一日一技:写XPath也并不总是这么简单
初级爬虫工程师有时候又叫做XPath编写员,他们的工作非常简单也非常繁琐,就是拿到网页的HTML以后,写XPath。并且他们觉得使用模拟浏览器可以解决一切爬虫问题。
很多人都看不起这个工作,觉得写XPath没有任何技术含量,随便找个实习生就能做。这种看法大部分情况下是正确的,但偶尔也有例外,例如今天我要讲的这个Case,可能实习生还搞不定。
下面我们来看一下这个视频。
在这个视频中,你首先点击Linkedin的信息流中,帖子右上角的三个点,想使用模拟浏览器点击Copy link to post链接,从而把帖子的链接复制到剪贴板。
但现在出现了一个问题,你无法看到这个弹出框对应的HTML代码。因为这个弹出框是在你点击了三个点以后动态生成的,它会动态修改HTML,从而出现这个下拉框。但当你想在开发中工具里面查看这个弹出框的源代码时,这个源代码就会自动消失,于是源代码就会变成没有弹出框的HTML。实际上,你在任何地方点一下鼠标左键——无论是网页内还是网页外,无论是浏览器还是系统桌面,只要在任何地方点击了鼠标左键,这个弹出框就会自动关闭。
那怎么写XPath呢?可能有人会想到使用关键字匹配,把XPath写成下面这样:
1 | //*[text()="Copy link to post"] # 你甚至不能确定这个链接对应的标签是不是<a> |
但由于Linkedin的页面文本会根据你的浏览器语言而变化,因此换了一个国家,甚至换了浏览器语言设置,你的这个XPath就不能用了。
那遇到这种问题怎么解决呢?其实也不难,他不是一个技术性难题,而是一个经验性问题。当你知道某个工具,你马上就能解决问题。当你不知道某个工具,你做5年爬虫也搞不定这个问题。
今天我们来说一个简单方法。当然方法有很多,但我觉得这个方法是最简单的。很多人在使用模拟浏览器开发爬虫的时候,会先开个真实浏览器,然后通过真实浏览器获取各个XPath,再直接写代码。那么遇到这个问题就会抓瞎了。
其实,如果你直接在模拟浏览器中开发代码,你就会发现问题根本不是问题。
我们使用DrissionPage来演示。首先直接在终端启动Python交互环境,或者使用Jupyter启动一个浏览器窗口:
1 | from DrissionPage import ChromiumPage |
命令执行以后,会自动打开一个新的浏览器。现在,你直接在这个浏览器上面手动登录浏览器,进入信息流页面。
现在,直接在新的浏览器中,打开开发者工具,定位到帖子右上角三个点对应的标签,如下图所示:
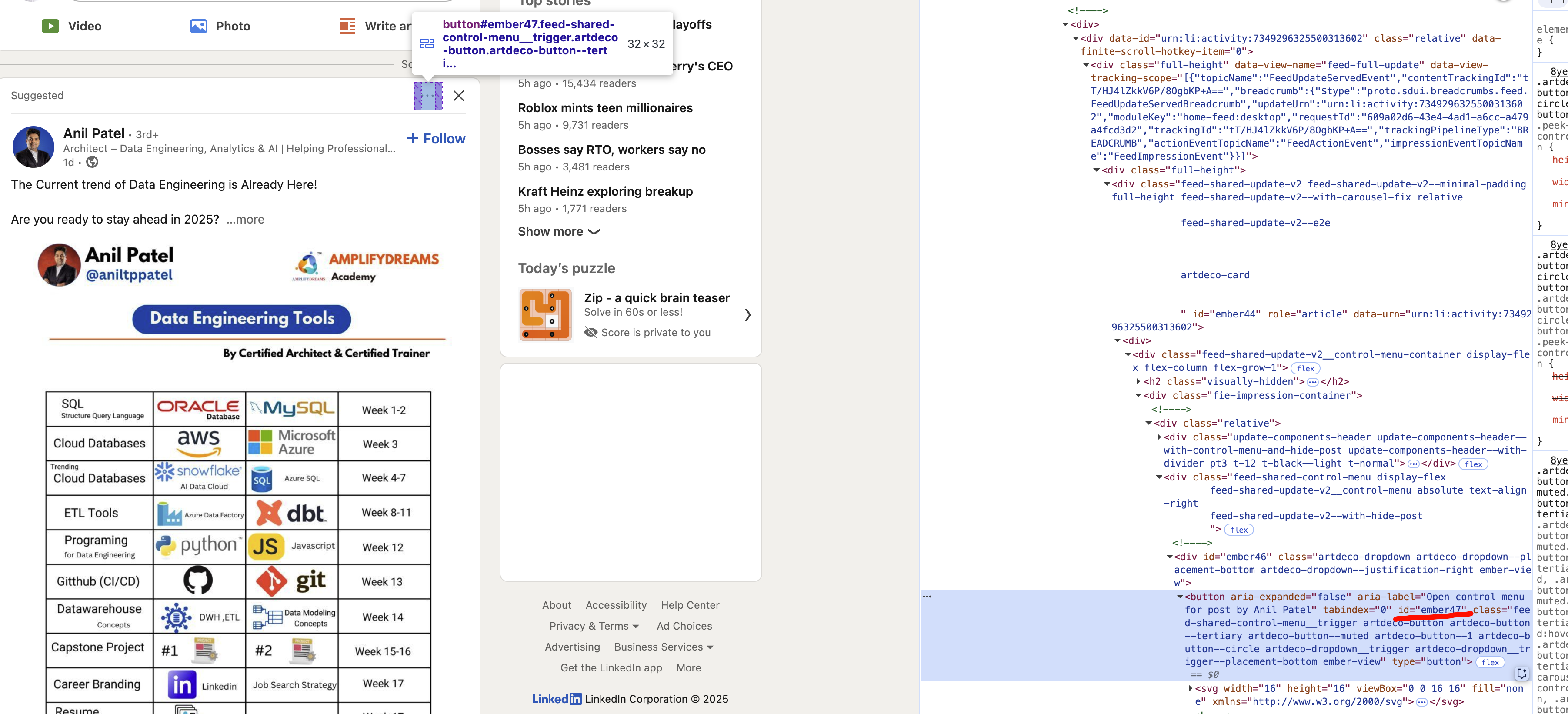
这三个点的id是ember47,所以,我们回到终端或者Jupyter里面,让DrissionPage来点击这三个点。这里非常重要,必须让DrissionPage来点击,不能手动操作。
1 | page.ele('x://button[@id="ember47"]').click() |
此时,这个弹出框出现了。但这次跟之前不一样,你在开发者工具里面展开HTML的时候,弹出框不会消失!如下图所示。
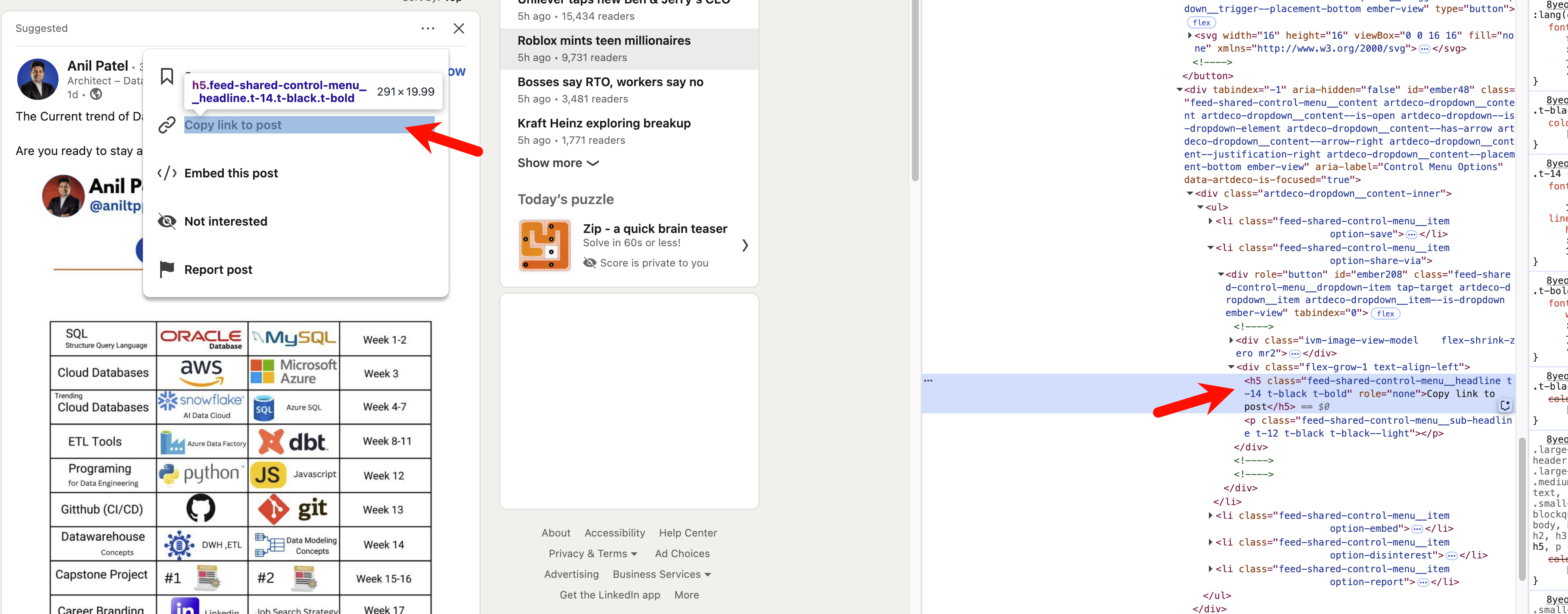
这样一来,你就可以直接找到Copy link to post对应的HTML元素,并编写对应的XPath:
1 | //h5[@class="feed-shared-control-menu__headline t-14 t-black t-bold"] |
这个方案适用于任何弹出框。