在 Jupyter 中如何重新导入特定的 Python 文件?
Jupyter 是数据分析领域非常有名的开发环境,使用 Jupyter 写数据分析相关的代码会大大节约开发时间。
设想这样一个场景:别的部门的同事传给你一个数据分析的模块,用于实现对数据的高级分析。模块里面有上百个函数。
如果直接写 Python 文件来调用数据分析模块,那么使用方法非常简单:
1 | from analyze import FathersAnalyzer |
现在,你需要使用 Jupyter 来调用这个分析模块。你应该怎么在 Jupyter里面调用?
你可能会觉得,这还不简单吗?直接把这个模块的代码与 Jupyter Notebook 的 .ipynb 文件放在一起,然后在 Jupyter 里面像导入普通模块那样导入即可,如下图所示:
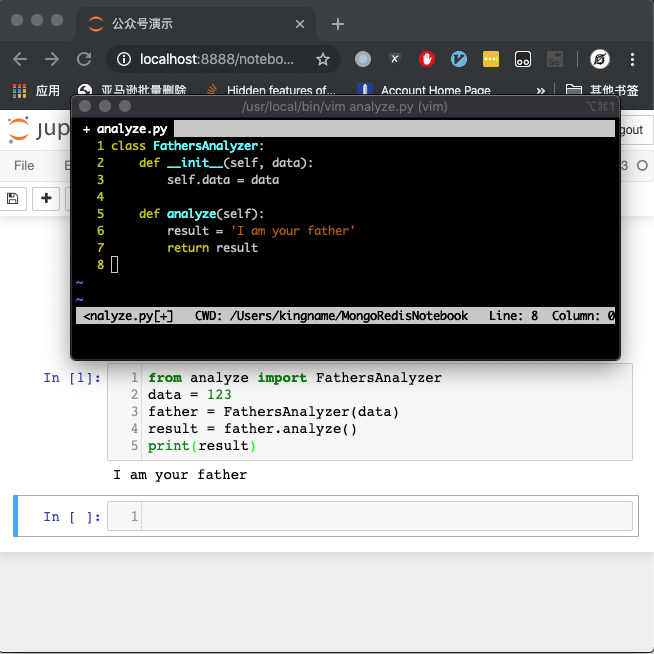
那么现在问题来了,如果我此时修改了 analyze.py文件,会出现什么情况呢?
我们改一下看看,如下图所示。
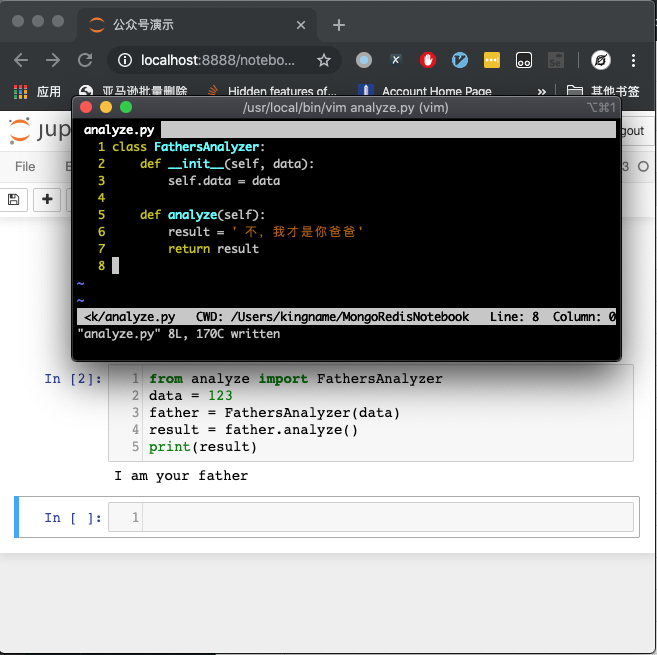
重新运行这个 Cell 中的代码,代码中虽然有from analyze import FathersAnalyzer,看起来像是重新导入了这个模块,但是运行却发现,它运行的是修改之前的代码。
这是因为,一个 Jupyter Notebook 中的所有代码,都是在同一个运行时中运行的代码,当你多次导入同一个模块时,Python 的包管理机制会自动忽略后面的导入,始终只使用第一次导入的结果(所以使用这种方式也可以实现单例模式)。
那么如果我在修改了被导入的包以后,想重新导入它怎么办呢?有3种方案:
- 重启整个 Notebook。但这样会导致当前运行时里面的所有变量全部丢失。
- 使用
importlib:
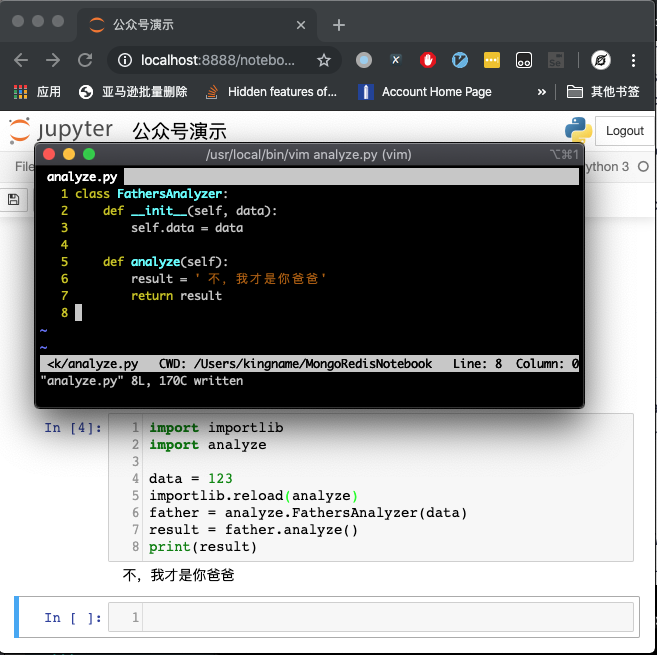
但这种方案弊端也很明显——除非你按顺序运行每一个 Cell,否则,你的代码会变成下图这样:
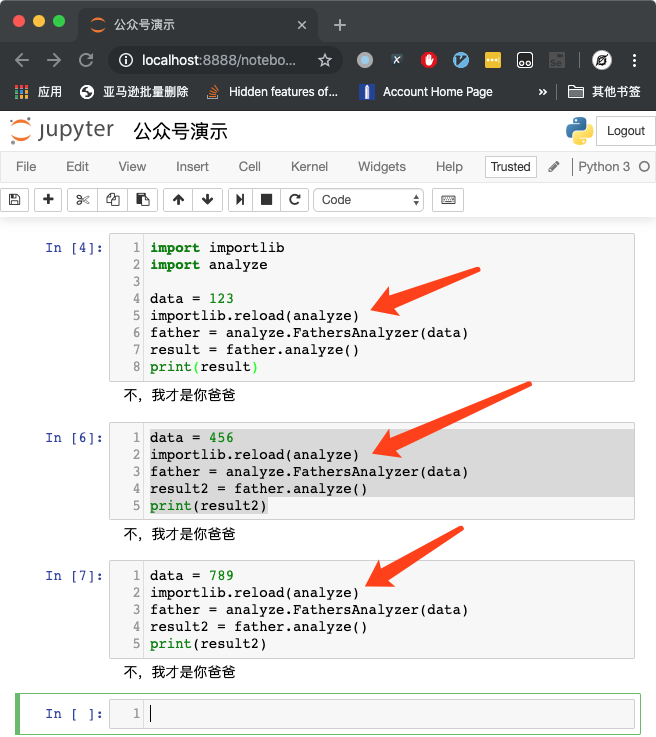
在每一个 Cell 里面都需要 重新加载一次分析模块,否则,很有可能在你单独运行某一个 Cell 的时候,用的是老的代码,就会导致难以察觉的 bug。
- 使用 Jupyter 自带的
%autoreload:
1 | %load_ext autoreload |
运行效果如下图所示:

其中关键的代码有三行:
1 | %load_ext autoreload |
这三行代码只有在 Jupyter 里面才能正常运行,在 普通的.py 文件里面这样写会报错。它们的作用是:第1行启动autoreload机制。第2行,设置自动加载通过%aimport导入的模块。第3行使用%aimport导入analyze模块。
这样写以后,任意一个 Cell 运行,所有被%aimport导入的模块都会被重新加载一次。从而让你每次都使用最新的代码。
当然,你还可以进一步偷懒,把特殊代码缩减为2行:
1 | %load_ext autoreload |
%autoreload后面的参数被设置为2时,每次运行任意一个 Cell,都会自动重新加载所有import xxx导入的模块。这样做的代价是,运行会慢一些。