一日一技:Scrapy如何发起假请求?
在使用Scrapy的时候,我们可以通过在pipelines.py里面定义一些数据处理流程,让爬虫在爬到数据以后,先处理数据再储存。这本来是一个很好的功能,但容易被一些垃圾程序员拿来乱用。
我看到过一些Scrapy爬虫项目,它的代码是这样写的:
1 | ... |
这种垃圾代码之所以会出现,是因为有一些垃圾程序员想偷懒,想复用Pipeline里面的代码,但又不想单独把它抽出来。于是他们没有皱褶的脑子一转,想到在Scrapy里面从数据库读取现成的数据,然后直接yield出来给Pipeline。但因为Scrapy必须在start_requests里面发起请求,不能直接yield数据,因此他们就想到先随便请求一个url,例如百度,等Scrapy的callback进入了parse方法以后,再去读取数据。
虽然请求百度,不用担心反爬问题,响应大概率也是HTTP 200,肯定能进入parse,但这样写代码怎么看怎么蠢。
有没有什么办法让代码看起来,即便蠢也蠢得高级一些呢?有,那就是发送假请求。让Scrapy看起来发起了HTTP请求,但实际上直接跳过。
方法非常简单,就是把URL写成:data:,,注意末尾这个英文逗号不能省略。
于是你的代码就会写成:
1 | def start_requests(self): |
这样写以后,即使你没有外网访问权限也没问题,因为它不会真正发起请求,而是直接一晃而过,进入parse方法中。我把这种方法叫做发送假请求。
这个方法还有另外一个应用场景。看下面这个代码:
1 | def start_requests(self): |
假如你需要让爬虫每分钟监控一个URL,你可能会像上面这样写代码。但由于Scrapy是基于Twisted实现的异步并发,因此time.sleep这种同步阻塞等待会把爬虫卡住,导致在sleep的时候,parse里面发起的子请求全都会被卡住,于是爬虫的并发数基本上等于1.
可能有同学知道Scrapy支持asyncio,于是想这样写代码:
1 | import asyncio |
但这样写会报错,如下图所示:
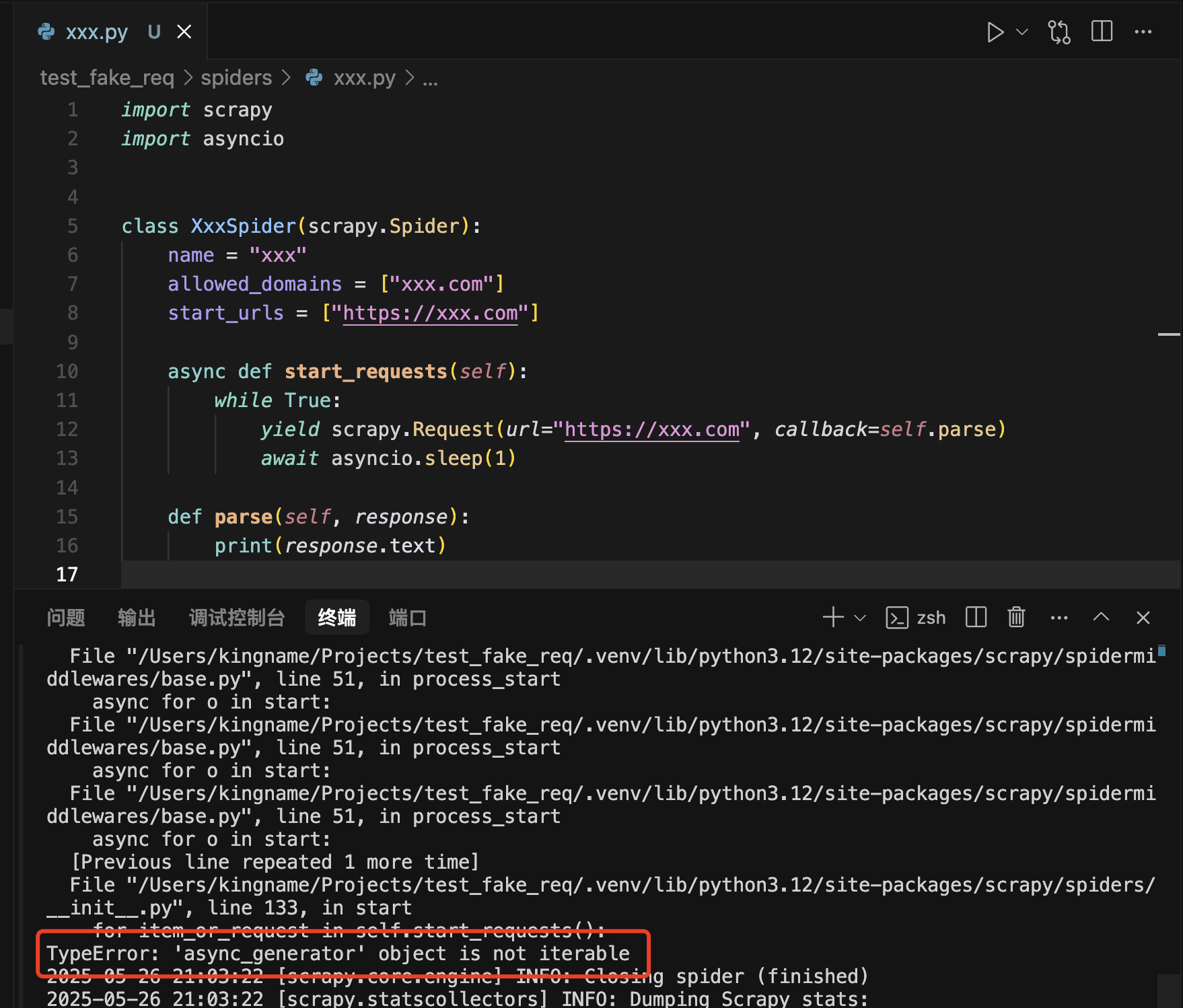
这个问题的原因就在于start_requests这个入口方法不能使用async来定义。他需要至少经过一次请求,进入任何一个callback以后,才能使用async来定义。
这种情况下,也可以使用假请求来解决问题。我们可以把代码改为:
1 | def start_requests(self): |
这样一来,使用了asyncio.sleep,既能实现60秒请求一次,又不会阻塞子请求了。
当然,最新版的Scrapy已经废弃了start_requests方法,改为start方法了,这个方法天生就是async方法,可以直接在里面asyncio.sleep,也就不会再有上面的问题了。不过如果你使用的还是老版本的Scrapy,上面这个假请求的方法还是有点用处。