拒绝想当然,不看文档导致GNE 的隐秘 bug
GNE上线4天,已经有很多朋友通过它来编写自己的新闻类网页通用爬虫。
今天有一个用户来跟我反馈,GNE 0.1.4版本在提取澎湃新闻时,只能提取一小部分的内容。
一开始我以为是提取算法有问题,Debug 了半天,最后才发现,是新闻正文在预处理的时候,就被提前删除了!
为了解释这个问题,我们用一小段 HTML 代码来还原当时的场景:
1 | h = ''' |
阅读过 GNE 源代码的朋友都知道,GNE 会在预处理阶段尽可能移除没什么用的 HTML 标签。例如上面这段代码中的两行<p class="con" />都属于会干扰提取结果,且对提取没有任何帮助的标签。
于是我们使用 lxml 库的方法来移除它:
1 | from lxml.html import fromstring |
根据想当然的理论:
- 找到
<p class="con" />标签 - 找到它的父标签
- 从父标签里面把这两个无效标签移除掉
整个过程看起来没有问题,并且预期移除以后的 HTML 应该是这样的:
1 | h = ''' |
但实际上,现实情况与想当然的情况自然不一样。真正的输出结果如下图所示:
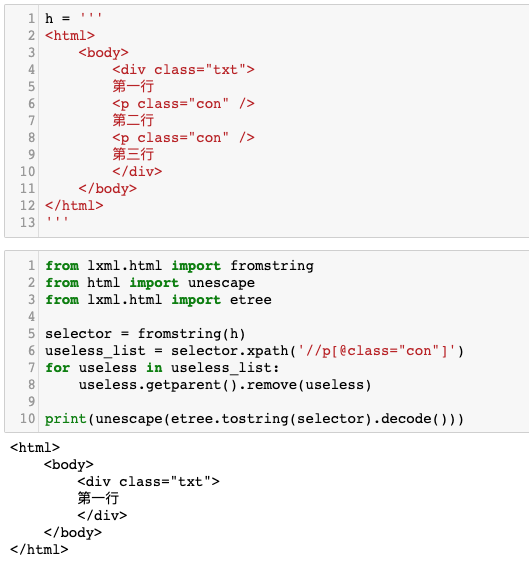
<div class="txt">这个标签下面的text()有三行,分别为第一行、第二行、第三行。但是使用上面的代码移除时,第二行与第三行都一并被删除了。
这是因为,这就是ElementTree.remove这个方法的行为。它不仅会移除这个节点,还会移除这个节点父节点的 text()中,位于这个节点后面的所有内容。
所以,正常的做法应该是直接调用要被移除这个节点的.drop_tag()方法。我们修改一下上面的代码:
1 | from lxml.html import fromstring |
运行效果如下图所示。
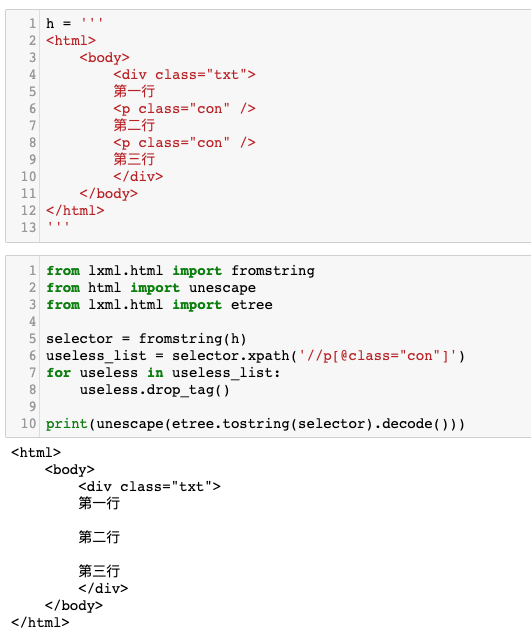
成功达到了我们想要的目的。
GNE 已经更新了版本,修复了这个 bug。使用 GNE 的同学请升级到0.1.5以上版本:
1 | pip install --upgrade gne |