Python读取包里面的数据文件的三种方法
我们知道,写Python代码的时候,如果一个包(package)里面的一个模块要导入另一个模块,那么我们可以使用相对导入:
假设当前代码结构如下图所示:
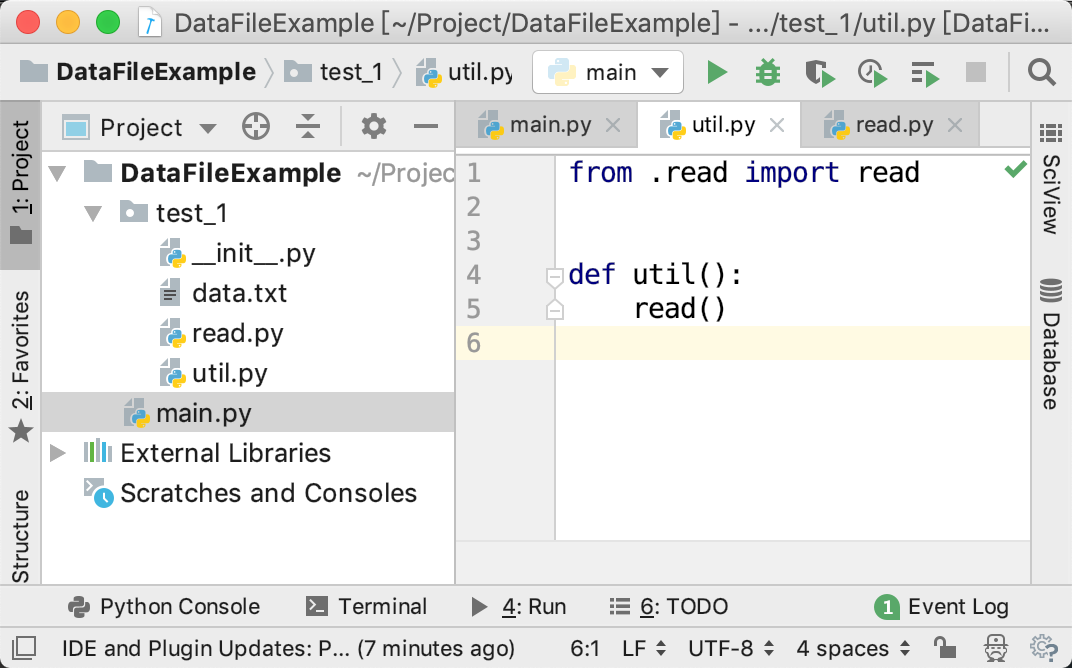
其中test_1是一个包,在util.py里面想导入同一个包里面的read.py中的read函数,那么代码可以写为:
1 | from .read import read |
其中的.read表示当前包目录下的read.py文件。此时read.py文件中的内容如下:
1 | def read(): |
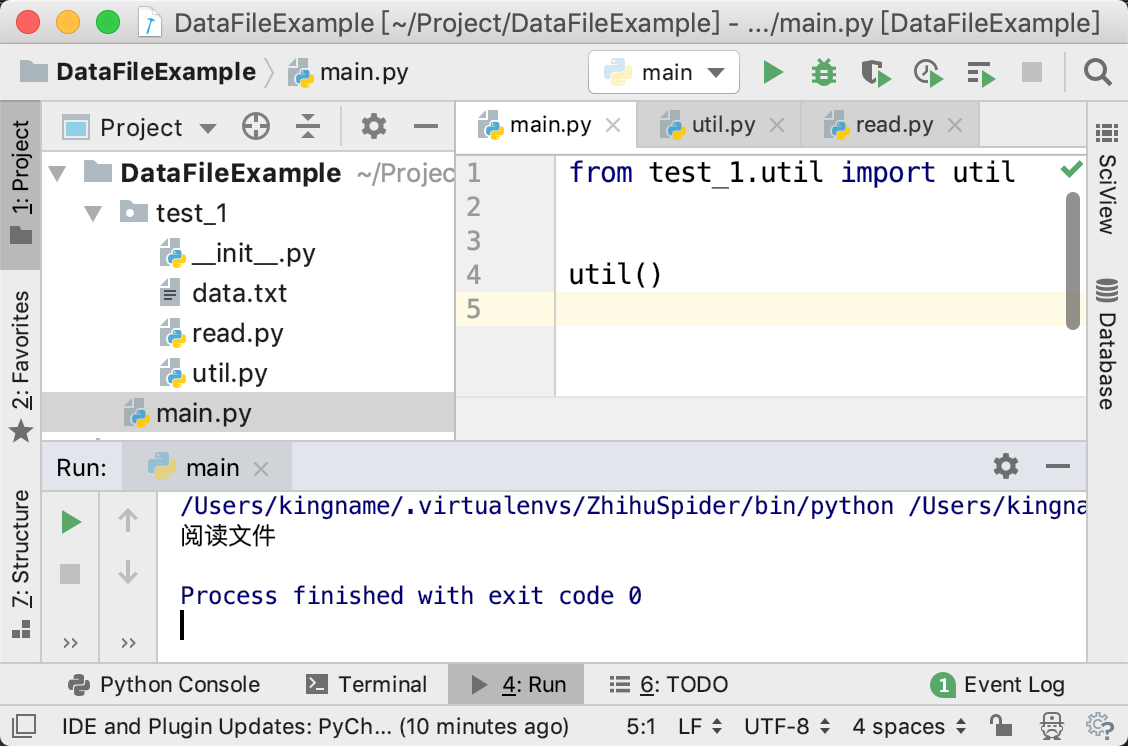
通过包外面的main.py运行代码,运行效果如下图所示:
现在,我们增加一个数据文件,data.txt,它的内容如下图所示:
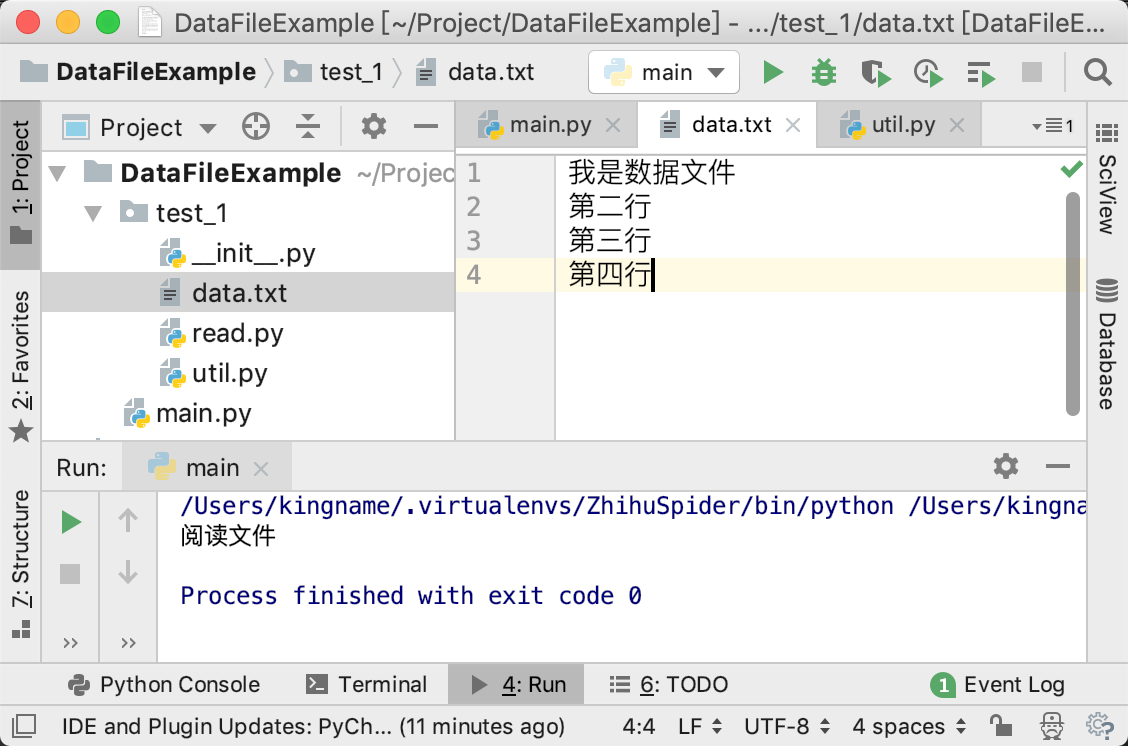
并且想通过read.py去读取这个数据文件并打印出来。
修改read.py,试图使用相对路径来打开这个文件:
1 | def read(): |
运行代码发现报错:
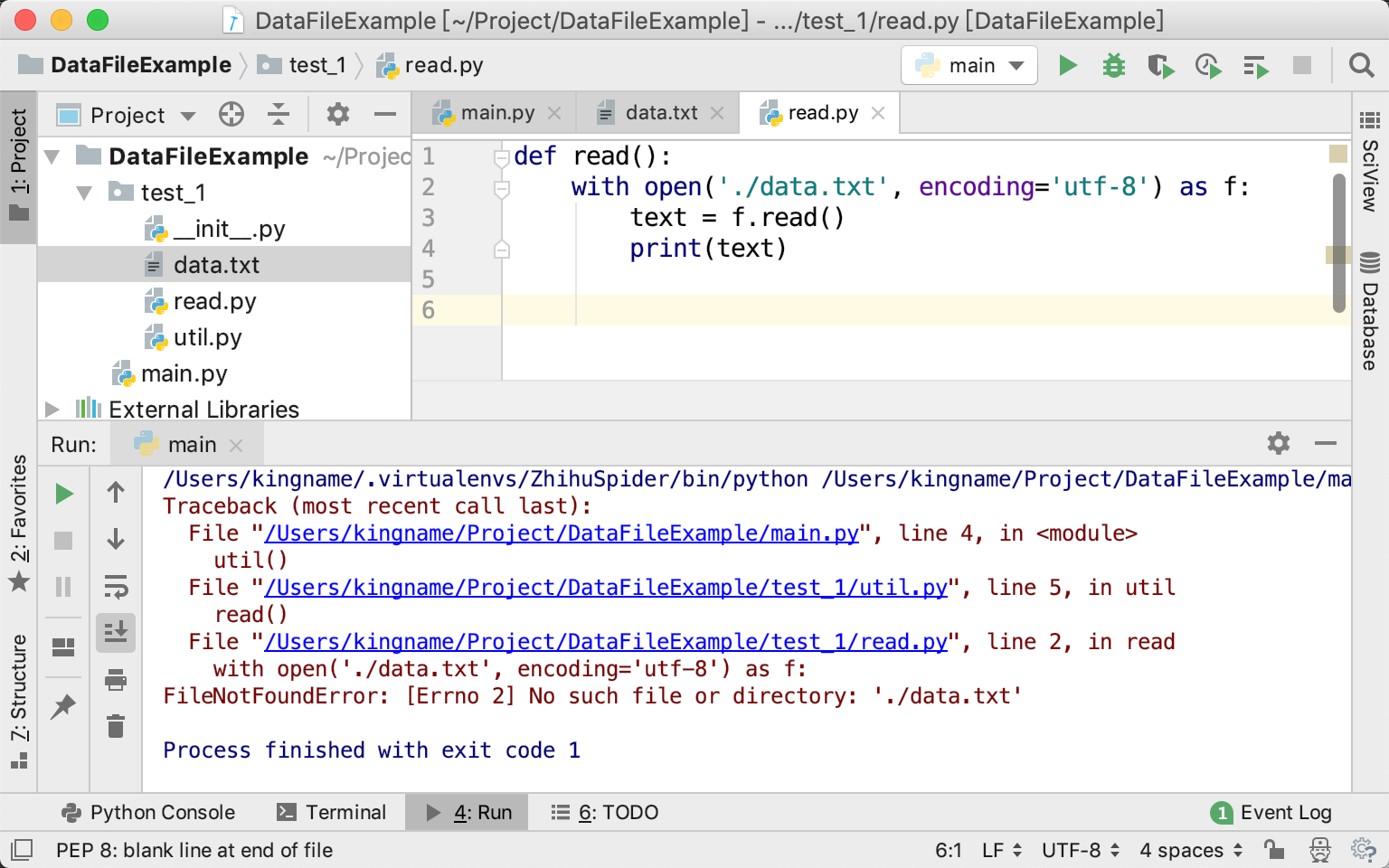
这个原因很简单,就是如果数据文件的地址写为:./data.txt,那么Python就会从当前工作区文件夹里面寻找data.txt。由于我们运行的是main.py,那么当前工作区就是main.py所在的文件夹,而不是test_1文件夹。所以就会出现找不到文件的情况。
为了解决这个问题,我们有三种解决方式。
- 使用绝对路径
1 | def read(): |
运行效果如下图所示:
- 先获取
read.py文件的绝对路径,再拼接出数据文件的绝对路径:
1 | import os |
运行效果如下图所示:

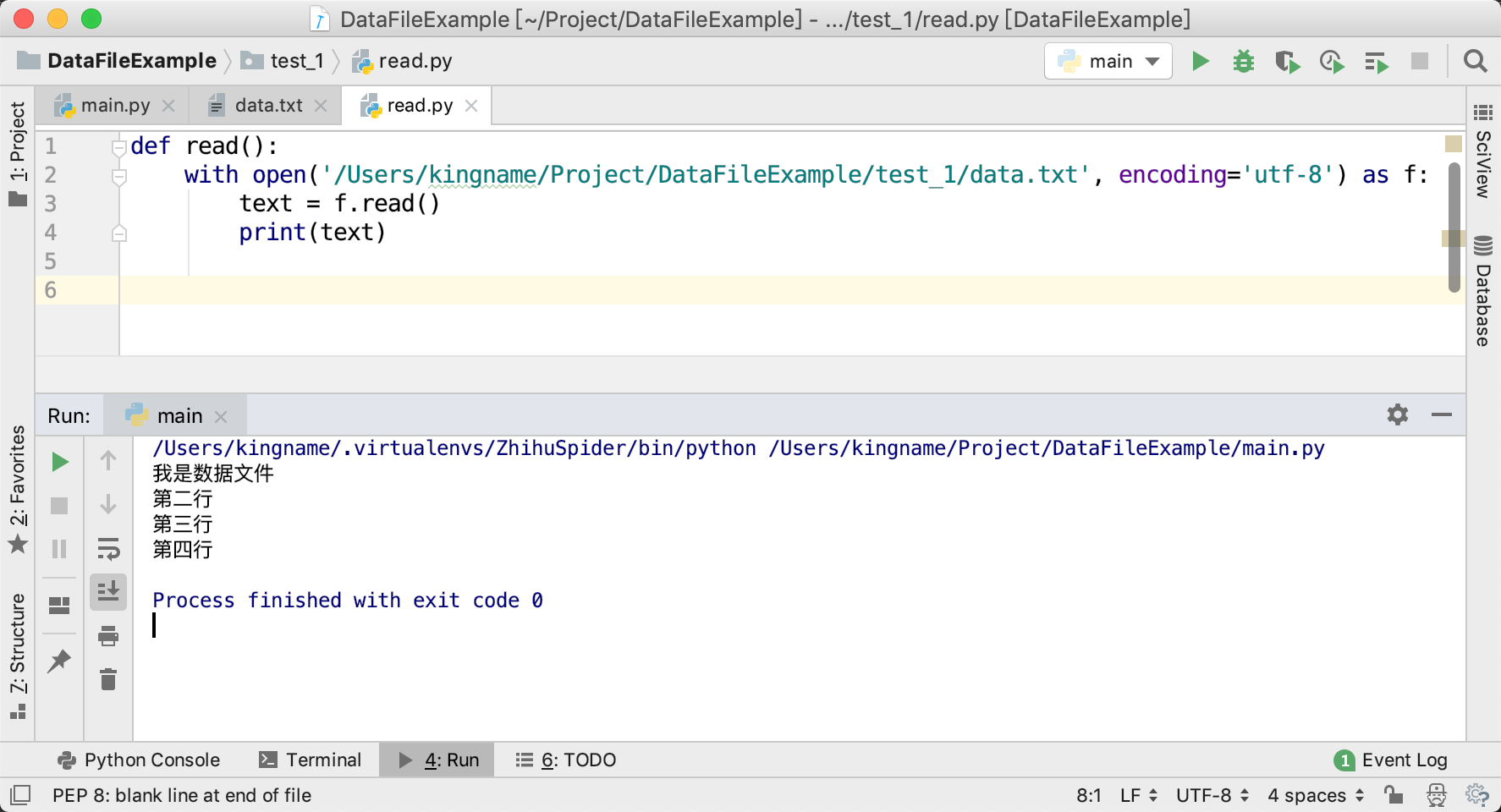
- 使用pkgutil库
1 | import pkgutil |
运行效果如下图所示:
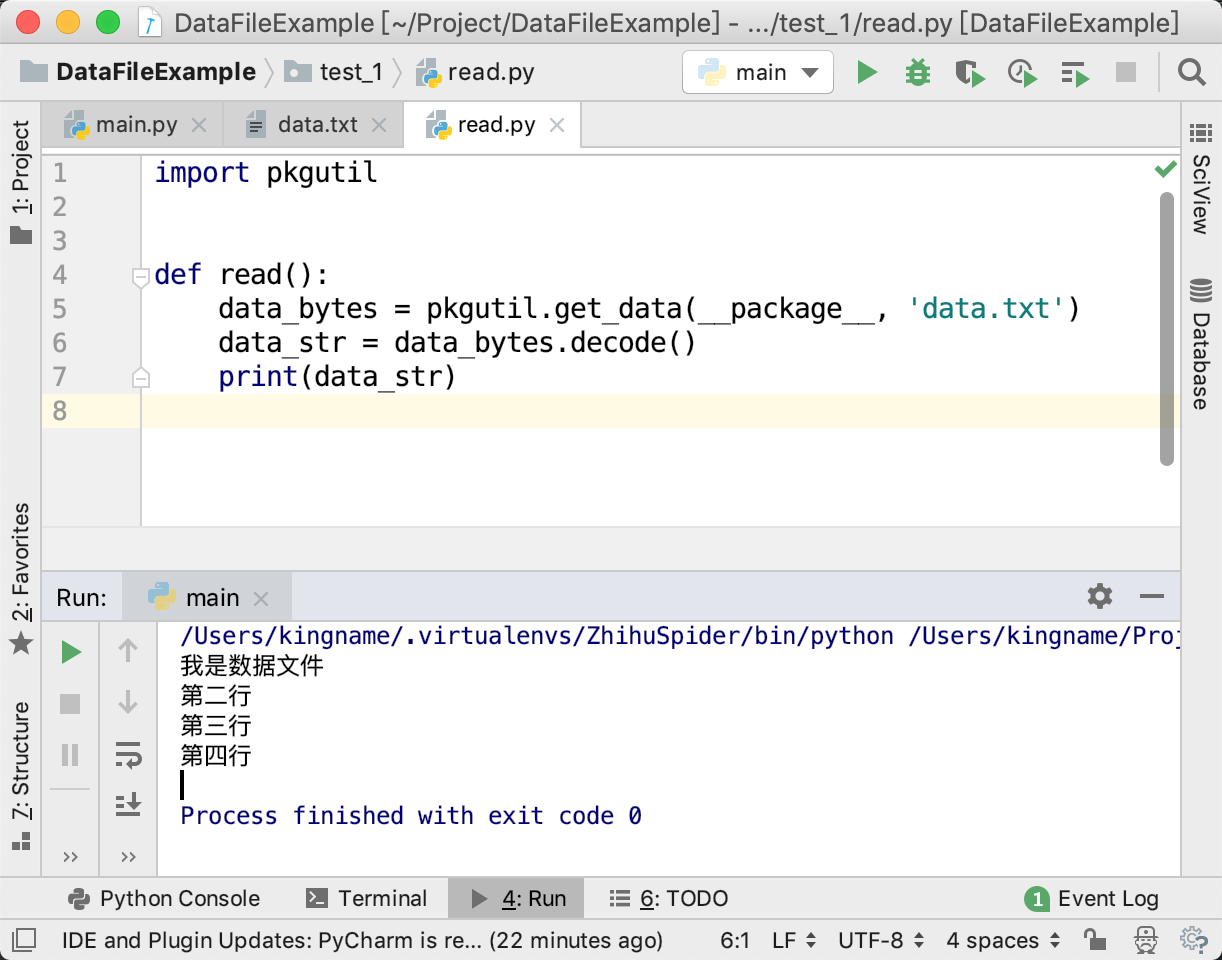
pkgutil是Python自带的用于包管理相关操作的库,pkgutil能根据包名找到包里面的数据文件,然后读取为bytes型的数据。如果数据文件内容是字符串,那么直接decode()以后就是正文内容了。
为什么pkgutil读取的数据文件是bytes型的内容而不直接是字符串类型?
这是因为并不是所有数据文件都是字符串,如果某些数据文件是二进制文件或者图片,那么以字符串方式打开就会导致报错。所以为了通用,pkgutil会以bytes型方式读入数据,这相当于open函数的“rb”读取方式。
使用pkgutil还有一个好处,就是只要知道包名就可以找到对应包下面的数据文件,数据文件并不一定要在当前包里面。
例如修改代码结构如下图所示:
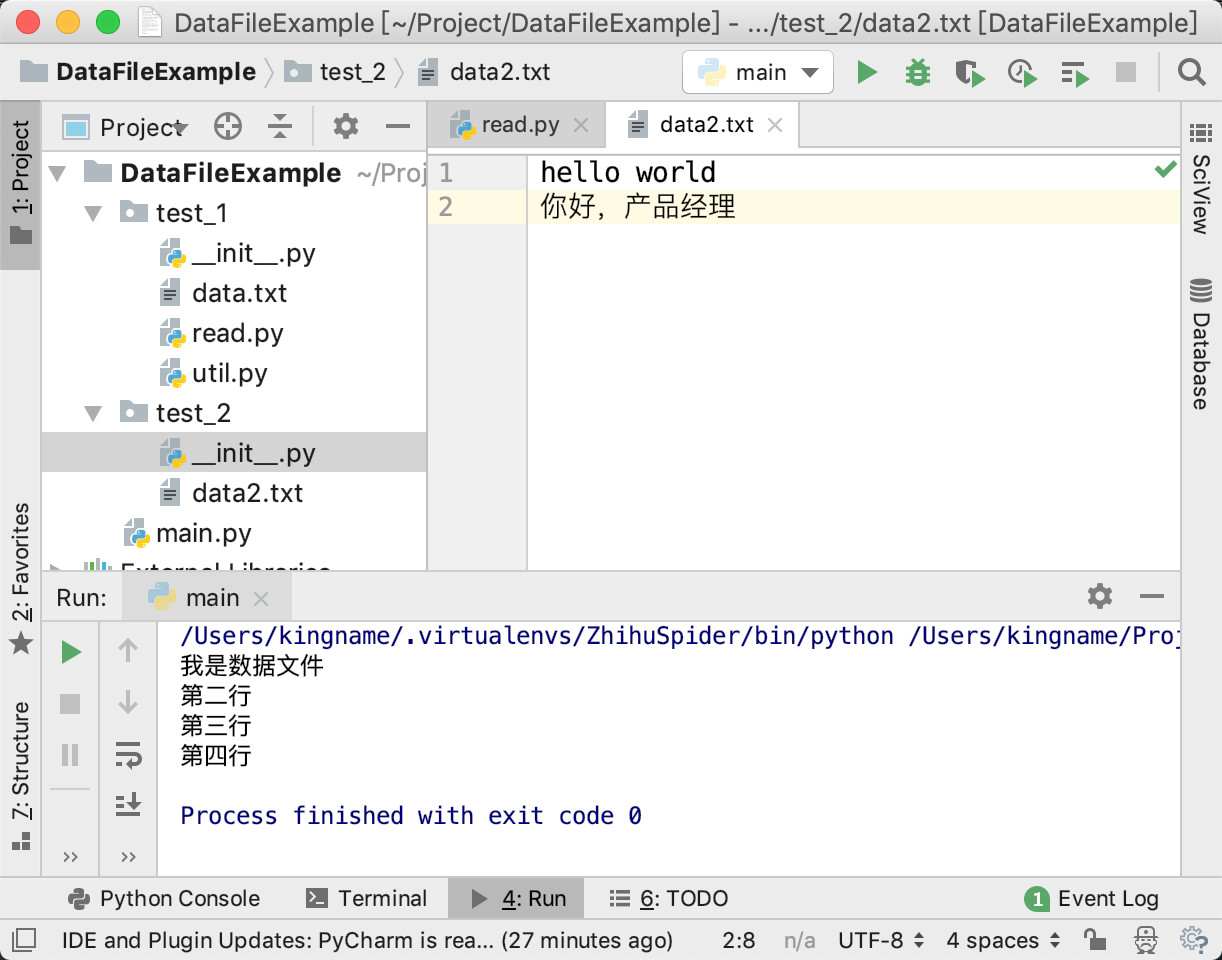
另一个包test_2里面有一个数据文件data2.txt。此时如果要在teat_1包的read.py中读取data2.txt中的内容,那么只需要修改pkgutil.get_data的第一个参数为test_2和数据文件的名字即可,运行效果如下图所示:
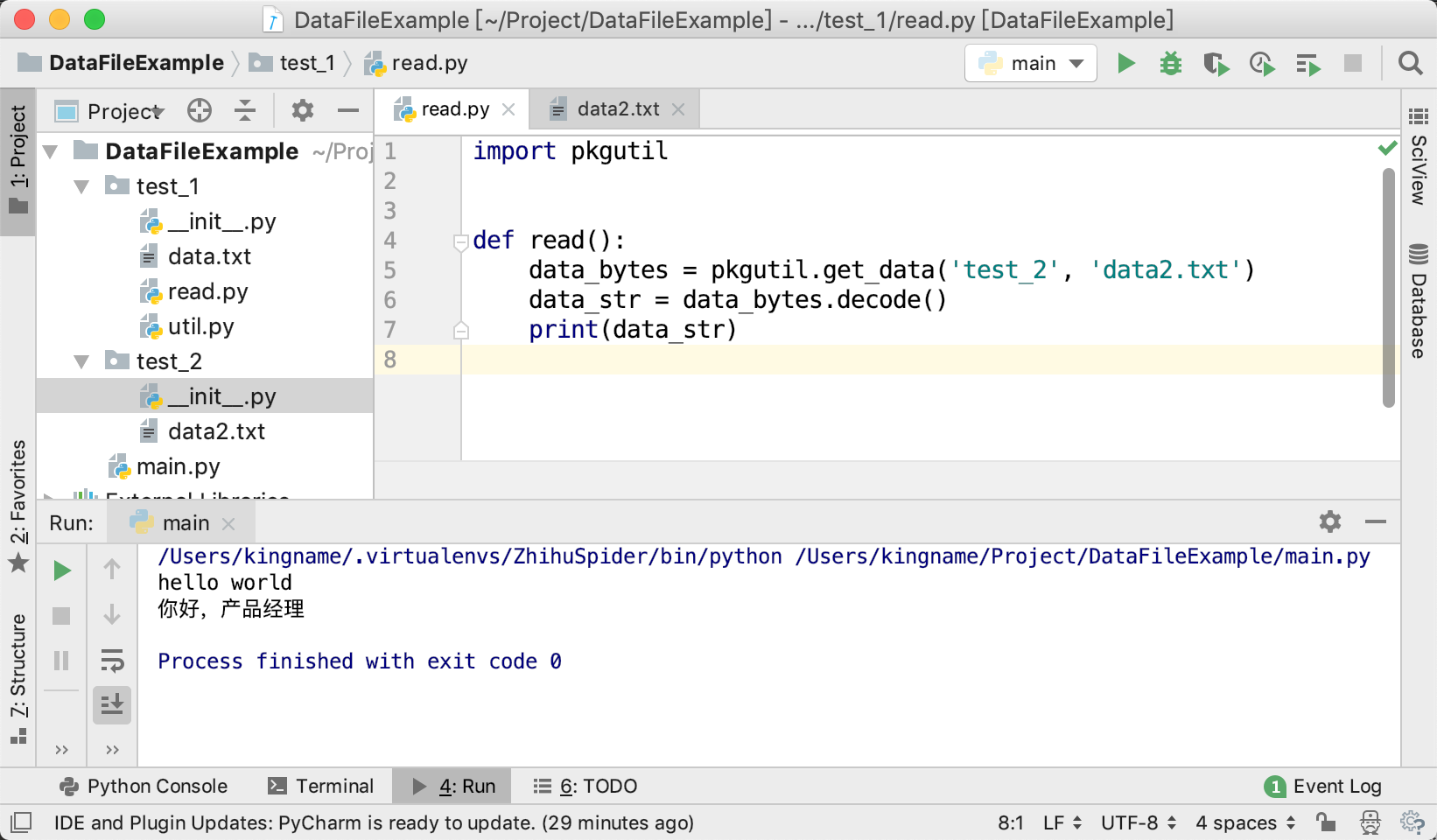
而前两种方法都不如pkgutil简单。
所以使用pkgutil可以大大简化读取包里面的数据文件的代码。