一日一技:怎么中文也属于字母?
我最近在使用一个第三方库,叫做RapidFuzz。它有一个工具函数,叫做utils.default_process,在官方文档里面,是这样介绍的:
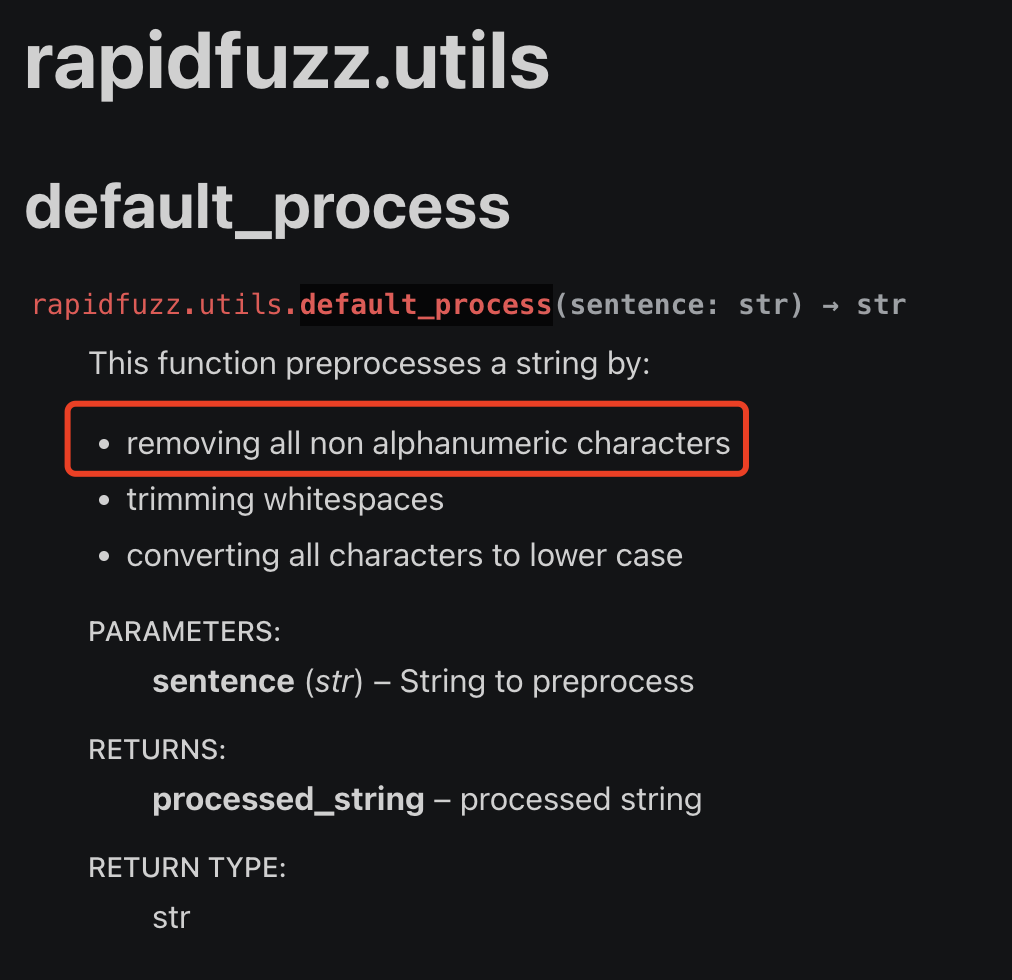
红色方框里面说,这个函数可以移除所有的非alphanumeric字符。如果我们使用翻译软件,会发现alphanumeric的意思是字母和数字。如下图所示:
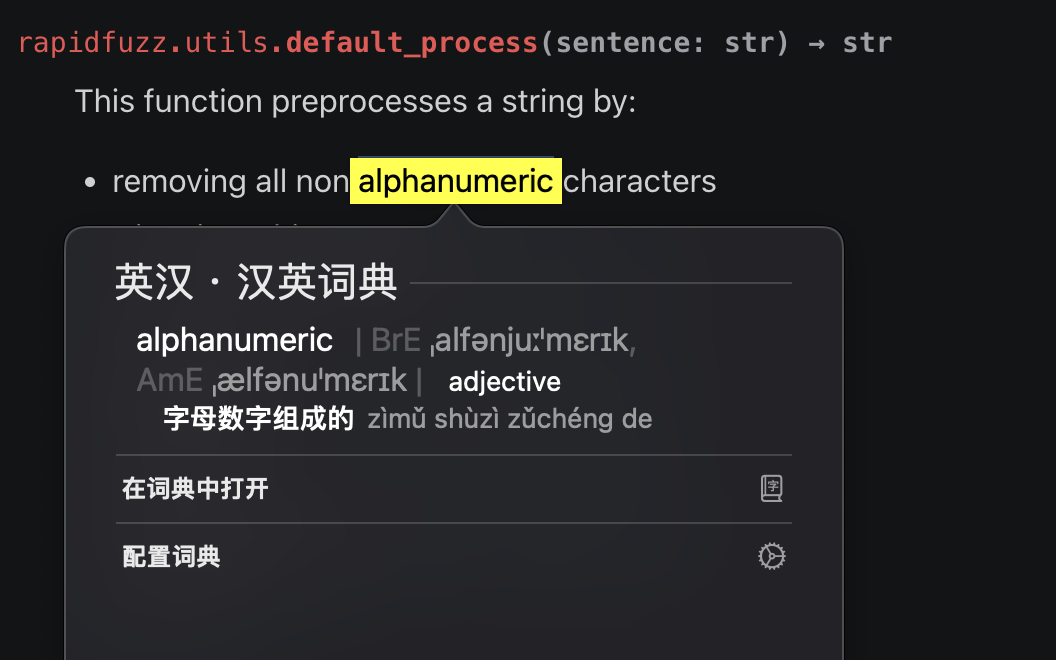
因此,我想当然的觉得,这个功能函数,只会保留26个英文字母的大小写加上10个数字,一共62个字符。把除此之外的所有其他字符都移除掉。
但我经过测试,它竟然没有办法过滤掉中文字符,如下图所示。难道终于也属于字母?

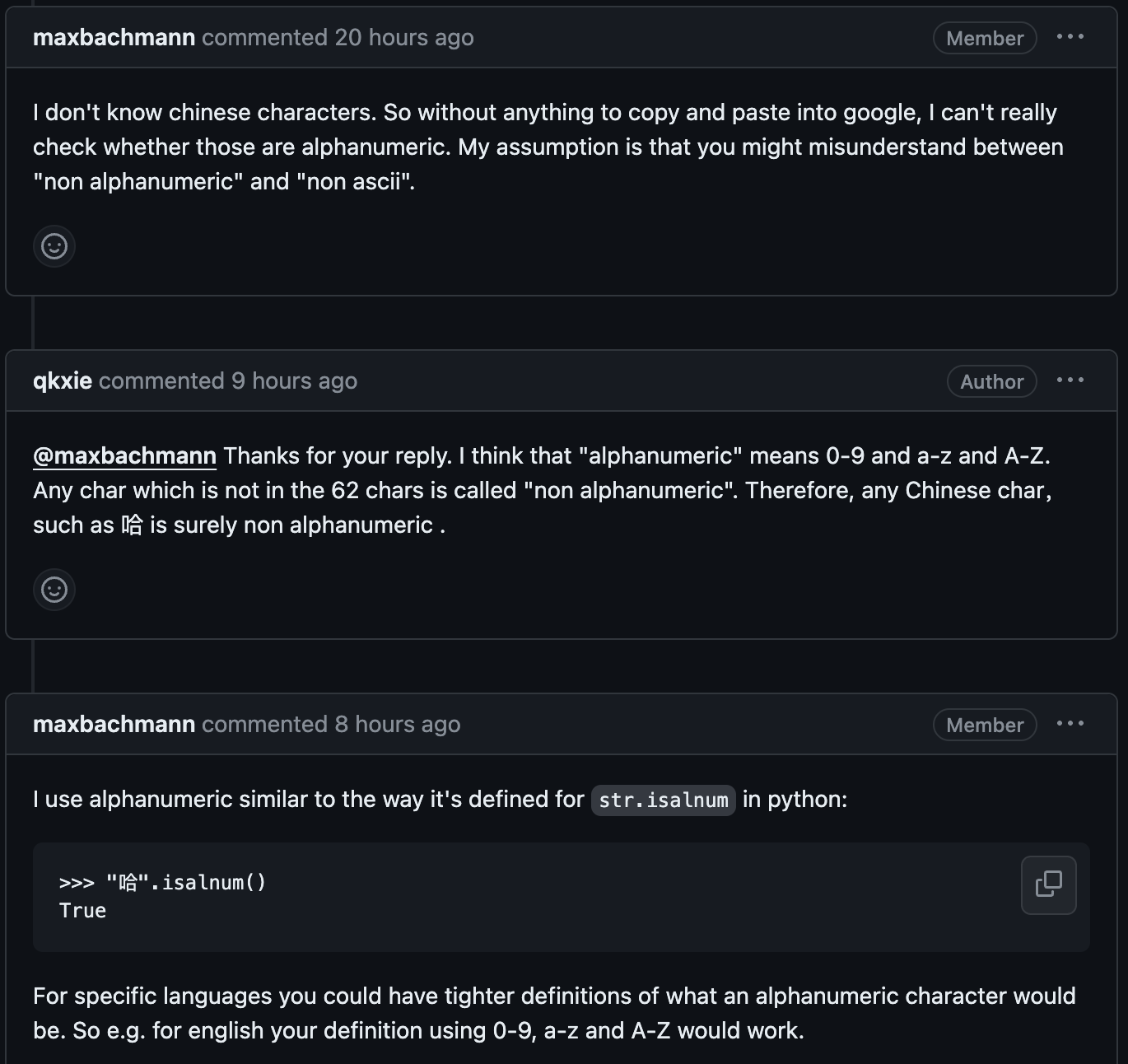
于是我到Github上面去给这个项目提Issue。但作者却说这个函数没有问题,并且使用Python的.isalnum()来做测试,发现Python也会认为中文也是alphanumeric。如下图所示:
这就非常奇怪了,于是我找到Python官方文档,发现它是这样说的:
Return
Trueif all characters in the string are alphanumeric and there is at least one character,Falseotherwise. A charactercis alphanumeric if one of the following returnsTrue:c.isalpha(),c.isdecimal(),c.isdigit(), orc.isnumeric().
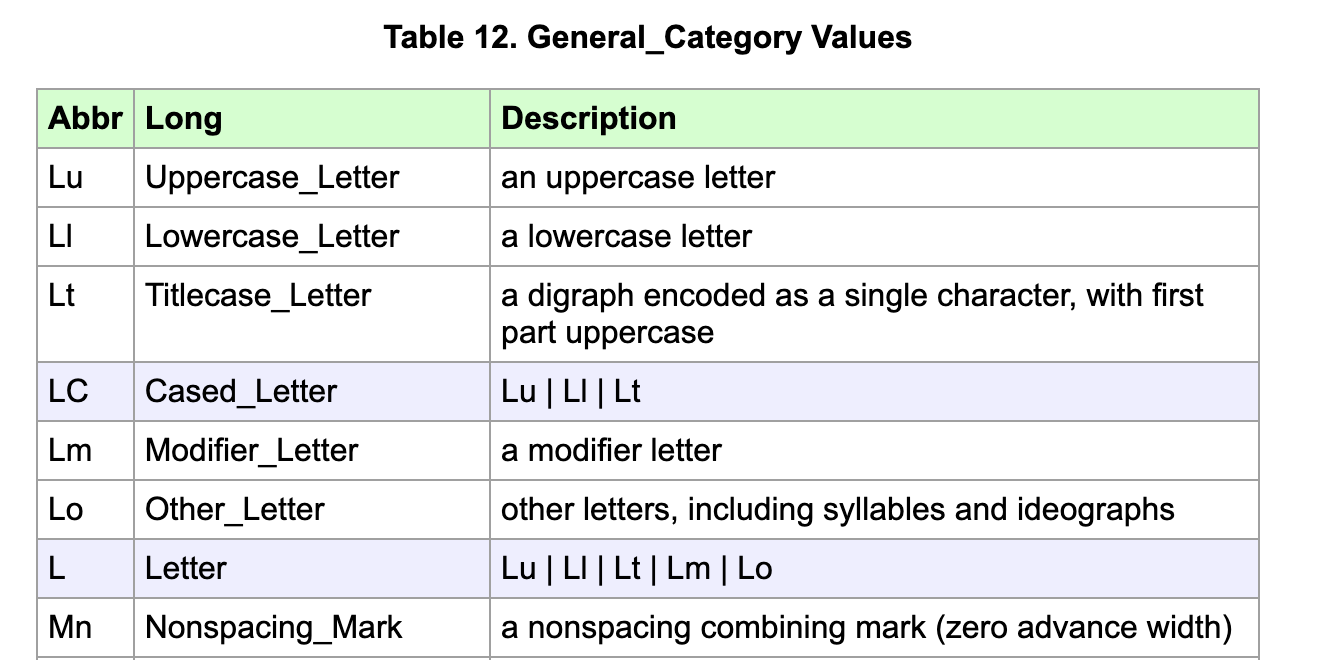
说明'中文'.isalnum()返回True,显然是因为'中文'.isalpha()返回了True。而之所以.isalpha()会返回True,是因为它判断的不仅仅是英文字母,而是所有Unicode里面,类别为letter的字符:
Return
Trueif all characters in the string are alphabetic and there is at least one character,Falseotherwise. Alphabetic characters are those characters defined in the Unicode character database as “Letter”, i.e., those with general category property being one of “Lm”, “Lt”, “Lu”, “Ll”, or “Lo”.
在Unicode标准网站UAX #44: Unicode Character Database上面,可以看到它这里定义的Lm、Lt、Lu、Ll和Lo的意思:
我们使用Python自带的unicodedata模块,可以看到中文字符的类型,确实是Lo,如下图所示:

所以,'中文'.isalpha()返回True确实是合理的。
以后看到alphanumeric,再也不要以为只有62个字符了。