在 Python 正则表达式模块中逃跑(escape
在编程语言中,有常见的符号被赋予了特殊的意义,例如小数点.,在正则表达式里面表示任意一个非换行符的字符;小于号<在 html 中表示标签。
但有时候,我们只想让这些符号表示它本来的意思,不想让它的特殊意义表露出来,应该怎么办?
我们知道,在正则表达式中可以使用反斜杠来让一个特殊符号变成普通符号,例如\.表示普通的小数点,\$表示普通的美元符号。
现在我有一个列表keywords_list,里面是100个字符串,我想判断是否有任意一个字符串在某个给定的句子中。如果用 for 循环一个一个去检查,效率非常低。于是可以考虑使用正则表达式:
1 | import re |
但假设 keywords_list列表中有如下的字符串:
1 | keywords_list = ['4.5', '+{d', '***'] |
那么我们使用正则表达式就会导致报错,如下图所示。
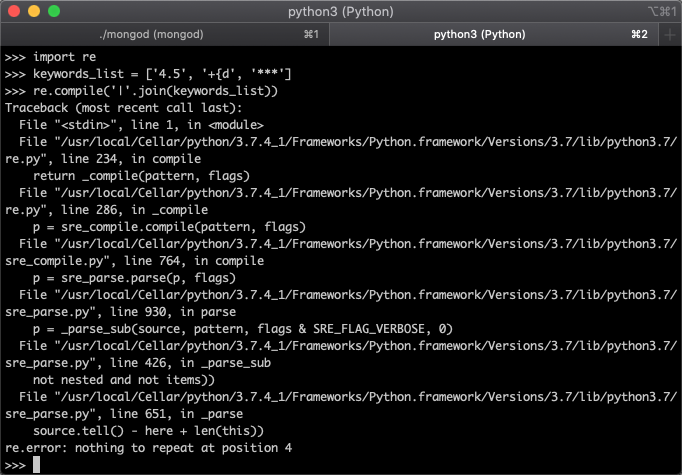
这是因为这些字符串里面存在特殊的符号,这些符号在正则表达式里面有特殊的意义,有使用的规范,不能随意使用。
但是,keywords_list里面有各种各样的特殊符号,难道要一个一个取出来,逐一x.replace('+', '\+').replace('.', '\.').replace('*', '\*')...?
当然不用,Python 的正则表达式模块已经帮你想好了解决办法,使用re.escape就能自动处理所有的特殊符号了!
它的用法如下:
1 | import re |
运行效果如下图所示:
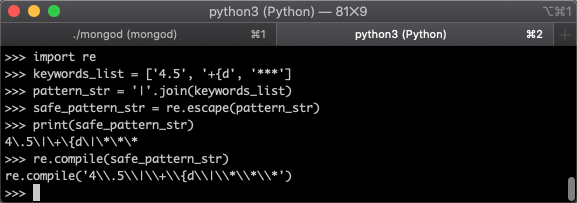
解决问题。