一次性数据抓取的万能方法,半自动抓取任意异步加载网站
我们有时候临时需要抓取一批数据,数据不多,可能就几页,几百条数据。手动复制粘贴太麻烦,但目标网站又有比较强的反爬虫,请求有防重放的验证,写代码抓取也不方便。用模拟浏览器又觉得没必要,只用一次的爬虫,写起来很麻烦。
例如,我经常逛色魔张大妈的精选好价页面。这个页面会列出各种折扣的信息。但它只能按大类筛选,无法用关键词搜索。如下图所示
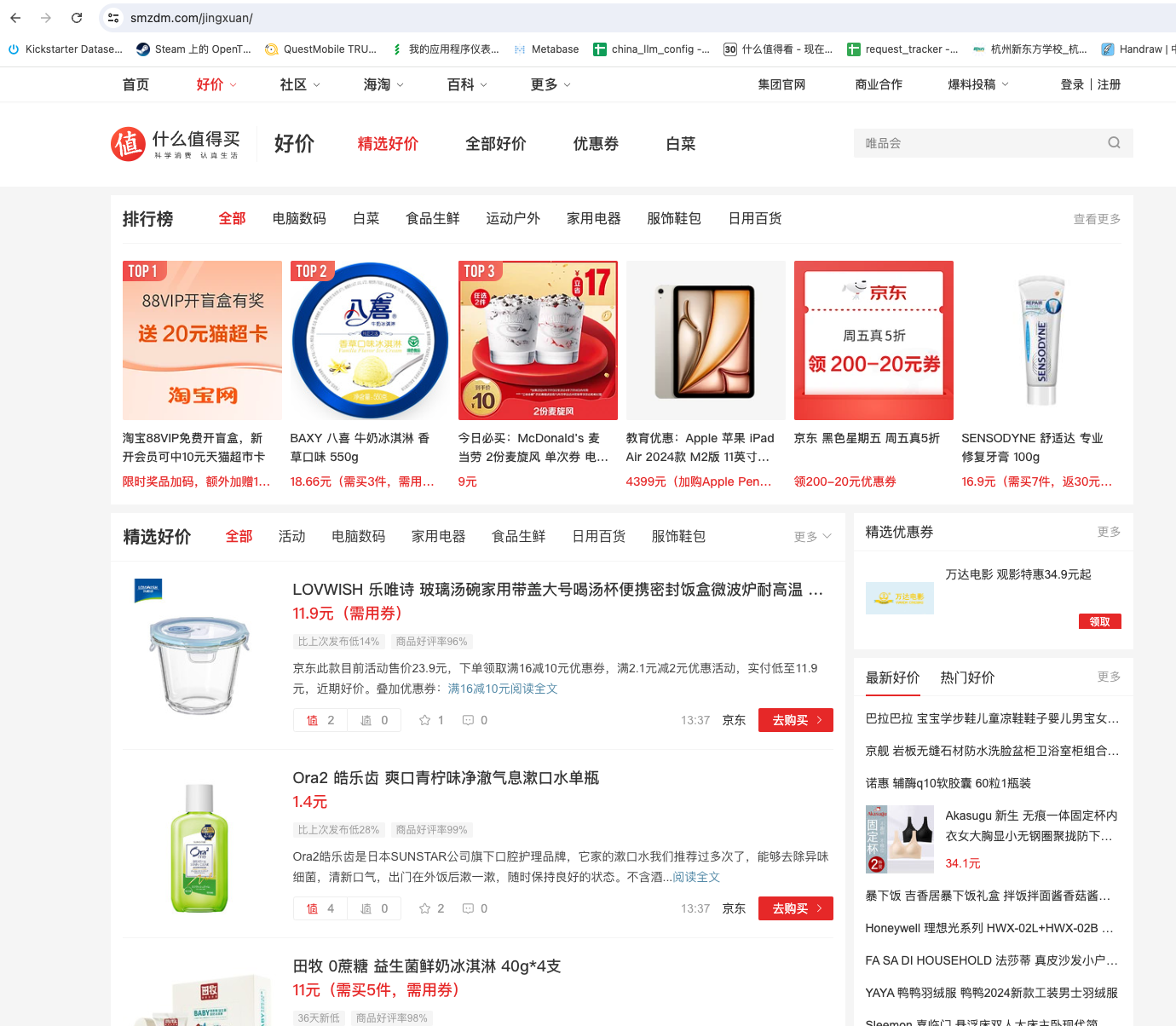
我打算只看前 10 页内容就好了。但一页一页看太麻烦了。有没有什么快速爬虫,把这个列表页的内容抓取下来呢?
其实这种需求,使用半自动爬虫是最简单的。不需要考虑网站反爬虫的问题,因为你使用的就是真实的浏览器,不会通过代码来发起请求。而且这个列表页的内容都是异步加载的,直接在开发者工具可以看到数据包,数据包里面就有当前页面的全部内容。如下图所示:

有没有什么办法,快速把这些数据包弄下来处理呢?我们实际上不需要任何抓包软件,也不需要安装任何证书。使用浏览器开发者工具,配合上一日一技:iOS 抓包最简单方案这篇文章讲到的解析 HAR 文件的方法,可以快速安全获取页面的内容。
首先打开浏览器的开发者工具,勾选上Perserve log复选框,然后刷新页面。注意一定要先打开开发者工具再刷新页面,顺序不能搞反了。接下来,你就正常往下滚动页面或者点击翻页按钮,滚到你不想滚为止。此时开发者工具里面已经有很多数据包了。如下图所示:

在任何一个数据包上面右键,选择Save all as HAR with content。就会把当前页面的所有数据包全部合并到一个 har 文件里面,如下图所示。

接下来,使用之前那篇文章中介绍的方法,Python 安装haralyzer库,读取 har 文件,就可以提取出想要的内容了。包含商品列表页的数据包,URL 中含有关键字jingxuan/json_more,所以我们可以使用这个关键词来过滤数据包,如下图所示:

通过分析数据包返回的 JSON,也可以知道商品信息所在的字段,如下图所示:

那么我们就可以开始编写解析的代码了:
1 | import json |
运行结果如下图所示,轻轻松松就能解析出数据了。全程不用考虑反爬虫的问题。

当你要切换到其他网站时,只需要修改代码里面 url 过滤条件和读取 json 对应的字段。其他内容都不需要修改。