剖析灵魂,为什么aiohttp默认的写法那么慢?
在上一篇文章中,我们提到了aiohttp官方文档中的默认写法速度与requests单线程请求没有什么区别,需要通过使用asyncio.wait来加速aiohttp的请求。今天我们来探讨一下这背后的原因。
我们使用一个可以通过URL设定返回延迟的网站来进行测试,网址为:http://httpbin.org/delay/5。当delay后面的数字为5时,表示请求这个网址以后,要等5秒才会收到返回;当delay后面的数字为3时,表示请求这个网址以后,要等3秒才会收到返回。大家可以在浏览器上面输入这个网址测试看看。
现在我们写一段简单的aiohttp代码来进行测试:
1 | import asyncio |
注意,如果你的Python 版本大于等于3.7,那么你可以直接使用asyncio.run来运行一个协程,而不需要像昨天那样先创建一个事件循环再运行。
运行效果如下图所示:
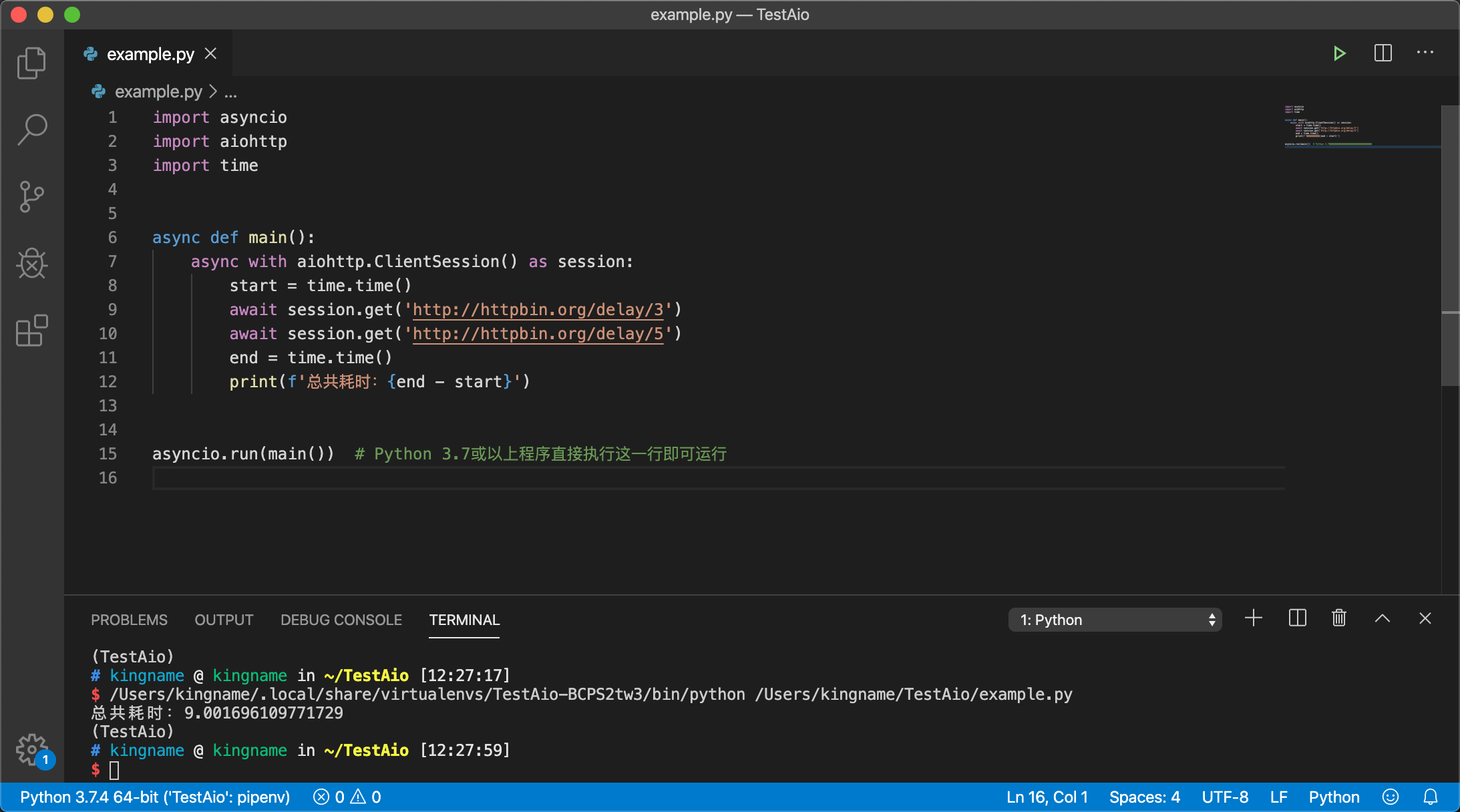
可以看到,运行时间大于8秒钟,也就是说,这段代码,是先请求第一个3秒的网址,等它运行完成以后,再请求第二个5秒的网址,他们根本就没有并行!
按照我们之前的认识,协程在网络 IO 等待的时候,可以交出控制权,当 aiohttp 请求第一个3秒网址,等待返回的时候,应该就可以立刻请求第二个5秒的网址。在等待5秒网址返回的过程中,又去检查第一个3秒请求是否结束了。直到3秒请求已经返回了结果,再等待5秒的请求。
那为什么上面这段代码,并没有按这段逻辑来走?
这是因为,协程虽然可以充分利用网络 IO 的等待时间,但它并不会自动这么做。而是需要你把它加入到调度器里面。
能被 await的对象有3种:协程、Task对象、future 对象。
当你await 协程对象时,它并没有被加入到调度器中,所以它依然是串行执行的。
但 Task 对象会被自动加入到调度器中,所以 Task 对象能够并发执行。
要创建一个 Task 对象非常简单:
1 | asyncio.create_task(协程) #python 3.7或以上版本的写法 |
所以我们来稍稍修改一下代码:
1 | import asyncio |
运行效果如下图所示:
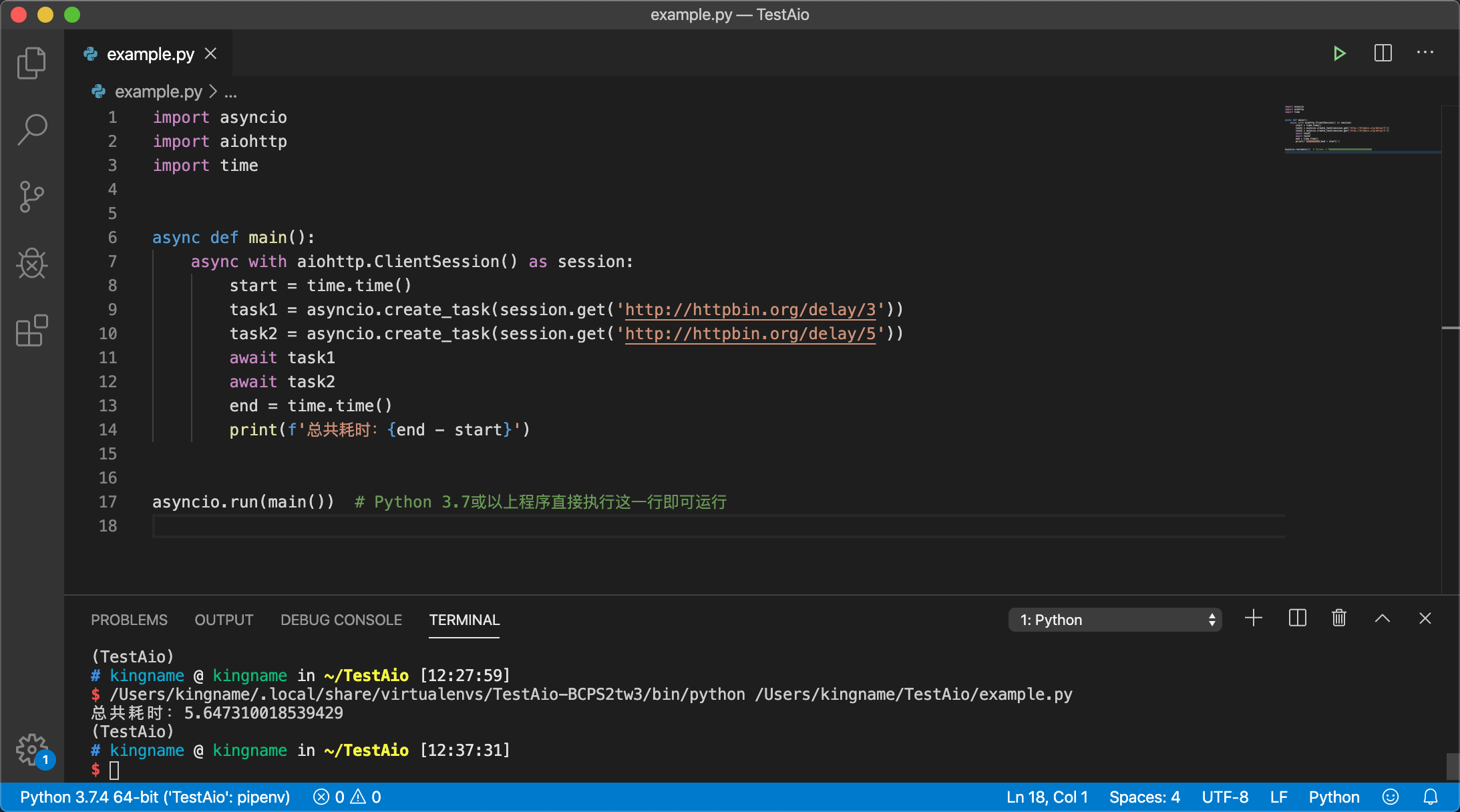
可以看到,现在请求两个网址的时间加到一起,只比5秒多一点,说明确实已经实现了并发请求的效果。至于这多出来的一点点时间,是因为协程之间切换控制权导致的。
那么为什么我们把很多协程放进一个 列表里面,然后把列表放进 asyncio.wait里面,也能实现并行呢?这是因为,asyncio.wait帮我们做了创建 Task 的任务。这一点我们可以在Python 的官方文档中看到原话:
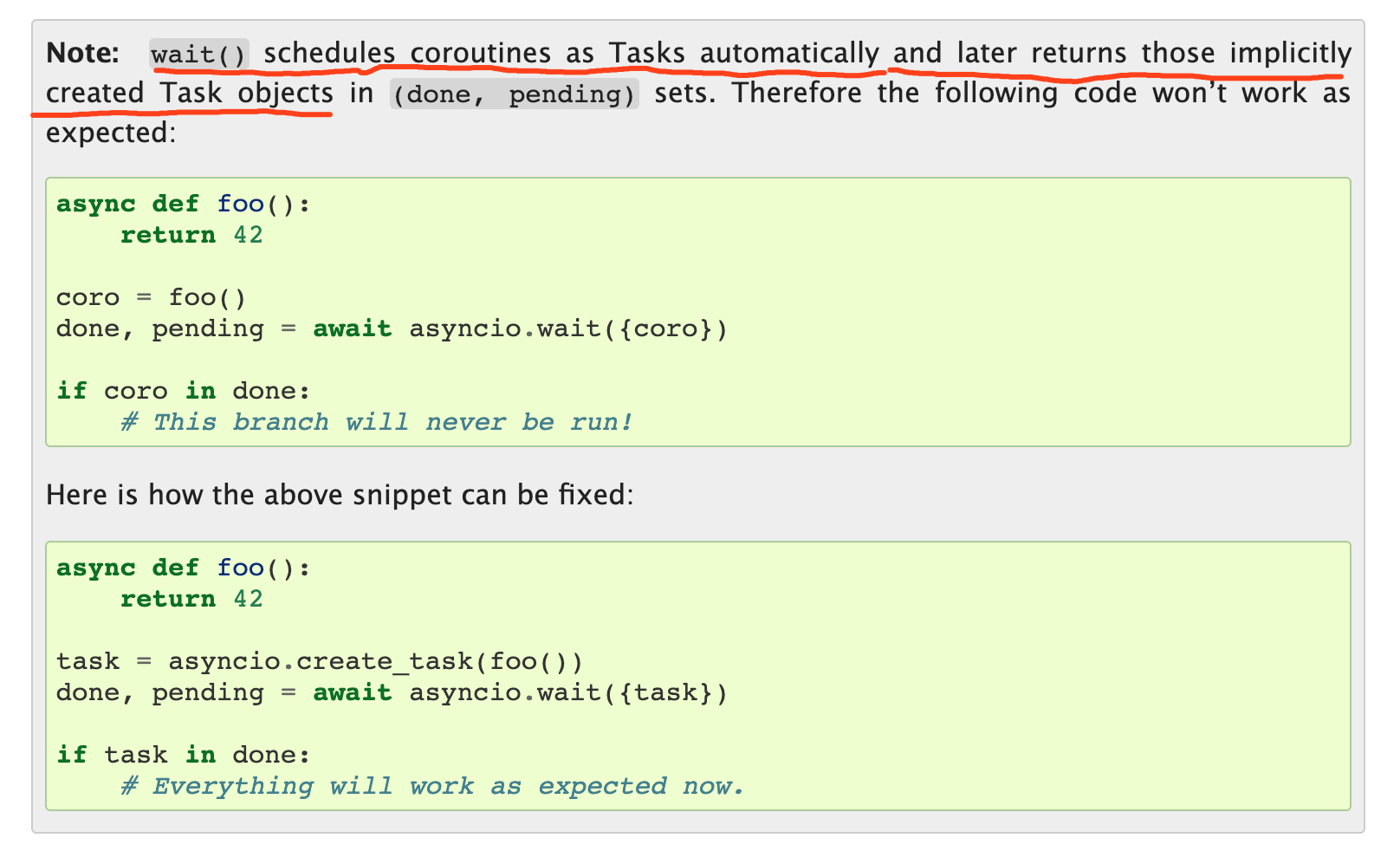
同理,当你把协程传入asyncio.gather时,这些协程也会被当做Task 来调度:

回到我们昨天的问题,我们不用asyncio.wait也不用asyncio.Queue让爬虫并发起来:
1 | import asyncio |
运行效果如下图所示:
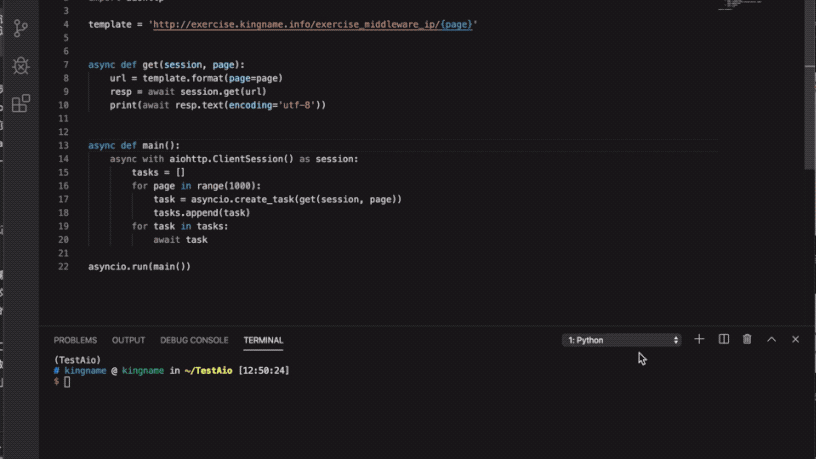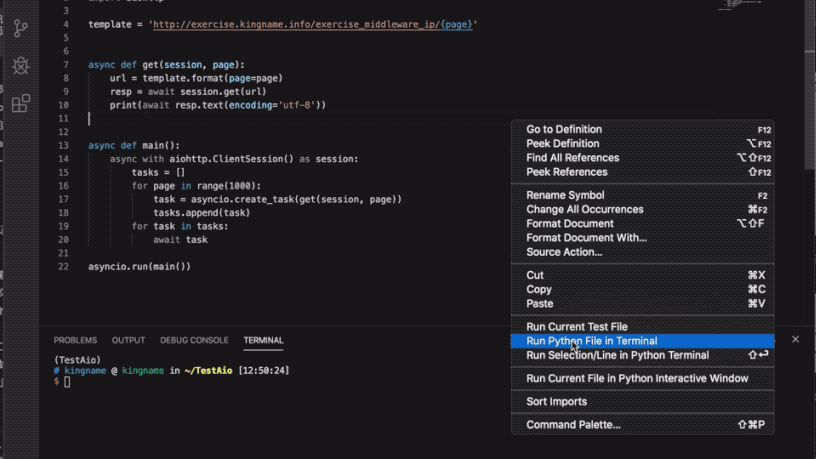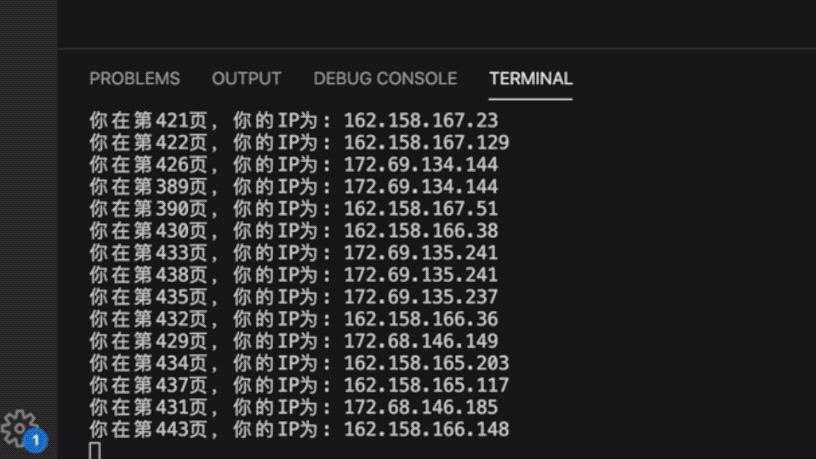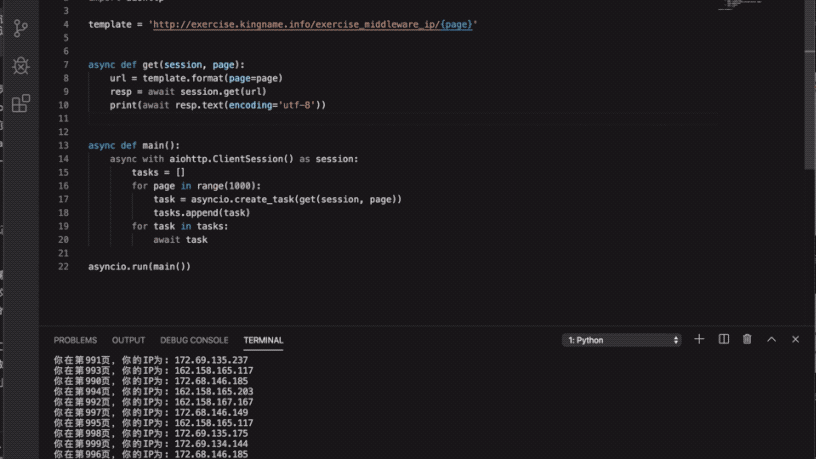
但你需要注意一点,创建 Task 与await Task是分开执行的:
1 | tasks = [] |
你不能写成下面这样:
1 | for task in range(1000): |
这是因为,创建Task 的时候会自动把它加入到调度队列里面,然后await Task的时候执行调度。上面这样写,会导致每一个 Task 被分批调度,一个 Task 在等待网络 IO 的时候,没有办法切换到第二个 Task,所以最终又会降级成串行请求。