一日一技:真正的自然语言编程
在之前的文章《一次性数据抓取的万能方法,半自动抓取任意异步加载网站》中,我讲到一个万能的爬虫开发方法。从浏览器保存HAR文件,然后写Python代码解析HAR文件来抓取数据。
但可能有同学连Python代码都不想写,他觉得还要学习haralyzer太累了,有没有什么办法,只需要说自然语言,就能解析HAR文件?
最近我在测试open-interpreter,发现借助它,基本上已经可以实现自然语言编程的效果了。今天我们用小红书为例来介绍这个方法。
如下图所示,我现在要抓取小红书首页游戏频道的帖子。通过不停往下滑动页面,我已经抓到了不少数据包。
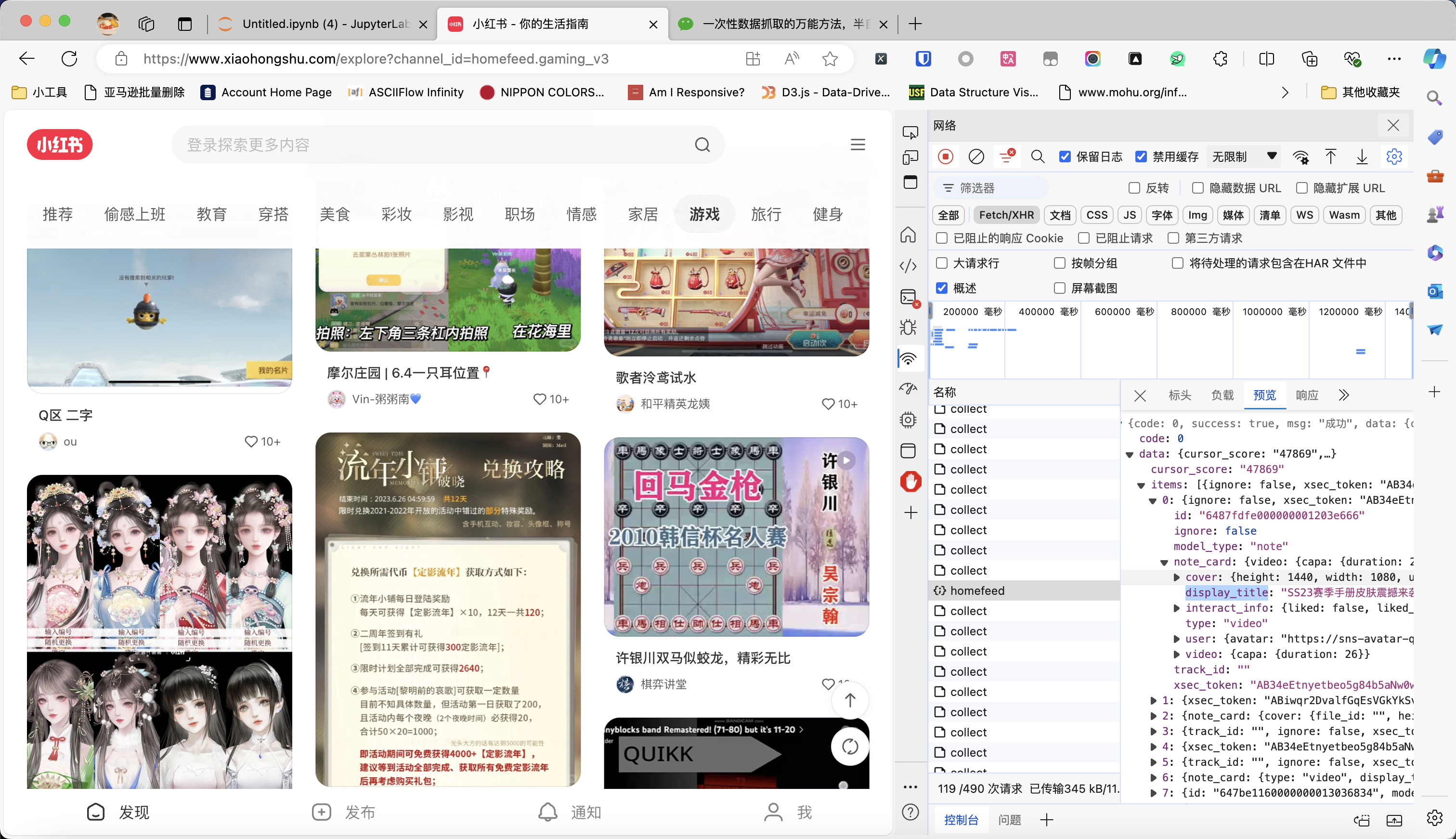
现在,把所有数据包保存为xiaohongshu.har文件(方法看我上一篇文章)。
接下来,我们来安装open-interpreter,使用pip进行安装就可以了:pip install open-interpreter。它依赖的第三方库比较多,因此可能需要安装一会儿。
我使用的是deepseek的模型,因为非常便宜,1元钱充值50万Token,常规任务足够了。理论上,所有兼容openai库的模型都可以。大家也可以使用Groq的免费API,或者硅基流动的API,或者通义千问,或者ChatGPT或者Azure OpenAI都没问题。也支持Claude和Ollama,但我测试下来Ollama运行的Llama3.1或者Qwen2 的8b模型效果都还不太好。
如果你是用的Open AI的API,那么你什么都不需要做,直接命令行运行interpreter即可,第一次运行他会让你提供API KEY。如果是其他的大模型。在deepseek获得API Key以后,我们创建一个文件:~/Library/Application Support/open-interpreter/profiles/default.yaml,在里面填写如下内容:
1 | llm: |
如下图所示。

然后命令行执行interpreter启动。如下图所示:
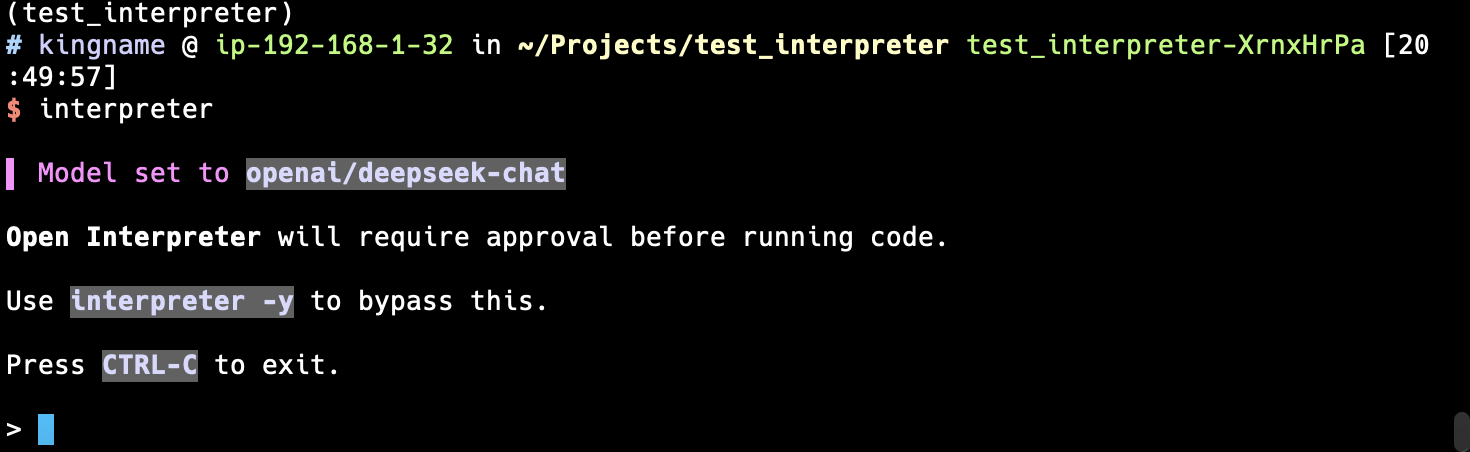
在这里,直接输入你的需求就可以了。我这里写的内容如下:
1 | 读取/Users/kingname/Downloads/xiaohongshu.har 这个文件,然后找到url中包含/api/sns/web/v1/homefeed的请求,接下来,使用json.loads加载返回的内容。注意返回的内容可能直接是JSON字符串,也可能是base64字符串,你需要判断。如果发现是base64,需要先解码。然后再使用json.loads加载。读取.data.items列表,对这个列表进行迭代,如果每一项的model_type字段不为note,跳过。如果是note,那么就读取note_card.display_title字段,把结果打印出来。 |
open-interpreter会自动生成执行计划和Python代码,如下图所示:

根据它的提示,按下y执行,然后他会自动执行下一步骤,再按y,直到结果出来,如下图所示:

如果执行时报错,它会自动分析原因,然后修改代码,如下图所示:

它修改完成以后,运行结果如下:

如果你在一开始的需求里面让他把结果生成到一个txt文件里面,那么你这个时候就可以去对应的txt文件里面拿到结果了。
整个过程中,你唯一需要做的只有两件事情:
- 输入需求
- 不停按y
如果你连y都不想按,那么可以在启动时加个命令,自动执行代码interpreter --auto_run。
open-interpreter还支持在Python里面调用,方法如下:
1 | import interpreter |
借助open-interpreter,我们可以实现全自动爬虫,因为它可以自动使用requests请求URL,也可以自动操作浏览器,自动滚动页面。而且这种方式操作的是真正的浏览器,不会被反爬虫机制检测到。只要控制滚动频率,可以说是万无一失。对于任意网站,无论是后端渲染还是异步加载,全都可以正常抓取。只要你能清楚描述你的需求,就能正常实现你的需求。
再举个例子,我想爬我的博客文章,需求描述如下:
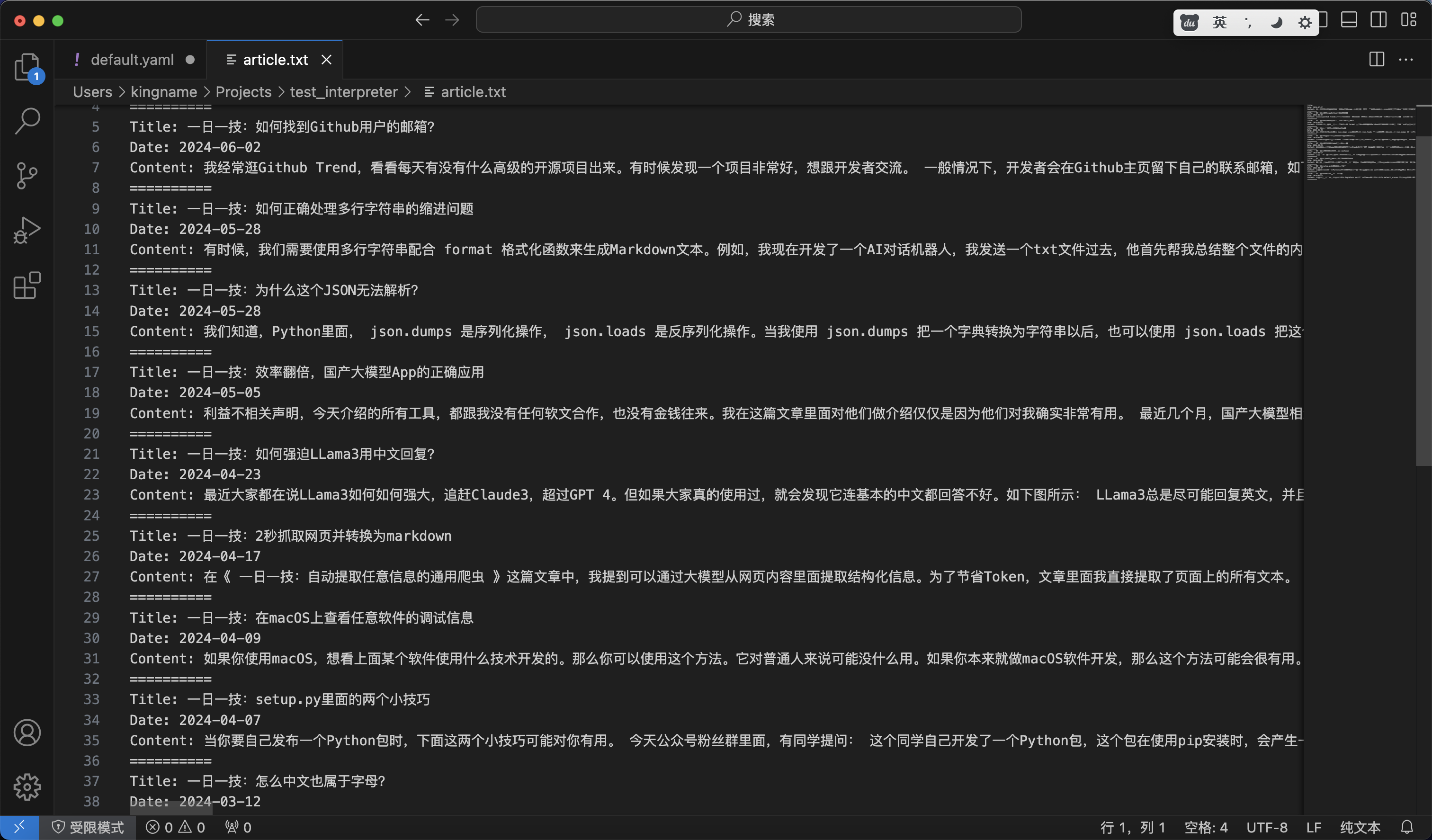
1 | 访问https://kingname.info/,使用lxml执行xpath: //a[@class="post-title-link"]/@href获取每篇文章的url。然后逐一进入每一篇文章的详情页,使用//h1[@class="post-title"]/text()获取标题,使用//time[@itemprop="dateCreated datePublished"]/text获取发布时间,使用//div[@itemprop="articleBody"]/p//text()获取正文。然后把这些数据保存到article.txt文件中。每篇文章之间 使用==========分割 |
运行效果如下图所示: