那么代码就会出现问题,如下图所示。
defsplit(target): ifnot target: return [] word_list = [] word = '' for letter in target: if letter in [' ', ',', '.']: word_list.append(word) word = '' else: word += letter if word: word_list.append(word) return word_list
if __name__ == '__main__': sentence = 'I am kingname,you should remember me.' result_word_list = split(sentence) print(result_word_list)
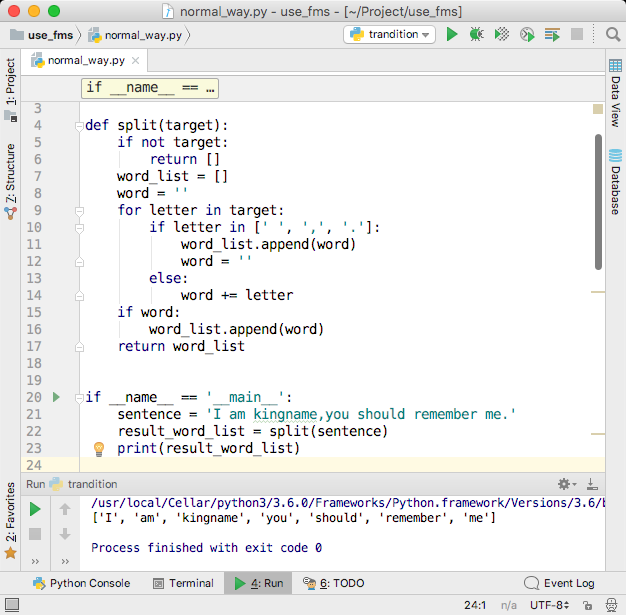
现在运行起来看上去没有问题了,如下图所示。
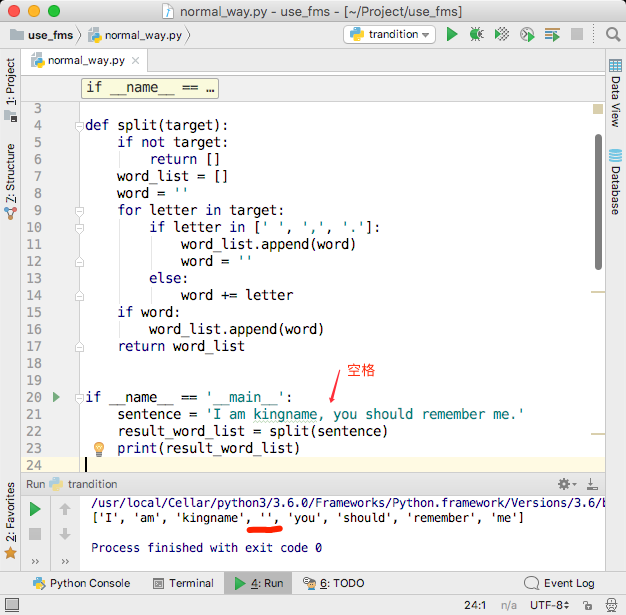
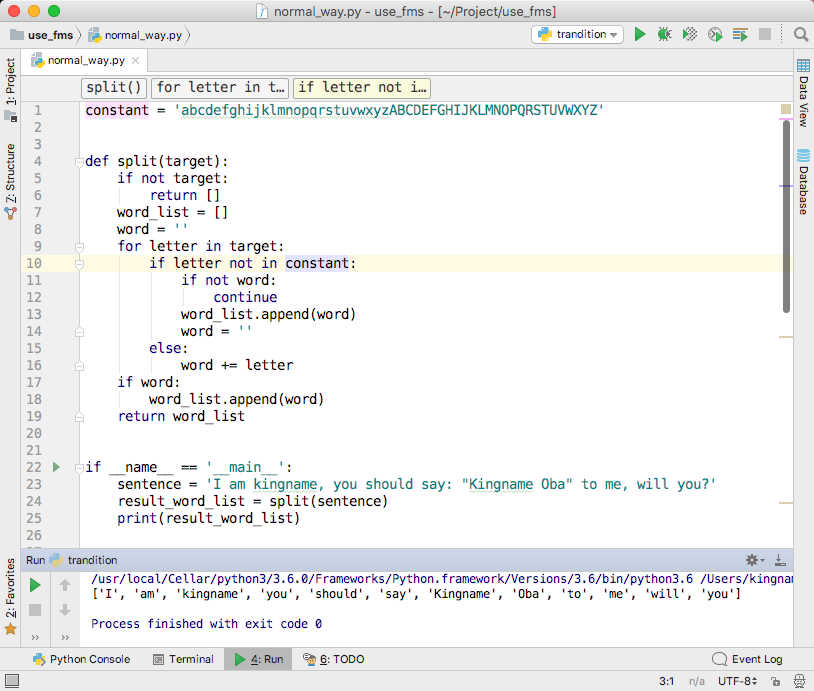
然而,有些人写英文的时候喜欢在标点符号右侧加一个空格,例如:”I am kingname, you should remember me.”这样小小的一修改,上面的代码又出问题了,如下图所示。
defsplit(target): ifnot target: return [] word_list = [] word = '' for letter in target: if letter in [' ', ',', '.']: ifnot word: continue word_list.append(word) word = '' else: word += letter if word: word_list.append(word) return word_list
if __name__ == '__main__': sentence = 'I am kingname, you should remember me.' result_word_list = split(sentence) print(result_word_list)
代码看起来又可以正常工作了。如下图所示。
单词空格与各种标点符号
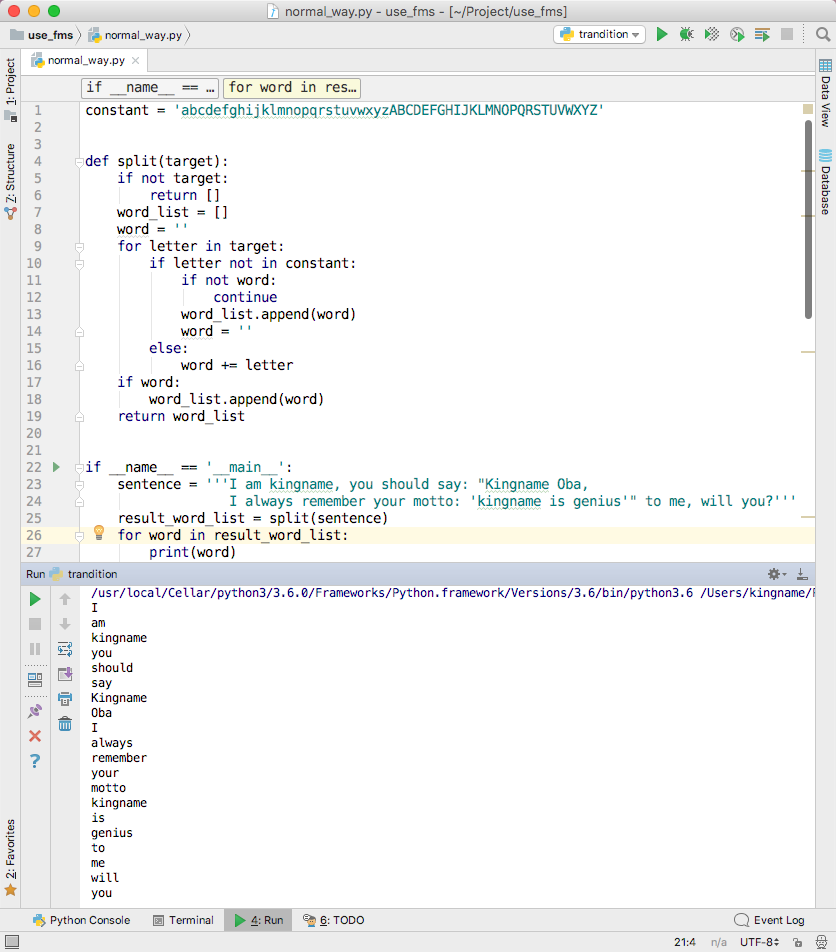
标点符号可不仅仅只有逗号句号。现在又出现了冒号分号双引号感叹号问号等等杂七杂八的符号。英文句子变为:”I am kingname, you should say: “Kingname Oba” to me, will you?”
defsplit(target): ifnot target: return [] word_list = [] word = '' for letter in target: if letter notin constant: ifnot word: continue word_list.append(word) word = '' else: word += letter if word: word_list.append(word) return word_list
if __name__ == '__main__': sentence = 'I am kingname, you should say: "Kingname Oba" to me, will you?' result_word_list = split(sentence) print(result_word_list)
代码修改以后又可以正常工作了,其运行效果如下图所示:
奇奇怪怪的单引号
如果双引号包含的句子里面还需要用到引号,那么就需要在内部使用单引号。例如有这样一个句子:“I am kingname, you should say: “Kingname Oba, I always remember your motto: ‘kingname is genius’” to me, will you?”
使用前面的代码,运行起来似乎没有问题,如下图所示。
但是,单引号还有其他用途——有人喜欢把两个单词合并成一个单词,例如:
“do not” == “don’t”
“is not” == “isn’t”
“I will” == “I’ll”
“I have” == “I’ve”
在这种情况下,就应该把单引号连接的两部分看作是一个单词,不应该把它们切开。
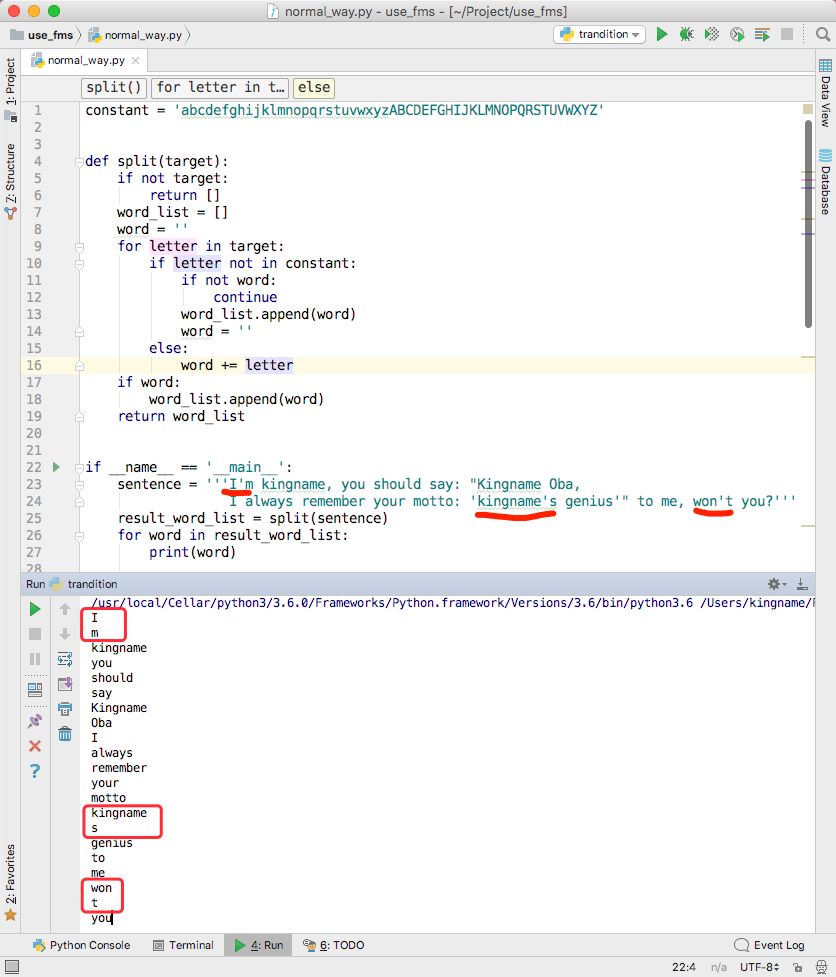
如果句子变成:I'm kingname, you should say: "Kingname Oba, I always remember your motto: 'kingname's genius'" to me, won't you?继续使用上面的代码,就发现返回的单词列表又不对了。如下图所示。
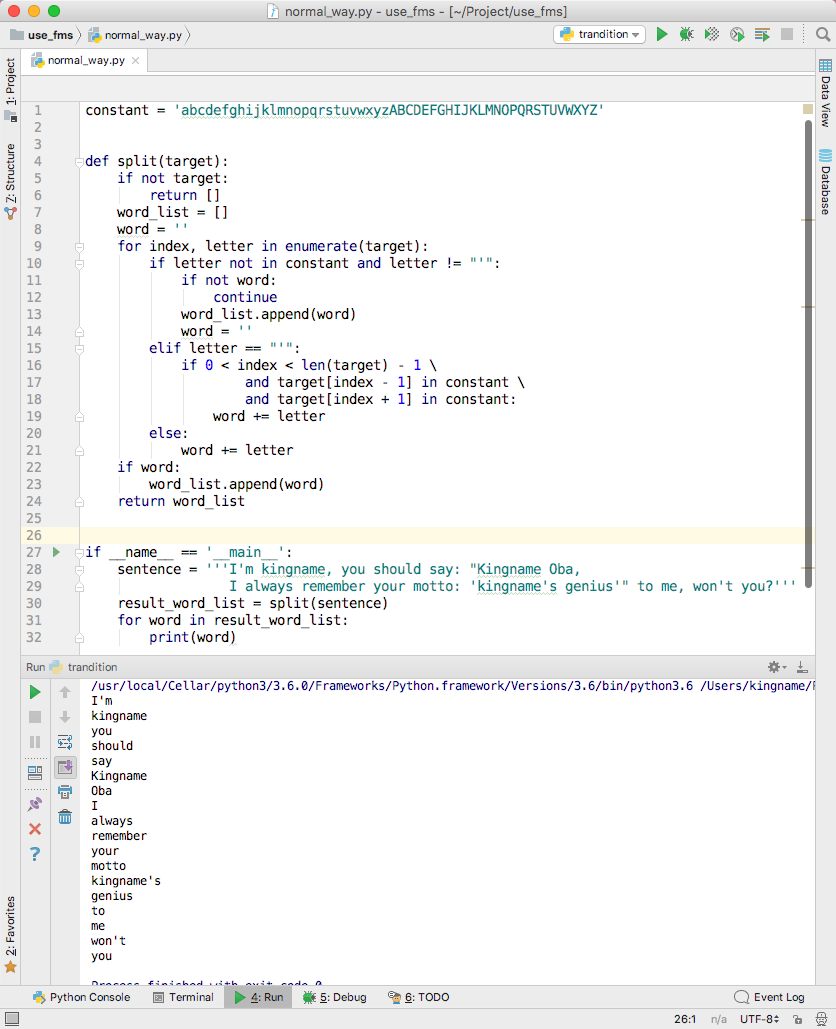
defsplit(target): ifnot target: return [] word_list = [] word = '' for index, letter inenumerate(target): if letter notin constant and letter != "'": ifnot word: continue word_list.append(word) word = '' elif letter == "'": if0 < index < len(target) - 1 \ and target[index - 1] in constant \ and target[index + 1] in constant: word += letter else: word += letter if word: word_list.append(word) return word_list
if __name__ == '__main__': sentence = '''I'm kingname, you should say: "Kingname Oba, I always remember your motto: 'kingname's genius'" to me, won't you?''' result_word_list = split(sentence) for word in result_word_list: print(word)
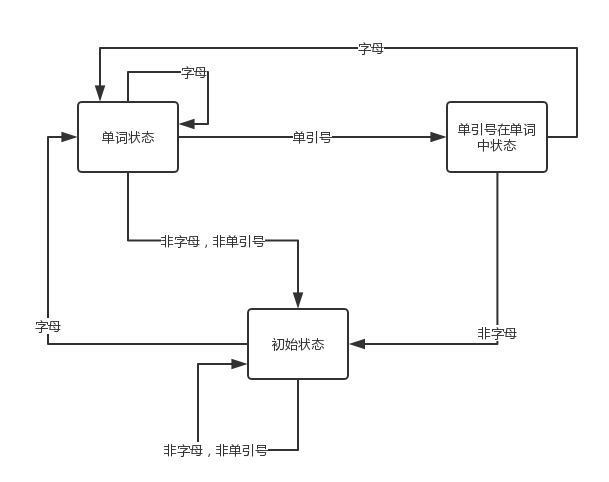
举一个例子:I'm kingname, you should say: "Kingname Oba, I always remember your motto: 'kingname's genius'" to me, won't you?这个句子中,should这个单词就是处于“单词状态”。它不在单引号内部,它也不是一个缩写。当我们对句子每个字符进行遍历的时候,遍历到“should”的“s”时进入“单词状态”,在单词状态,只需要关心接下来过来的下一个字符是什么,如果是字母,那依然是单词状态,把字母直接拼接上来即可。如果是单引号,那么进入“单引号在单词中状态”。至于“单引号在单词中状态”有什么逻辑,单词状态的代码根本不需要知道。这就像是接力赛,我把棒交给下一个人,我的任务就做完了,下一个人是跑到终点还是爬到终点,都和我没有关系。
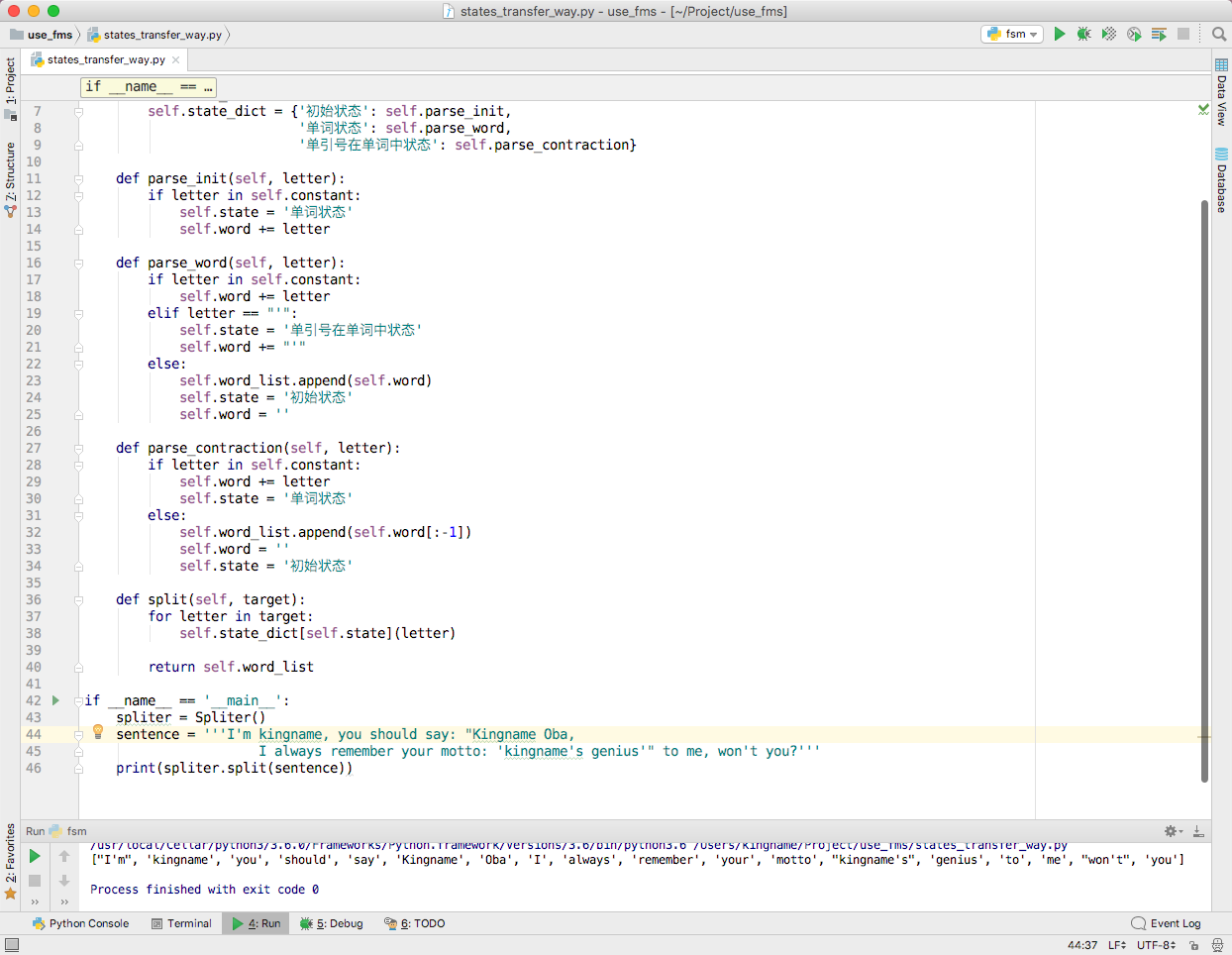
defparse_init(self, letter): if letter in self.constant: self.state = '单词状态' self.word += letter
defparse_word(self, letter): if letter in self.constant: self.word += letter elif letter == "'": self.state = '单引号在单词中状态' self.word += "'" else: self.word_list.append(self.word) self.state = '初始状态' self.word = ''
defparse_contraction(self, letter): if letter in self.constant: self.word += letter self.state = '单词状态' else: self.word_list.append(self.word[:-1]) self.word = '' self.state = '初始状态'
defsplit(self, target): for letter in target: self.state_dict[self.state](letter)
return self.word_list
if __name__ == '__main__': spliter = Spliter() sentence = '''I'm kingname, you should say: "Kingname Oba, I always remember your motto: 'kingname's genius'" to me, won't you?''' print(spliter.split(sentence))