GNE 预处理技术——如何移除特定标签但是保留文字到父标签
在开发新闻网页正文通用抽取器GNE的过程中,需要对目标网页的源代码进行一些预处理,从而提高正文抓取的准确性。其中之一就是把 <p>标签内部的 <span>标签中的文本,合并到<p>标签中,再删除 <span> 标签。
例如:
1 | <html> |
需要转换为:
1 | <html> |
在原来做定向爬虫的时候,这本不是什么问题,因为使用 XPath 可以直接提取所有内容:
1 | from lxml.html import fromstring |
运行效果如下图所示:
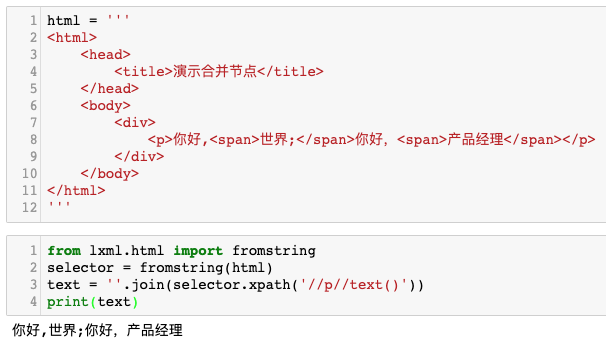
但在通用新闻抽取器里面不能这样写。因为并不是所有的<p>标签中的内容都是新闻正文。GNE 有一套算法来计算并寻找全部包含真正有效内容的<p>标签。这就要求在预处理阶段,需要把 <p>标签里面的<span>标签合并到<p>标签里面。
可能有人的第一反应是:先把 <p> 标签里面的内容提取出来,然后再把 <span> 标签里面的内容提取出来,并添加到 <p> 标签中。这不就解决问题了吗?
但实际上并没有这么简单。以上面的 HTML 代码为了,如果按照这种简单的解法,那么分别提取以后会得到如下内容:

现在问题来了,你怎么知道 <span> 标签中提取出来的这两个字符串世界, 产品经理,分别应该插入到 <p> 标签结果列表中的哪个位置?所以这种方案并不可取。
那么又有人问,能不能使用 XPath 的string关键字把 <p> 标签下面的所有文本直接提取出来,再作处理呢?这样不就可以忽略标签差异了吗?在上面的 html 代码中,这种方案是可行的:
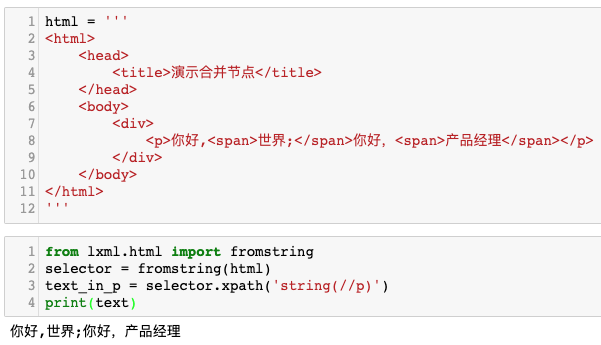
但是,这种方案不能应用到 GNE 中。这是由于这种做法,会无差别移除所有的标签。但是<p> 标签下面的<a>标签是有用的,它在用于过滤导航栏或者推荐新闻这种类型的干扰内容中会起到很大的作用。所以<a>标签必需保留。
那么,本文标题提到的问题:如何移除指定标签,但是保留它的文本,合并到父标签中?应该如何解决呢?
实际上,这个问题在 lxml 中有现成的办法解决,他就是etree.strip_tags
使用方法如下:
1 | from lxml.html import etree |
在本文的例子中,解决方案如下:
1 | from lxml.html import fromstring, etree |
运行效果如下图所示:

需要注意的是,etree.strip_tags()会直接修改原始Dom 树,不需要返回修改结果。
GNE 的其他关键技术,将会在接下来的文章中逐一放出,你也可以访问GNE 的 Github 主页:https://github.com/kingname/GeneralNewsExtractor,提前阅读项目源代码。