一日一技:超简单方法显著提高大模型答案质量
很多人都知道Prompt大神李继刚,他使用Lisp语法来写Prompt,把大模型指挥得服服帖帖。但我们很多时候没有办法把自己业务场景的Prompt改造成伪代码的形式。
相信不少人跟我一样,会使用Markdown格式来写Prompt,大部分时候没什么问题,但偶尔总会发现大模型返回的结果跟我们想要的不一样。
Markdown的弊端
例如下图所示:
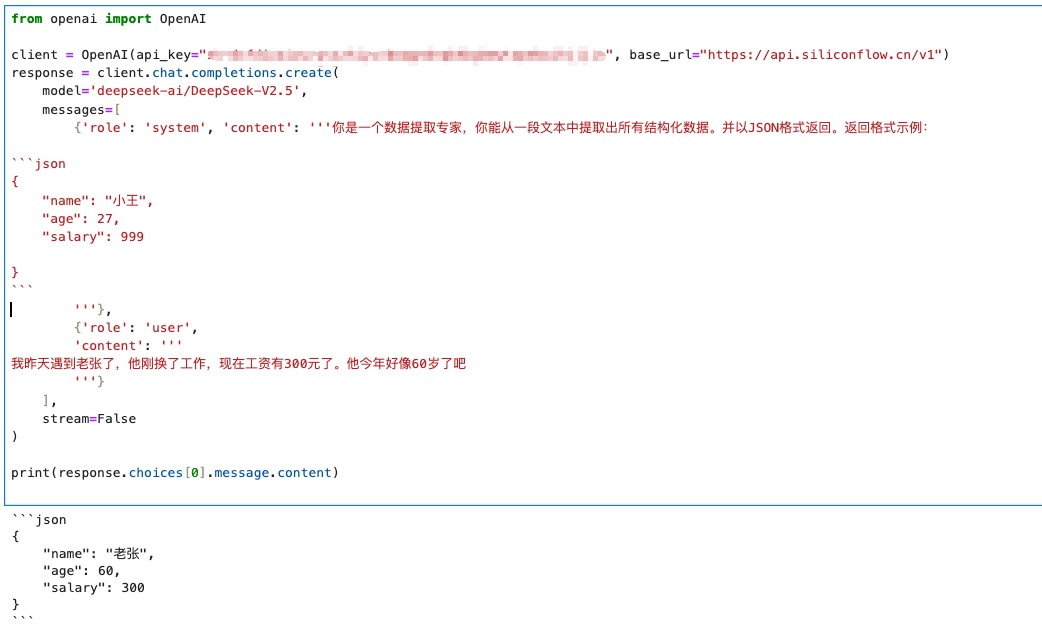
让大模型给我返回一个JSON,它返回的时候会用Markdown的多行代码格式来包装这个JSON。我后续要解析数据时,还得使用字符串切分功能把开头结尾的三个反引号去掉。即便我把system prompt里面的反引号去掉,改成:
1 | 你是一个数据提取专家,你能从一段文本中提取出所有结构化数据。并以J50N格式返回。返回格式示例: |
大模型有时候也会在返回时加上三个反引号。
解决方法
今天要讲的这个超级简单的方法,就可以解决这种问题。这个方法就是,别使用Markdown,改成使用XML。
我们来看看把上面这个例子改成XML以后的效果:
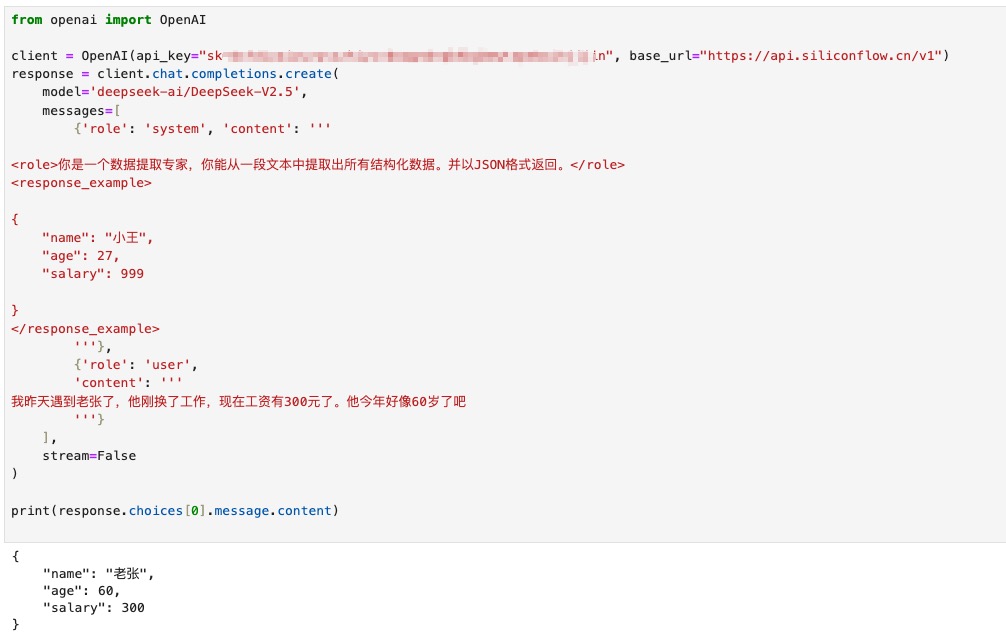
返回的结果直接就满足要求。
在使用XML格式的Prompt时,对格式要求没有那么严格,它的核心目的就是让大模型能区分出Prompt里面的各个部分。因此标签的名字可以自己随便取,只要能表名意思就好了。例如上面我使用标签<response_example>来表示我希望返回的数据长什么样。
可能有同学会觉得上面这个例子简单了,那么我们再来演示几个例子来说明用Markdown做Prompt有什么缺陷。
更多例子
避免Prompt注入
假设我需要让大模型阅读一篇文章,然后基于文章回答3个问题,我可能会这样写Prompt:
1 | 你是一个资深的文学家,你正在阅读一篇关于大模型的文章,请仔细阅读,然后基于文章的内容,回答三个问题: |
我们在代码里面,使用字符串的.format把文章原文填充上去,然后整体发送给大模型来回答。看起来没什么问题对吧?但有时候,你会发现,大模型返回的内容只有一个问题的答案,并且这个问题还不是我指定的三个问题之一!
原来,我传入的这篇文章,它长这样:
1 | 第一段... |
所以原文的最后一句话影响到了Prompt,导致大模型完全忽略了我前面写的三个问题,而是真的在分享一下你对大模型的观点和看法。
如果我们使用XML格式来改造这个Prompt,就可以完全解决这个问题。改造以后的Prompt如下:
1 | <role>你是一个资深的文学家</role> |
这样一来,无论文章里面的内容怎么写,他都不会影响大模型回答我提的三个问题了。
让结构更清晰
有时候,我们的Prompt会比较长,里面包含了给大模型的回答示例,例如:
1 | 你是一个资深的文学家,你正在阅读一篇文章,请仔细阅读,然后基于文章的内容,按如下格式返回总结: |
看起来似乎没有问题对吧?那么我问你,## 规则这个小节,你会不会觉得它和## 关键人物混起来了?有时候你如果不停下来想一想,你可能会觉得大模型最后输出的内容可能是下面这个格式:
1 | ## 文章概览 |
但实际上## 规则这个小节是独立的,是对整个大模型的回答做指导和限制,它不是答案的一部分。
使用Markdown经常会出现这样的问题,你很难分清楚两段话是分开的还是连在一起的。大模型实际上也会被误导,导致最后给出的结果不符合你的预期。
但如果改成XML,就完全不会有这种混淆:
1 | <role>你是一个资深的文学家,你正在阅读一篇文章</role> |
可以看到,在这里我把XML和Markdown混在一起用了。这样写也完全没有问题。我们既通过XML让Prompt的结构更清晰了,同时又使用Markdown保持了Prompt的可读性。
保持对应关系
写过RAG的同学,应该知道有时候我们需要让大模型标记出答案对应的参考文献。假设我从向量数据库里面找到了10条文本,他们都跟用户的问题相关,现在把这10条文本和对应的ID一起发送给大模型,并且指示大模型在返回答案时,每一句话都需要带上出处。如果使用XML,那么我们的Prompt可以写成:
1 | <role>你是一个金融领域的专家,拥有丰富的投资经验</role> |
使用这种格式的Prompt,可以确保大模型返回的id确实就是对应原文的id。
总结
Markdown形式的Prompt,虽然简单方便,但有时候会让大模型产生误解,从而得不出你想要的答案。换成XML格式的Prompt,大模型的回答质量会显著提升。