在 Python 中像字典一样持久化数据
我们知道,如果我们在 Python 中想把一段数据持久化到硬盘上,最简单的办法就是写文件:
1 | with open('data.txt', 'w', encoding='utf-8') as f: |
但这样做有一个弊端,就是在读取数据的时候,我们把整个数据读入内存以后,还需要单独写一段代码,用来区分哪里是username对应的值,哪些是password对应的值。
我们知道,如果我们在 Python 中想把一段数据持久化到硬盘上,最简单的办法就是写文件:
1 | with open('data.txt', 'w', encoding='utf-8') as f: |
但这样做有一个弊端,就是在读取数据的时候,我们把整个数据读入内存以后,还需要单独写一段代码,用来区分哪里是username对应的值,哪些是password对应的值。
二十几种设计模式中,单例模式是最简单最常用的一种。在其他语言里面实现单例模式要写不少代码,但是在 Python 里面,有一种非常简单的单例模式写法。
在上一篇文章中,我们说到了,itertools.tee不是线程安全的,并给出了一个例子,如下图所示:
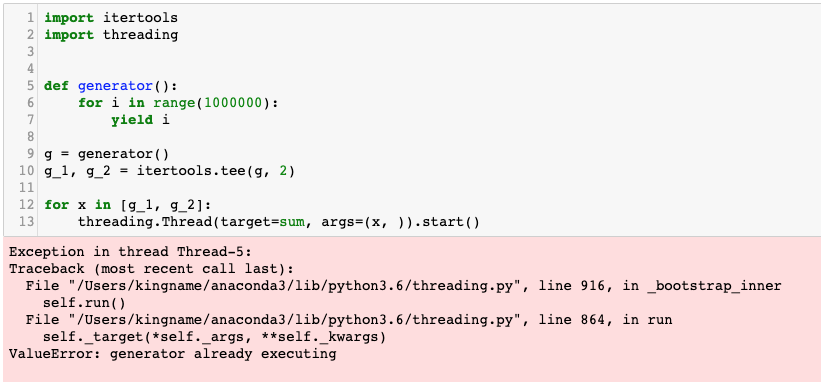
在两个线程里面同时运行分裂出来的生成器对象,就会导致报错。
在上一篇文章中,我们讲到了,使用itertools.tee可以让一个生成器被多次完整遍历:
1 | import itertools |
但是,我们说到itertools.tee有两个弊端,其一,如果分裂出来的多个生成器是按顺序执行的,其中一个完整遍历了再遍历第二个,那么就会导致内存中堆积大量的数据。
要解释这个问题的原因,我们就要理解itertools.tee背后的原理。
我们知道,Python 里面的生成器只能被消费一次,例如如下代码:
1 | def name_generator(): |
运行效果如下图所示:

在 say_hello函数里面,生成器已经被完整遍历了一次,那么在say_hi里面,就什么数据都拿不到了。
但如果我们用的是列表,就可以多次遍历,如下图所示:

大家注意观察区别。
那么有什么办法,能让生成器被多次完整迭代呢?这个时候就要使用itertools.tee这个函数了。它通过dequeue实现了让生成器多次消费的办法。
产品经理中午没有赶上食堂的午饭,于是纠集了一批人一起点外卖。然而正当她要下单时,老板找她有开会,于是她让开发小哥随便帮忙点一份。
产品经理开完会回来以后,发现还剩三份外卖没有人拿,分别是鲱鱼汤、螺蛳粉和大肠刺身。此时开发小哥碰巧不在,产品经理一时不知道哪一份才是自己的。
不是因为我高产似那啥。而是因为这些文章是我每天一篇发布在微信公众号上的,然后每隔一段时间整体搬运到博客上面来。
所以还没有关注我微信公众号的同学,请扫描下面的二维码,关注我的公众号,每天一篇原创文章,每天都有新技能 Get。

在上一篇文章里面,我们讲到了如何使用Python的yield关键字简化代码,压平多层嵌套字典的。
那么如果我们的数据不仅仅有字典,还有列表,是一个字典列表多层嵌套的数据怎么办呢?例如:
1 | nest_dict = { |
现在,请停下来,敲一敲代码,想想如何把处理列表的逻辑添加进去。
首先,我们来看一下最终被压平以后的数据长什么样:
1 | {'a': 1, |
对于'n': ['a', 'b', 'c']这种形式的数据,我们把它转换为: {'n_0': 'a', 'n_1': 'b', 'n_2': 'c'}
我们经常遇到各种字典套字典的数据,例如:
1 | nest_dict = { |
有没有什么简单的办法,把它压扁,变成:
1 | { |
写过一段时间代码的同学,应该对这一句话深有体会:程序的时间利用率和空间利用率往往是矛盾的,可以用时间换空间,可以用空间换时间,但很难同时提高一个程序的时间利用率和空间利用率。
但如果你尝试使用生成器来重构你的代码,也许你会发现,在一定程度上,你可以既提高时间利用率,又提高空间利用率。