一日一技:在LangChain中使用Azure OpenAI Embedding服务
如果大家深入使用过ChatGPT的API,或者用过听说过AutoGPT,那么可能会知道,它背后所依赖的语言框架LangChain。LangChain能够让大语言模型具有访问互联网的能力,以及与其他各种API互动交互,甚至是执行系统命令的能力。
ChatGPT的prompt支持的Token数量是有限的,但是使用LangChain,能够很容易实现ChatPDF/ChatDoc的效果。即使一段文本有几百万字,也能让ChatGPT对其中的内容进行总结,也能让你针对文本中的内容进行提问。
Question Answering over Docs这是LangChain官方文档给出的示例,如果你使用的是OpenAI官方的API,你只需要复制粘贴上面的代码,就可以实现针对大文本进行提问。
如果你使用的是Azure OpenAI提供的接口,那就比较麻烦,需要多一些设置。我们来看一下我在使用过程中所踩的坑。
我们首先复制如下4行代码:
1 | from langchain.document_loaders import TextLoader |
其中的article.txt,就是随便找了一篇我博客的文章,如下图所示:
现在直接运行肯定是会报错的,因为我们还没有配置API的相关信息:

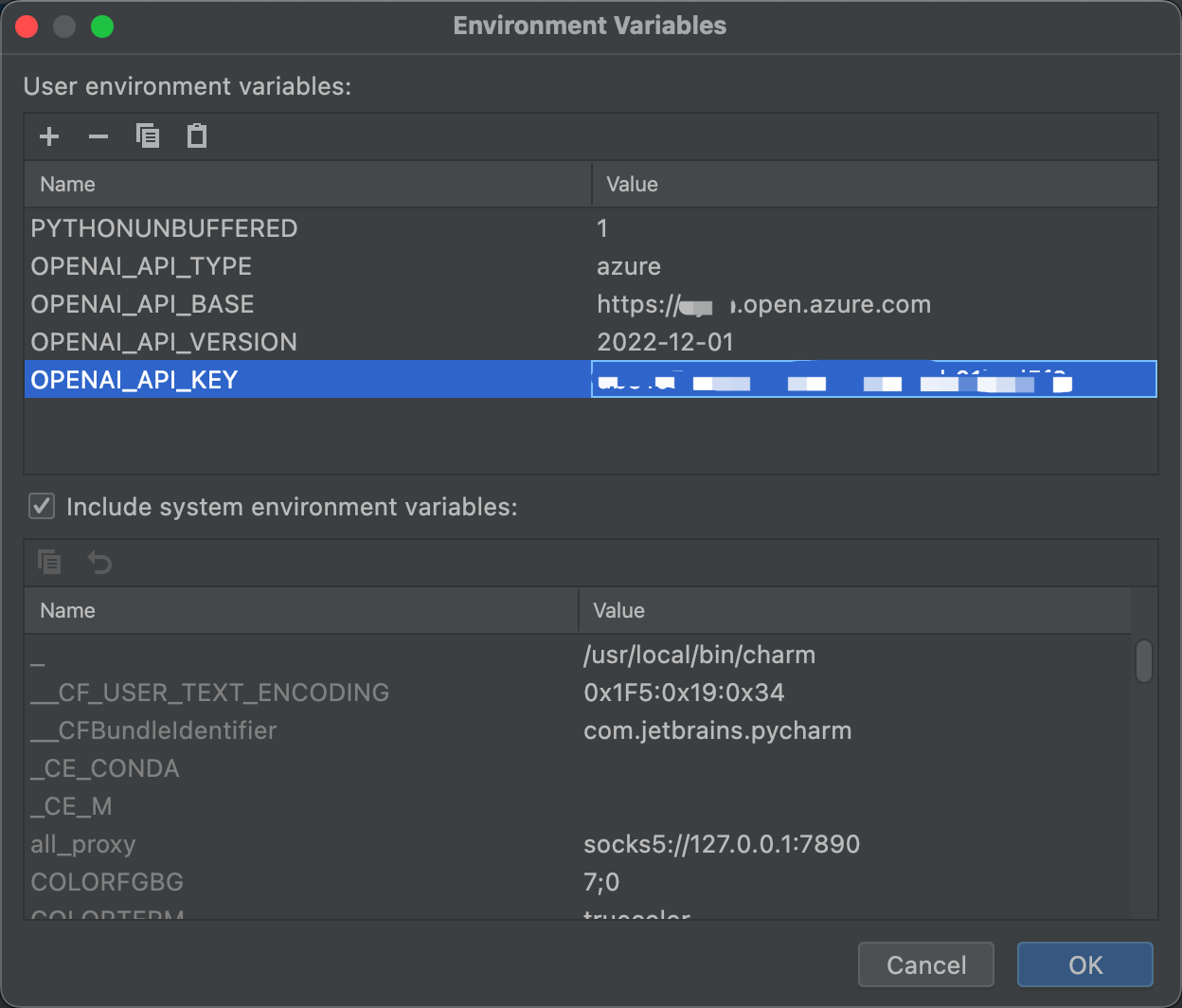
由于我们使用的是微软Azure OpenAI提供的接口,因此通过环境变量设置接口信息时,需要额外设置一些参数:
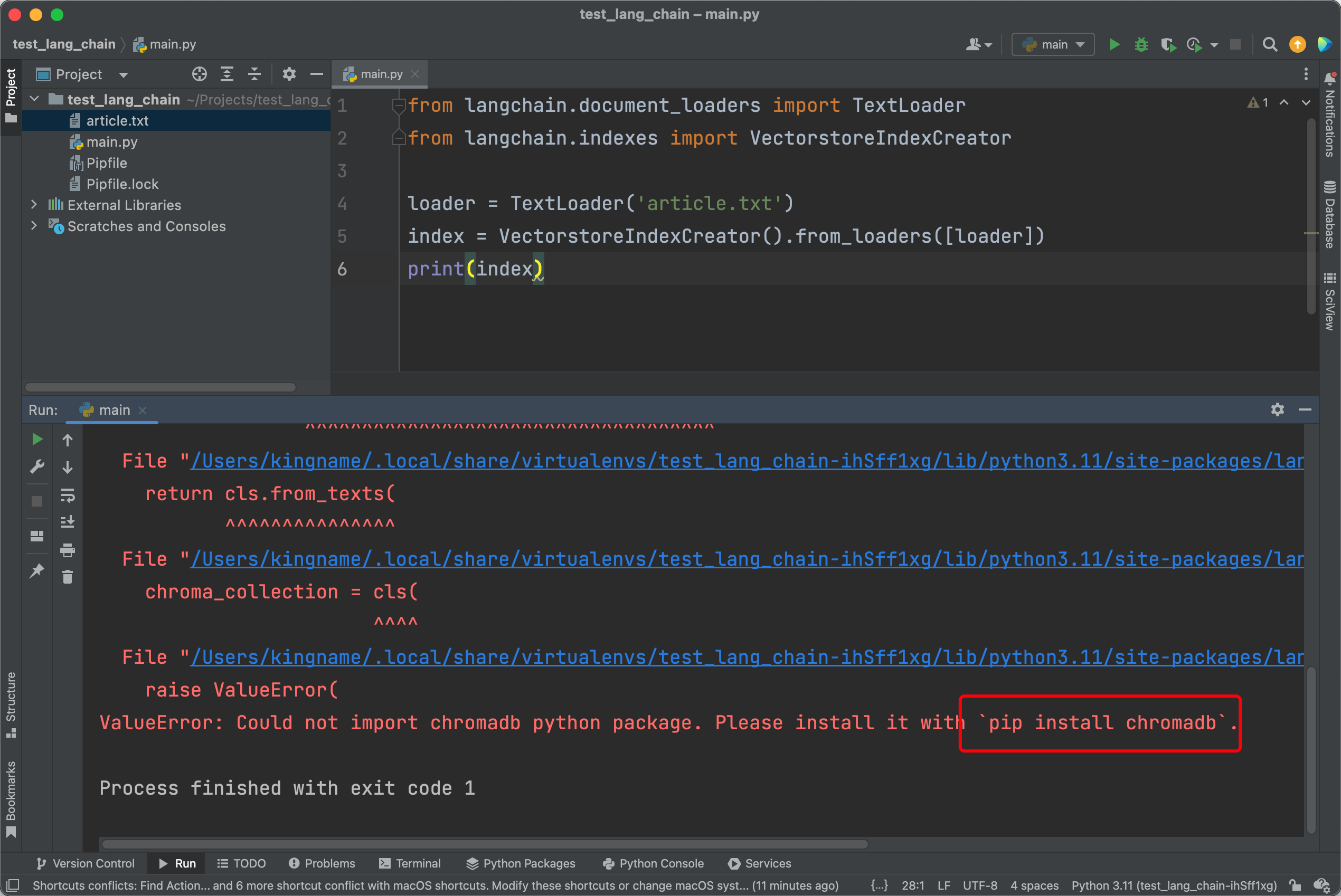
设置完成以后,再次运行,会发现依然报错。说明它擅自使用chromadb作为向量数据库,甚至都不给我选择的机会。
按它的要求,安装一下这个chromadb,再次运行,发现还是报错:openai.error.InvalidRequestError: Resource not found。之所以会出现这种情况,是因为在LangChain的源代码中,代码会走到langchain.embeddings.openai.OpenAIEmbeddings._get_len_safe_embeddings这个位置,在如下图所示的地方:
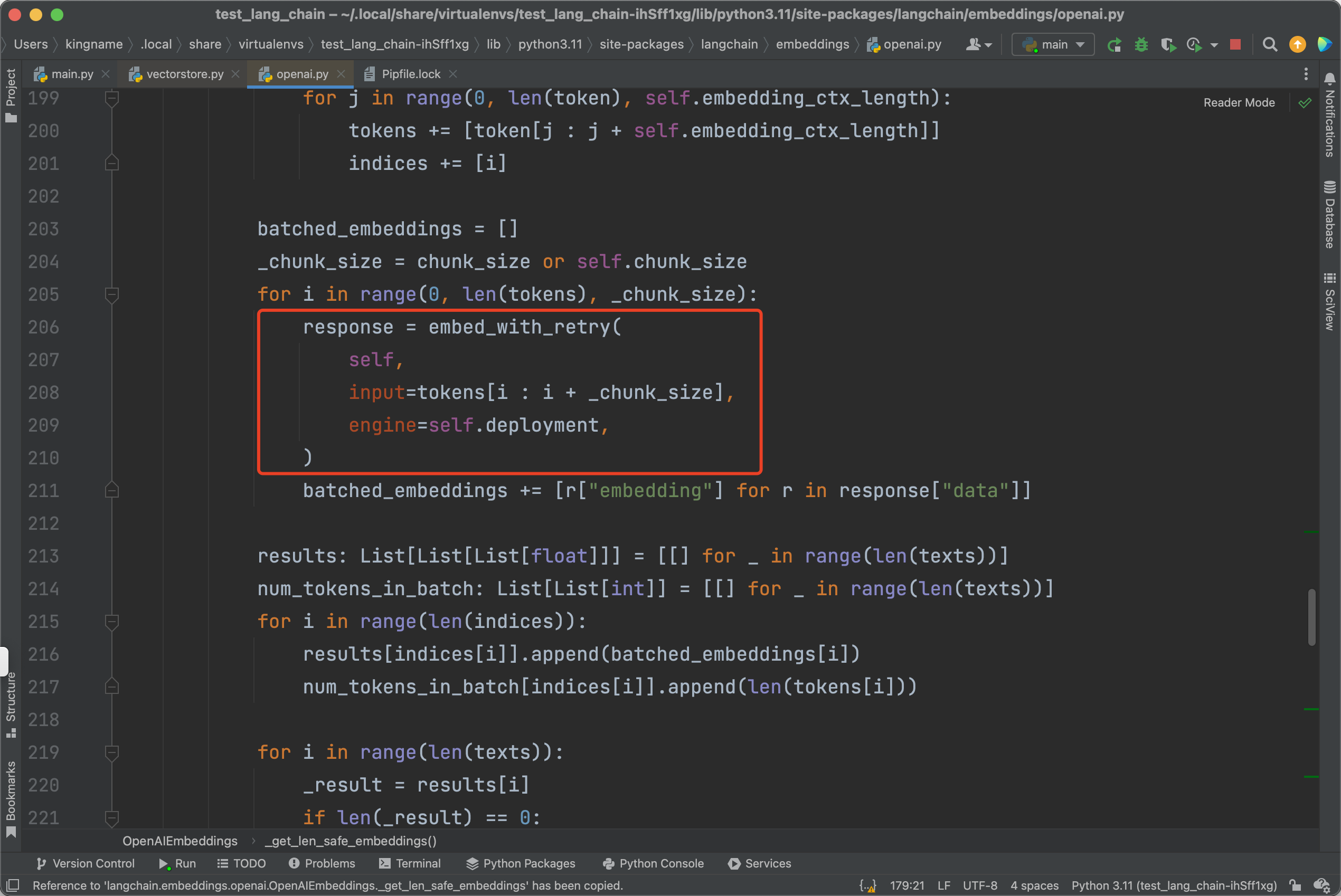
本来应该再传入参数deployment、api_type和api_version。但是这里都漏掉了。导致里面的代码始终会以OpenAI官方的接口来请求URL,所以会找不到。
即便你修改源代码,在这里加上了这三个参数,你会发现还是有问题,继续报如下错误:
1 | openai.error.InvalidRequestError: Too many inputs. The max number of inputs is 1. We hope to increase the number of inputs per request soon. Please contact us through an Azure support request at: https://go.microsoft.com/fwlink/?linkid=2213926 for further questions. |
这是因为Azure OpenAI服务提供的embedding模型,并发请求只有1.而在LangChain会以一个比较高的并发去请求,所以会报这个错误。
不要在去源代码上修改了。我们回到最开始的代码:
1 | index = VectorstoreIndexCreator().from_loaders([loader]) |
来看一下VectorstoreIndexCreator这个类它的实现方式:
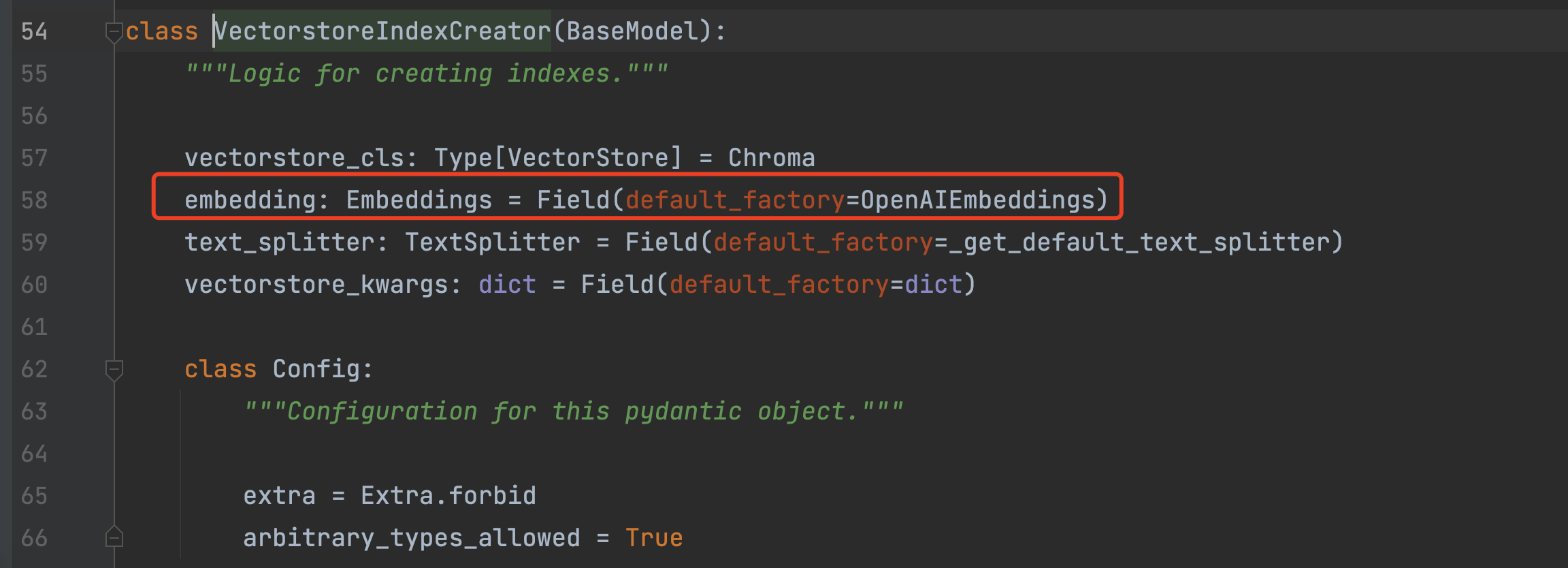
可以看到,这个类继承了pydantic.BaseModel,那就简单了。我们可以直接在初始化VectorstoreIndexCreator 时,传入embedding参数。如下图所示:
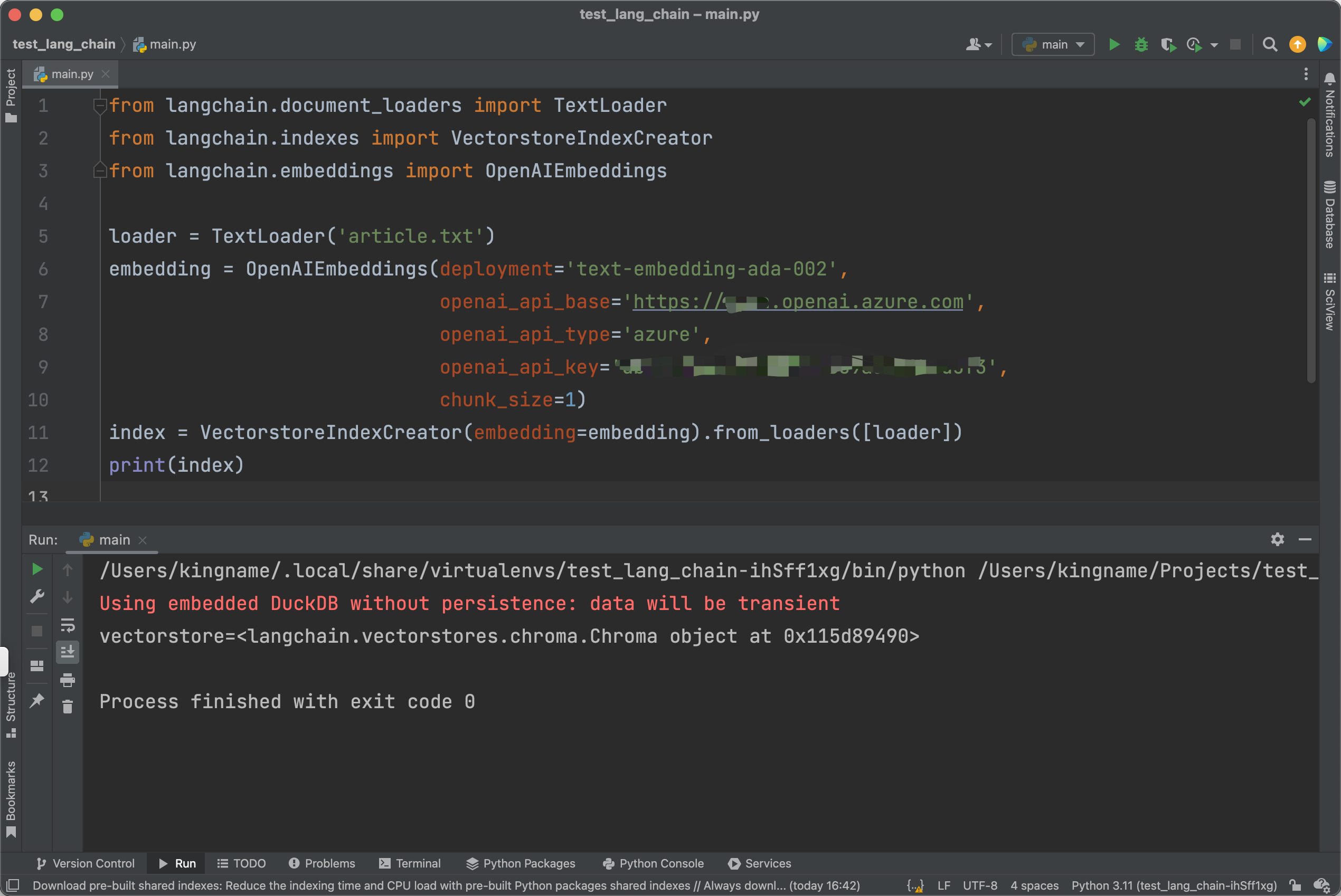
现在代码终于不报错了。代码中的chunk_size=1,限定了并发为1。那么我们继续把代码写完。运行效果如下图所示:
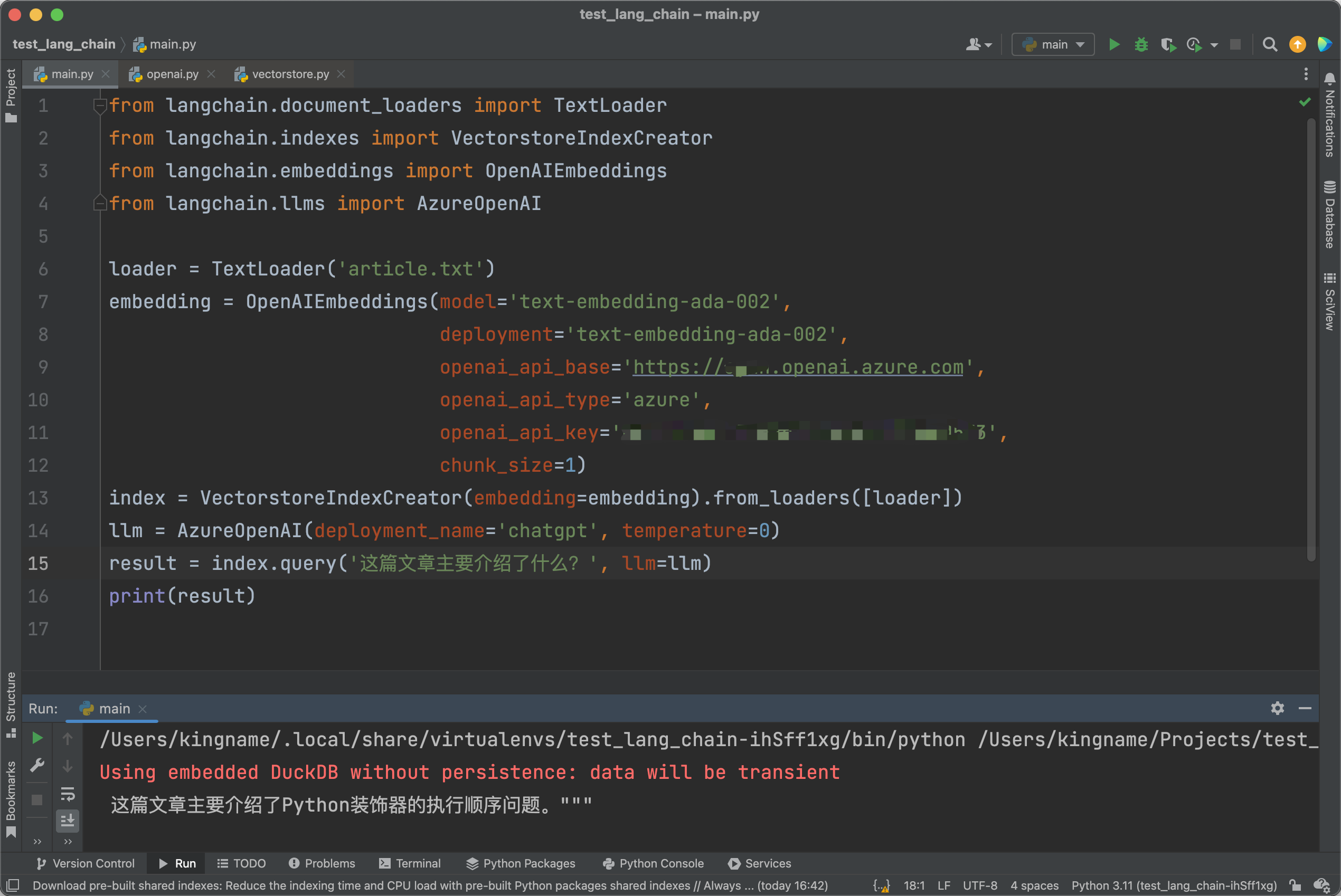
我们还可以通过主动传入参数的方式,使用其他的数据库而不是Chroma。这里以Redis为例:
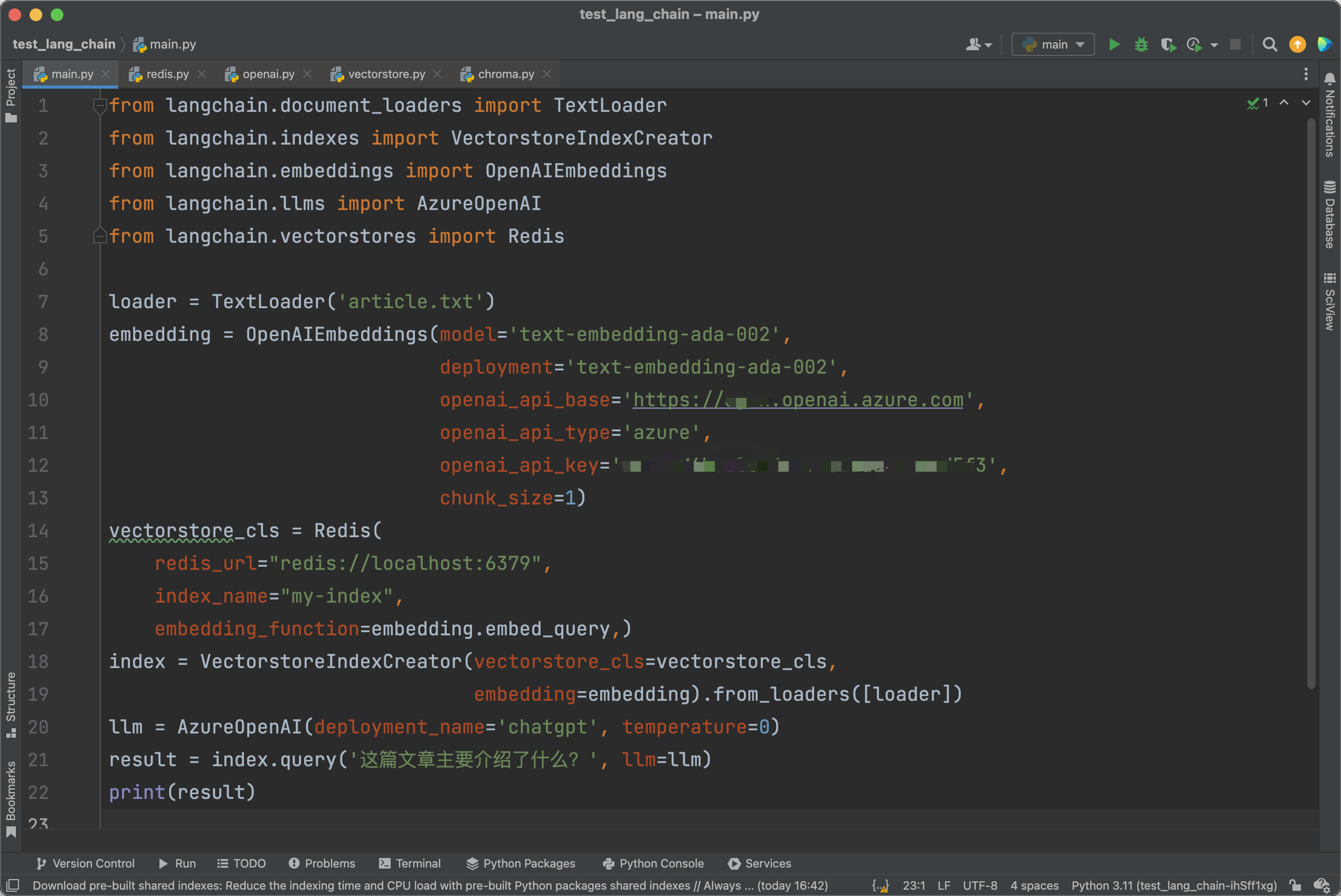
不过要使用Redis来作为向量数据库,需要在Redis中安装Redis Stack模块。安装方法可以在Redis官方文档中找到。