从Python源代码里面证明你的猜想
看过《Python爬虫开发 从入门到实战》的同学,应该对multiprocessing这个模块比较熟悉,在书上我使用这个模块通过几行代码实现了一个简单的多线程爬虫:
1 | import requests |
运行效果如下图所示:
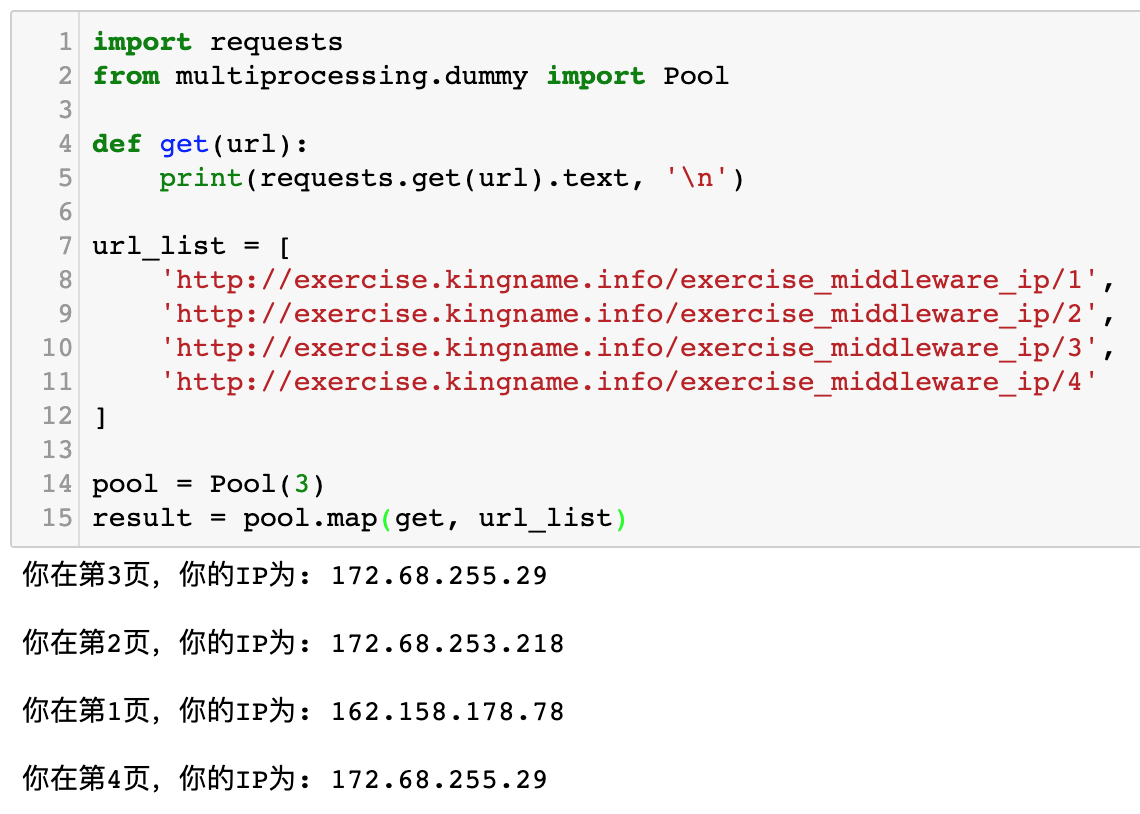
(没有看过我的书的人可能会质疑,multiprocessing不是多进程模块吗?为什么你说是多线程?看过书的读者不会有这个疑惑,因为我在书上解释过原因)
现在,你有一个函数,没有任何参数,但是仍然想让他使用多线程,于是模仿上面的代码,你这样写:
1 | import requests |
运行以后发现,什么都没有打印出来,也就是说test()函数根本没有运行。
如果你强行给函数添加一个没用的参数,结果又正常了:
1 | import requests |
运行效果如下图所示。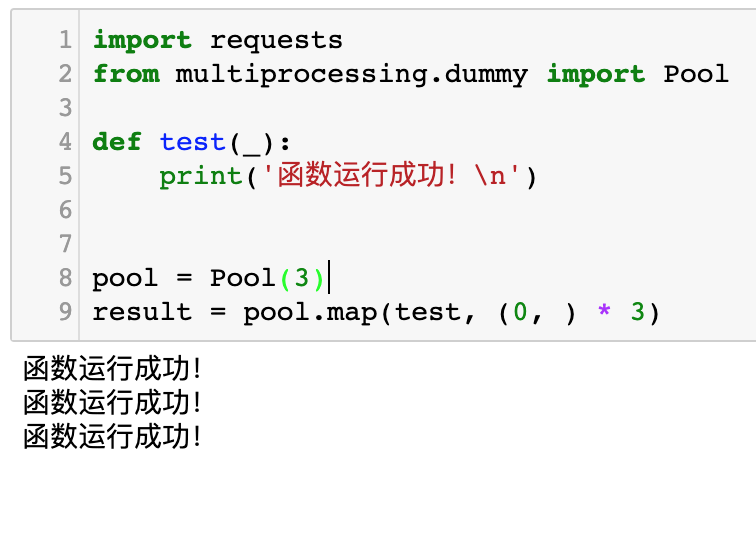
所以你隐隐觉得,如果pool.map的第二个参数是空的可迭代对象,那么函数就不会运行。
(当然,使用过Python自带的map函数的同学肯定直接就知道这一点,不过本文依然使用它来做例子,用于说明阅读源代码的方法。)
为了证明这一点,我们打开Python安装目录/lib/multiprocessing/pool.py文件,在里面找到def map(self, func, iterable, chunksize=None)这一行,如下图所示:

(本文使用Python 3.7.3作为演示,如果你的Python版本不是3.7.3,那么代码可能会有一些区别)
从代码里面可以看到,这里调用了self._map_async(),传入参数,获得返回值以后,再调用了返回值的.get()方法。
所以继续看self._map_async()方法:
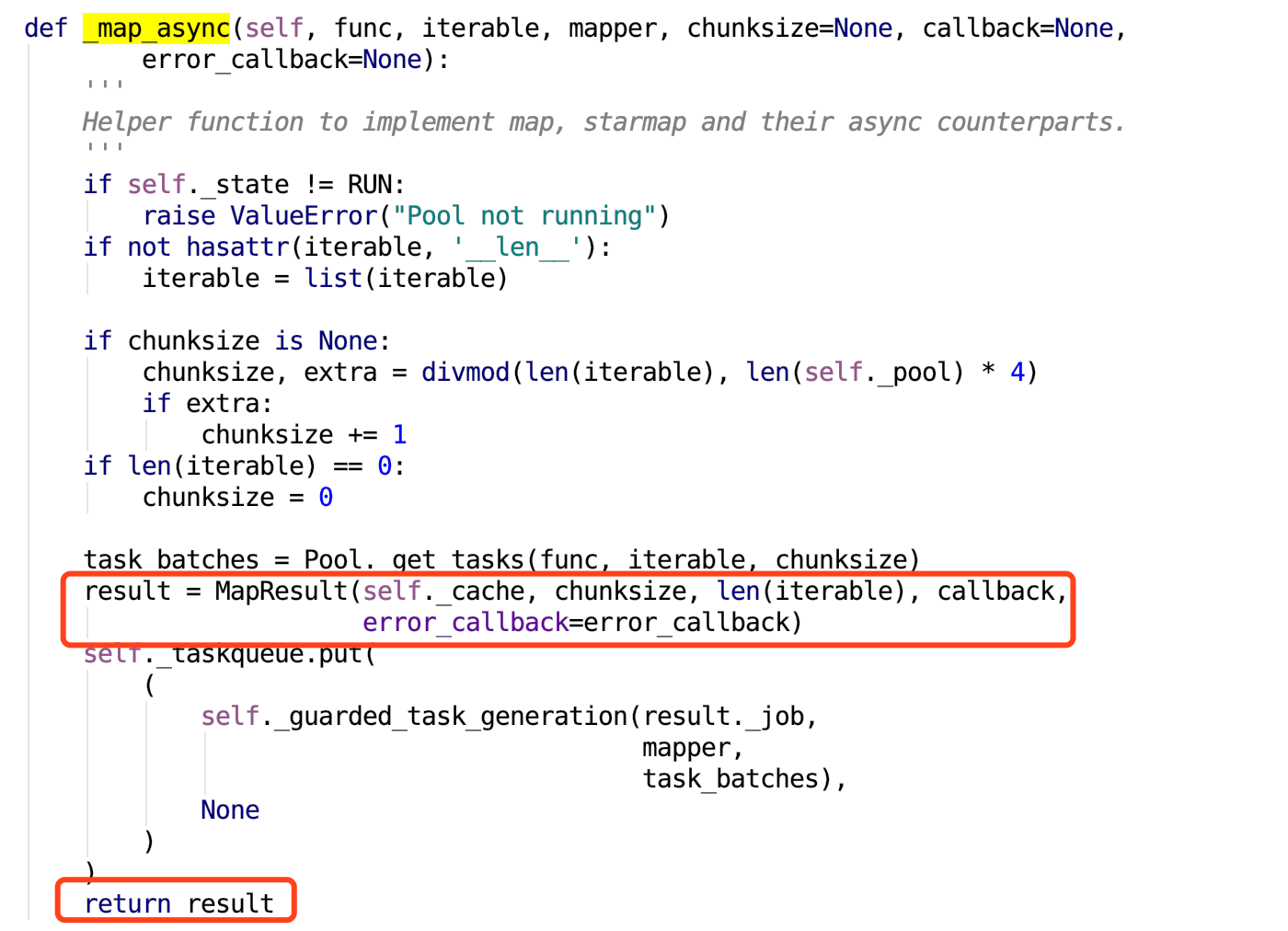
在这个方法里面,如果我们传入的可迭代对象为空,那么也就是这里的参数iterable为空。于是
1 | chunksize = 0 |
map的第一个参数,函数名被传入了下面这一行代码中:
1 | task_batches = Pool._get_tasks(func, iterable, chunksize) |
查看Pool._get_tasks这个静态方法,可以看到:

由于这里的参数it就是空的可迭代对象,size为0,所以下面这一行代码返回空元组:
1 | tuple(itertools.islice(it, size)) |
这个生成器直接就会结束,最后一行yield (func, x)根本不会执行。
再来看代码里使用MapResult类初始化了一个result对象,然后返回这个对象。
再进入到MapResult类里面,如下图所示:
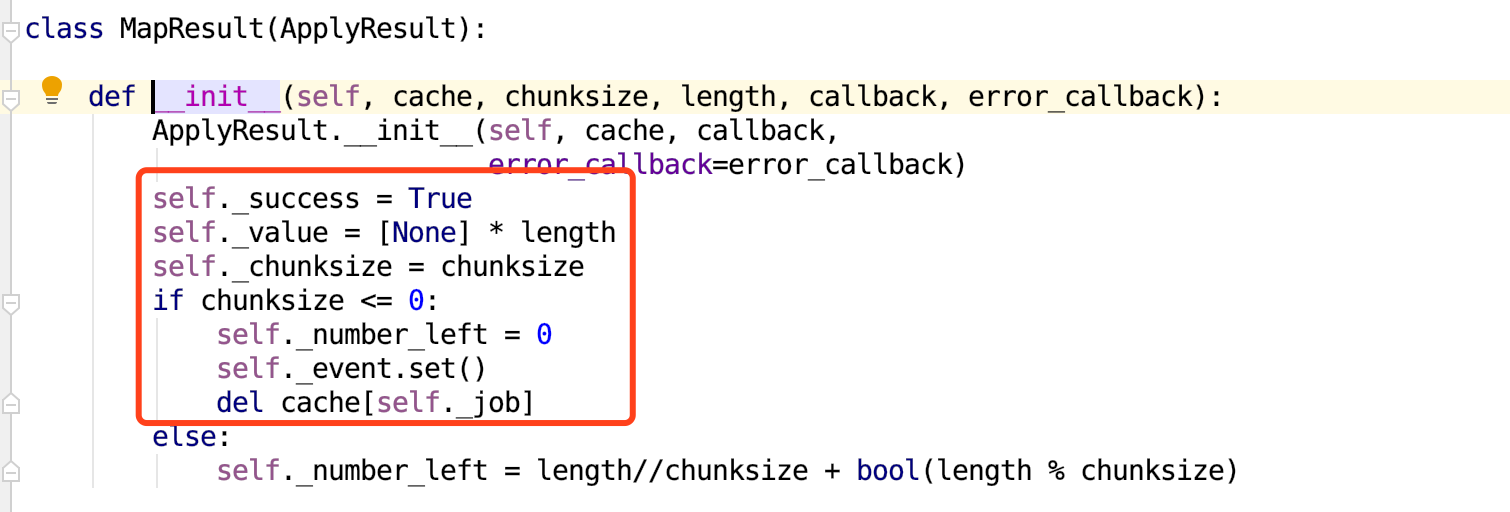
在这段__init__中,可以得到如下几个参数的值:
1 | self._success = True |
关于self._event.set()请看我的另一篇公众号:
返回的result对象的.get()方法被调用了。但是由于MapResult本身没有.get()方法,于是变为调用父类ApplyResult的.get()方法。
再进入ApplyResult里面,查看.get()方法:

由于前面调用了self._event.set(),所以这里的self.ready()结果为True,而由于self._success在上面为True,所以这里直接return self._value。也就是返回一个空的列表。
到此为止,在pool.map的第二个参数为空的可迭代对象时,所有的流程就走完了。整个过程中,没有涉及到任何调用func的过程。所以原有的函数不会被执行。
最后说说为什么在本文中我们看的是multiprocessing的Pool类里面的map方法,而不是multiprocessing.dummy的Pool类里面的map方法。
这是因为,如果我们打开Python安装路径/Lib/multiprocessing/dummy/__init__.py,我们就可以看到,它的Pool实际上返回的是一个ThreadPool对象。而这个对象的代码,实际上也在Python安装路径/Lib/multiprocessing/pool.py文件中,并且继承自Pool类。所以他们的map方法的代码是完全一样的。