一日一技:为什么我很讨厌LangChain
一说到RAG或者Agent,很多人就会想到LangChan或者LlamaIndex,他们似乎觉得这两个东西是大模型应用开发的标配。
但对我来说,我特别讨厌这两个东西。因为这两个东西就是过度封装的典型代表。特别是里面大量使用依赖注入,让人使用起来非常难受。
什么是依赖注入
假设我们要在Python里面模拟出各种动物的声音,那么使用依赖注入可以这样写:
1 | def make_sound(animal): |
对于make_sound函数,你不需要知道animal这个对象的bark方法具体是怎么实现的,你只需要调用它并获取它的返回值就可以使用了。
当你要添加一个新的动物时,你只需要实现一个类,这个类里面有一个方法叫做bark。那么,当这个动物需要发出声音时,把这个动物实例传入给make_sound函数就可以了。
看起来很方便是吧?不同的动物类互不影响,屏蔽了细节。
为什么我讨厌依赖注入
上面这段代码,看起来很好,符合设计模式。如果这段代码是你自己写的,确实很方便。但如果这段代码是别人写的,并且你不知道它的细节,那么这些依赖注入就是灾难。我们来看看LlamaIndex文档里面给出的代码:

这段代码是一个简化版的RAG。把文本文件向量化并存入向量数据库。用户输入问题以后,程序自动去向量数据库查询数据。看起来代码非常简洁对吧?文本转向量的逻辑隐藏起来了,读写向量数据库的逻辑隐藏起来了。开发者不需要关心这些不重要的细节,只需要修改data文件夹里面的文档就能索引原始文档。修改query_engine.query的参数,就可以实现一个RAG。开发者把注意力放在了真正重要的地方,节约了时间,提高了效率。真是太完美了!
完美个屁!
上面这种狗屎代码,也就只能用来做个Demo。当开发者真正需要做二次开发的时候,上面的代码根本就不能用。
为什么不能用?因为我不知道query_engine.query背后是怎么查询index的。我也不知道VectorStoreIndex在索引文档时,具体是怎么操作的。LlamaIndex似乎还沾沾自喜地在这个文档下面,预设了用户可能会问的几个问题:
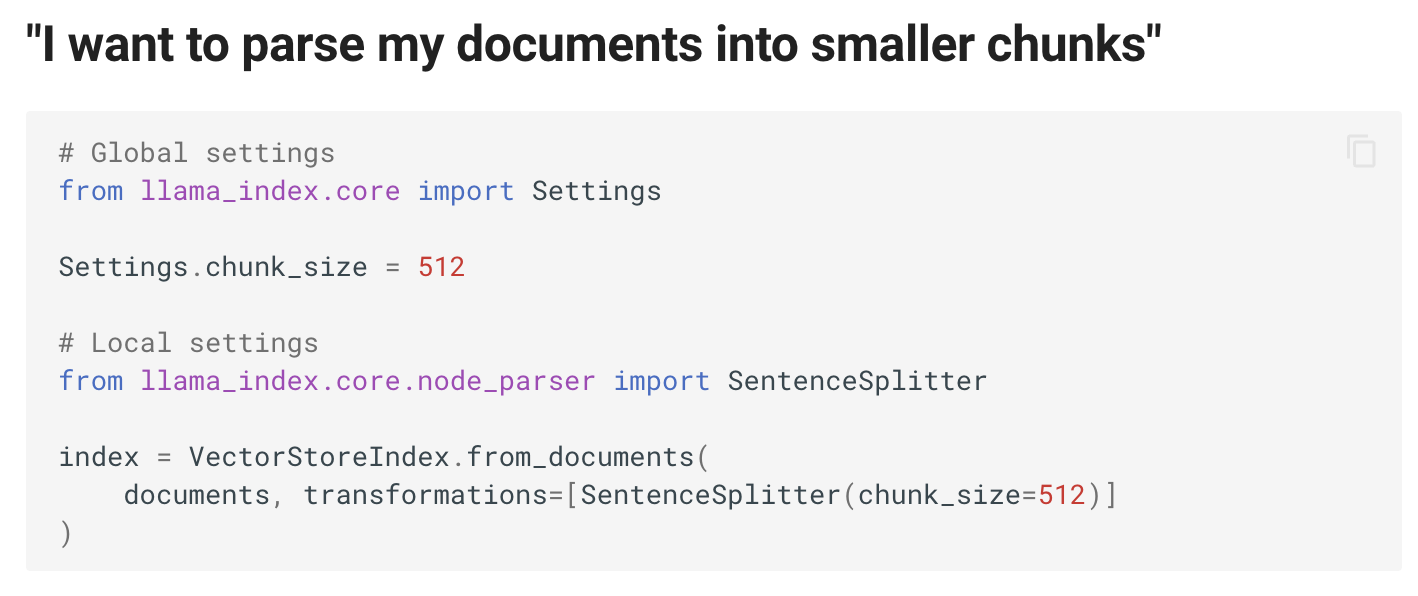
它觉得用户要把文档拆分成不同的段落时,可以使用SentenceSplitter。下面还有如何使用其他的向量数据库、查询更多文档、使用不同的大模型、使用流式返回……
看起来想得很周到对吧,它觉得用户能想到的需求,它都已经通过不同的类、不同的方法、不同的参数想到了。狗屎!
它根本不可能穷举用户所有的需求。例如:
- 我希望程序从向量数据库查询到多个chunk以后,执行一段我自己的逻辑来过滤掉显然有问题的问题,然后再进行ReRank
- 从向量数据库查询数据以后,我需要自己插入几条固定的chunk。然后再给大模型问答
这些需求,它根本想不到!而我作为开发者,我需要。但是我应该怎么插入到它的流程里面?
上图中,SentenceSplitter的实例作为参数传给了VectorStoreIndex.from_documents。那么如果我对拆分文档的逻辑有一些自己的要求,我怎么加进去?我自己写一个MyCustomSentenceSplitter?现在问题来了,这个类有哪些方法应该怎么写?from_documents里面调用的是哪个方法?上面make_sound之所以看起来很简洁,是因为这个代码是我自己写的,我知道它会调用animal.bark。但现在LlamaIndex是别人写的,我甚至都不知道它里面会怎么使用SentenceSplitter。难道为了实现一个非常简单的文档分Token的逻辑,我还必须去翻阅它的语法文档甚至看它的源代码?那基本上要实现一个我想要的代码,我得把它整个文档先全部看完,源代码也看完,我才能开工。
LangChain和LlamaIndex使用大量的依赖注入,给开发者画了一个框,它内部控制了所有的流程。开发者不知道这个流程,开发者只能做完形填空,把代码缺的地方填写进去,就能有一个将将可以工作的程序出来。
但作为开发者,我需要的是控制这个流程,而不是去填空。
有人可能会说,那你可以去看LlamaIndex的源代码,看它内部是怎么查询向量数据库的,然后你自己写个类,把你自己的代码写进去啊。
如果有人这样想,我觉得你就是被人虐待了还在想是不是自己躺好一点让别人打你的时候没有那么累。
我想要的是什么
在使用做大模型应用开发时,我需要的是控制程序的流程。我需要简化的地方,是流程中的每个节点的调用方式,而不是简化这个流程。流程是我控制的,该不该简化,我自己知道!
来看看Requests作者Kenneth Reitz的新作品:SimpleMind。这是我认为符合AI for Human的项目。Kenneth真正知道使用这个库的人需要什么。我们来看看SimpleMind的使用方法:
基本使用
1 |
|
上下文记忆
1 | class SimpleMemoryPlugin(sm.BasePlugin): |
工具调用
1 | def get_weather( |
控制流程
SimpleMind简化了我调用大模型这个节点。那么如果我就能自己来控制程序的逻辑了。还是以RAG为例,我希望在简化了节点以后,代码是这样的:
1 | def rag_ask(question): |
其中,text2embedding/query_vector_db/rerank/ask_llm这几个函数,我能够使用简单的几行代码就实现,我可以在这个流程里面的任意两个节点之间,随意添加我自己的逻辑。这才是我想要的。
总结
实话实说,看到LangChain的使用方法,我就觉得这东西是一群写Java或者写C#的人,强行来写Python搞出来的缝合怪,整个代码我看不到Python的任何编码哲学,我能看到的只有过度封装,为了抽象而抽象。LangChain的作者,根本就没有站在Python开发者的角度制定它的使用方法。