一日一技:自动提取任意信息的通用爬虫
使用过GNE的同学都知道,GNE虽然是通用爬虫,但只是文章类页面的通用爬虫。如果一个页面不是文章页,那么就无能为力了。
随着ChatGPT引领的大语言模型时代到来,这个问题基本上已经不是问题了。我们先来看一个效果。首先打开Linkedin,随便找一个招聘的岗位,如下图所示:
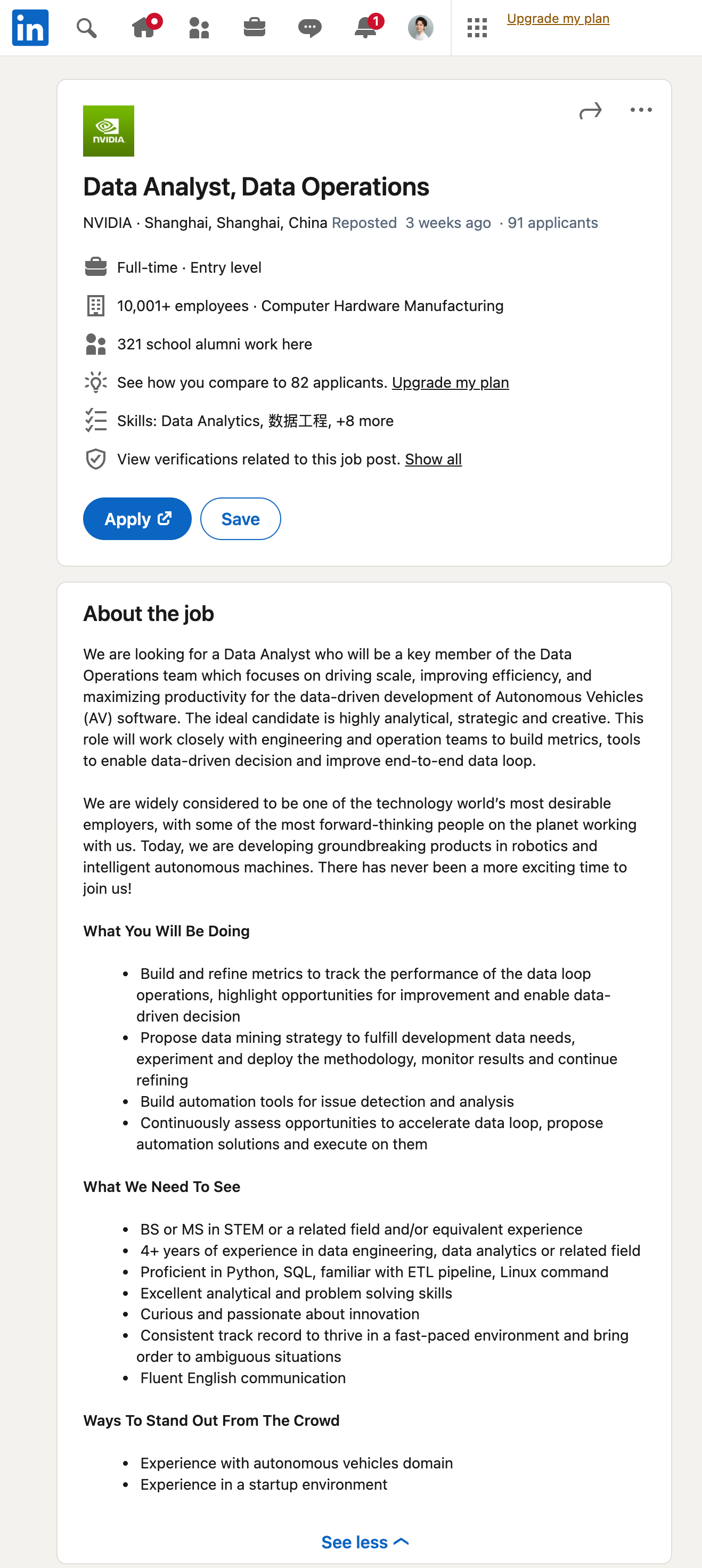
然后,我们直接使用GPT从这里提取信息:

对应的Prompt为:
1 | 你是一个数据提取小助手,能够从一大段招聘相关的文本中提取有用的信息并以JSON格式返回。 |
在生产环境,我们显然不能使用GPT的网页版。但GPT API的收费比较贵,一般来说,GPT 3.5 Turbo的价格是每1000 Tokens收费0.002美元;GPT 4 Turbo的价格是每1000 Prompt Token收费0.01美元,每1000 Completion Tokens收费0.03美元。
如果我们直接把网页的源代码整个丢给GPT接口,那么费用是非常昂贵的。这种情况下,我们就应该先对网页源代码进行清洗,移除显然不需要的元素,从而大幅减少Token的占用。
首先,我们可以先移除一些显然不可能包含关键内容的标签:
1 | USELESS_TAG = ['style', 'script', 'link', 'video', 'iframe', 'source', 'picture', 'header', 'blockquote', |
然后,我们可以根据一些元素的class属性,找到另外一批显然不可能包含关键内容的标签,一并移除:
1 | USELESS_ATTR = { |
接下来,对于下面没有text()元素的标签,也可以移除。
清洗干净以后,我们再使用XPath:normalize-space(string())提取出页面上的文本,把文本发给GPT,就可以正常解析内容了。
具体清洗的代码,大家可以在GNE的源代码可以看到详细的清洗步骤和流程。
随着MistralAI前两天在推特上通过磁力链接的方式发布模型,我们可以预见到,未来开源大模型功能越来越强大的同时,对机器配置的需求会越来越低。我看有一些大模型的计费方案,已经改成每100万Token几毛钱了。所以未来通用爬虫的解析门槛会越来越低,就像我这篇文章给出的例子,你只需要写几段Prompt,就可以解析出你需要的内容。
以后做通用爬虫,唯一的技术挑战就是怎么获取到网页源代码。只要有了源代码,剩下的事情交给大模型就好了。
有一个好的爬虫代理,就能爬取绝大多数的网站。国内的代理供应商,一般隧道代理都是按并发数收费,性能都差不多。但国外的代理,不知道哪根筋不对,全都是按流量收费的。我调研了十多个海外代理供应商,最后综合评测下来亮代理还不错,虽然也是按流量收费,但代理可用性确实非常高。有兴趣的同学可以试一试,他们提供免费试用:Proxy - Bright Data

最后还是我前两年的观点,国内这边的工作环境会越来越恶劣,大家尽快放眼海外,爬虫出海,程序出海,才是未来的方向。