Elasticsearch批量插入时,存在就不插入
当我们使用 Elasticsearch-py 批量插入数据到 ES 的时候,我们常常使用它的 helpers模块里面的bulk函数。其使用方法如下:
1 | from elasticsearch import helpers, Elasticsearch |
但这种方式有一个问题,它默认相当于upsert操作。如果_id 对应的文档已经在 ES 里面了,那么数据会被更新。如果_id 对应的文档不在 ES 中,那么就插入。
当我们使用 Elasticsearch-py 批量插入数据到 ES 的时候,我们常常使用它的 helpers模块里面的bulk函数。其使用方法如下:
1 | from elasticsearch import helpers, Elasticsearch |
但这种方式有一个问题,它默认相当于upsert操作。如果_id 对应的文档已经在 ES 里面了,那么数据会被更新。如果_id 对应的文档不在 ES 中,那么就插入。
在开发新闻网页正文通用抽取器GNE的过程中,需要对目标网页的源代码进行一些预处理,从而提高正文抓取的准确性。其中之一就是把 <p>标签内部的 <span>标签中的文本,合并到<p>标签中,再删除 <span> 标签。
开发这个项目,源自于我在知网发现了一篇关于自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》)
这篇论文中描述的算法看起来简洁清晰,并且符合逻辑。但由于论文中只讲了算法原理,并没有具体的语言实现,所以我使用 Python 根据论文实现了这个抽取器。并分别使用今日头条、网易新闻、游民星空、观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻做了测试,发现提取效果非常出色,几乎能够达到100%的准确率。
在我以前的一篇文章:一日一技:如何正确移除Selenium中window.navigator.webdriver的值,我讲到了如何在Selenium启动的Chrome中,通过设置启动参数隐藏window.navigator.webdriver,驳斥了网上垃圾文章中流传的使用JavaScript注入的弊端。
由于Selenium启动的Chrome中,有几十个特征可以被识别,所以在爬虫界已经没有以前那么受欢迎了。模拟浏览器的新秀Puppeteer异军突起,逐渐受到了爬虫界的关注。Puppeteer需要使用JavaScript来控制,如果你是用Python,那么就需要使用Pyppeteer.
如果你使用模拟浏览器爬淘宝,你会发现,无论怎么修改参数,Selenium总是可以立刻被识别。但是如果你使用了本文的方法,用Pyppeteer抓取淘宝,你就会发现另外一个广阔的天地。
今天,我们来讲讲如何在Pyppeteer中隐藏window.navigator.webdriver
知乎用户@Manjusaka 在阅读了我的文章《Python正则表达式,请不要再用re.compile了!!!》以后,写了一篇驳文《驳 <Python正则表达式,请不要再用re.compile了!!!>》
今天,我在这里回应一下这篇驳文。首先标题里面,我用的是回,意为回复,而不是继续驳斥@Manjusaka的文章。因为没有什么好驳斥的,他的观点没有什么问题。
首先说明,我自己在公司的代码里面,也会使用re.compile。但是,我现在仍然坚持我的观点,让看这篇文章的人,不要用re.compile。
当我们使用Python从MongoDB里面读取数据时,可能会这样写代码:
1 | import pymongo |
短短4行代码,读取MongoDB里面的每一行数据,然后传入parse_data做处理。处理完成以后再读取下一行。逻辑清晰而简单,能有什么问题?只要parse_data(row)不报错,这一段代码就完美无缺。
但事实并非这样。
看过《Python爬虫开发 从入门到实战》的同学,应该对multiprocessing这个模块比较熟悉,在书上我使用这个模块通过几行代码实现了一个简单的多线程爬虫:
1 | import requests |
运行效果如下图所示:
少数派(https://sspai.com/)是一个以生产力、效率工具为主要内容的数字消费指南平台。由于网站需要盈利,所以他们在网站上有所克制地增加了一些付费内容。如下图所示。

这种付费文章点进去以后,只能看到前几段,然后就需要购买会员才能正常阅读。
作为一个网站需要盈利,因此开设付费内容无可厚非。奈何少数派的付费内容对我毫无吸引力,因此我不希望每次都在首页上看到这些付费文章。
从网页上删除这些付费内容的原理非常简单,在网页上右键,点击“检查”,打开Chrome的开发者工具,如下图所示。
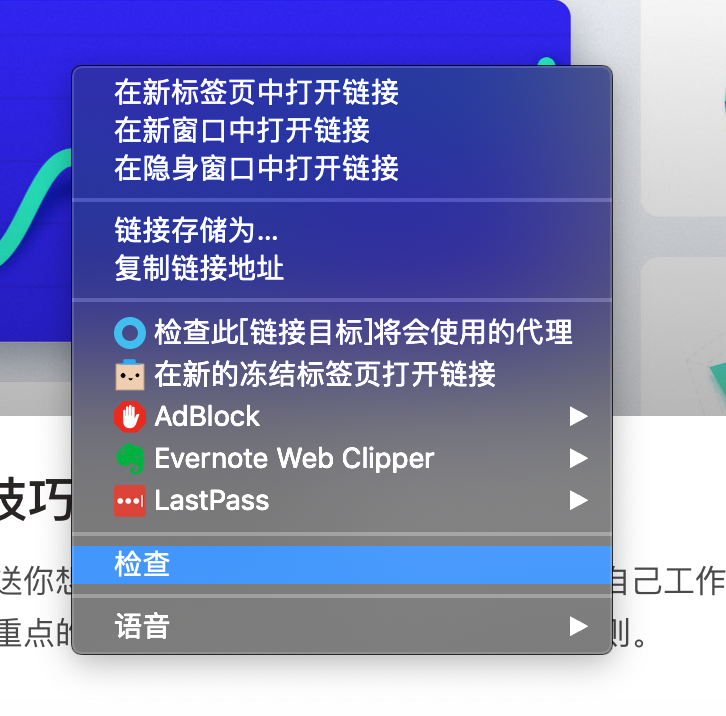
点击箭头所指向的图标,如下图所示:
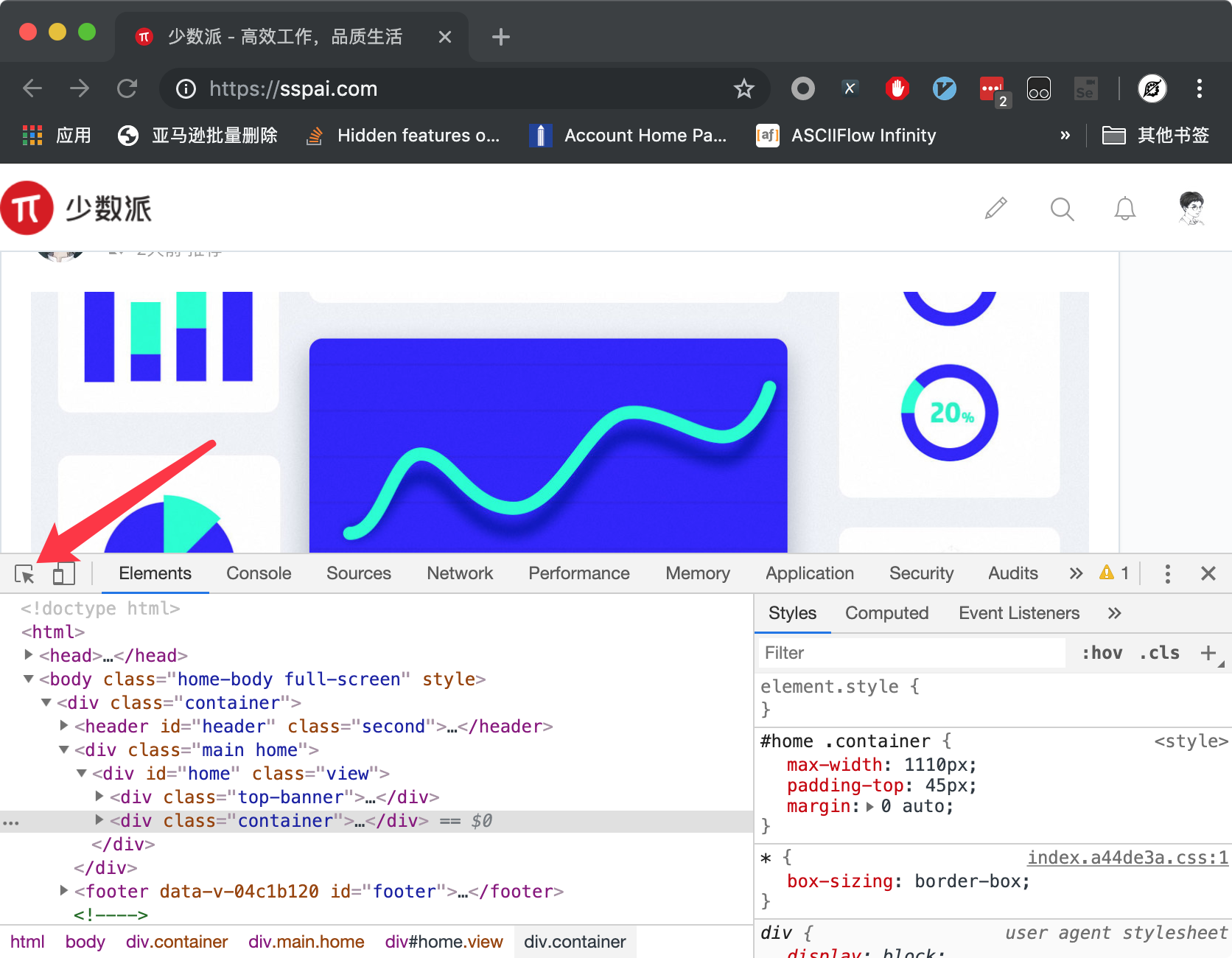
然后在网页上任意选中一个付费内容,此时开发者工具里面将会自动变成下图所示的样子:
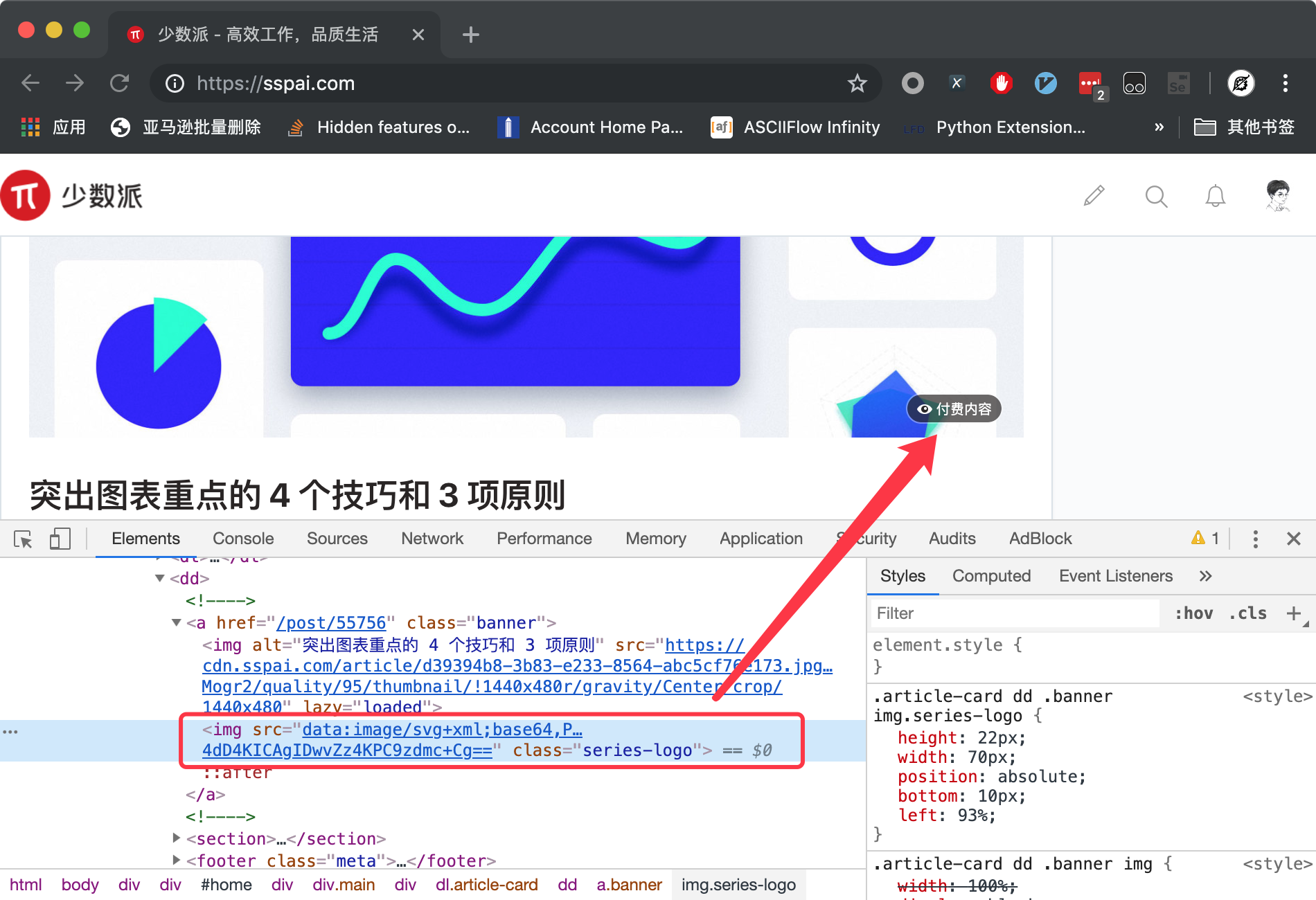
其中方框框住的这个img标签对应了付费内容这个小图标,因此我们可以使用这个标签来进行定位。
现在视线在HTML代码区域往上走,可以看到dl标签

每一个文章块就对应一个dl标签。如果我们在上面右键删除这个标签,就会发现对应的付费条目不见了,如下图所示:
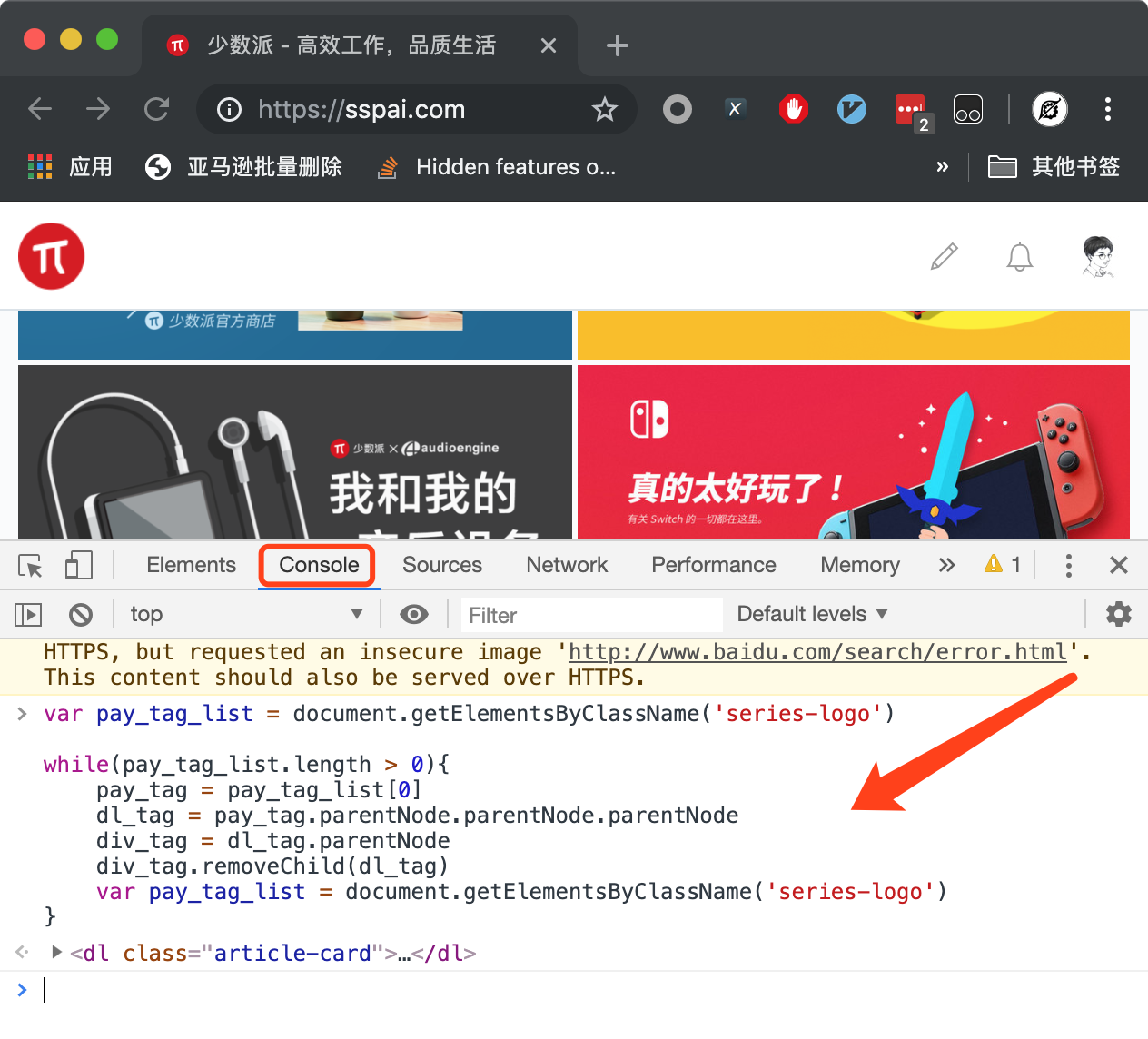
但这种做法每次只能删除一条付费内容,有没有办法把所有付费内容全部删除呢?答案就是使用JavaScript:
1 | var pay_tag_list = document.getElementsByClassName('series-logo') |
复制上面这一段代码到开发者工具的Console标签页并粘贴,敲下回车键,付费内容就消失了,如下图所示。
在Python 3.5(含)以前,字典是不能保证顺序的,键值对A先插入字典,键值对B后插入字典,但是当你打印字典的Keys列表时,你会发现B可能在A的前面。
但是从Python 3.6开始,字典是变成有顺序的了。你先插入键值对A,后插入键值对B,那么当你打印Keys列表的时候,你就会发现B在A的后面。
不仅如此,从Python 3.6开始,下面的三种遍历操作,效率要高于Python 3.5之前:
1 | for key in 字典 |
从Python 3.6开始,字典占用内存空间的大小,视字典里面键值对的个数,只有原来的30%~95%。
Python 3.6到底对字典做了什么优化呢?为了说明这个问题,我们需要先来说一说,在Python 3.5(含)之前,字典的底层原理。
如果你在Google或者百度或者某些技术社区上面搜索uwsgi + Flask,你会发现大量的文章,是教你如何使用uwsgi + flask + Nginx搭建网站。如下图所示:

而且这些文章,全部都像是约定俗成一样,一定会首先用命令行启动uwsgi,测试uwsgi与Flask运行是否正常,然后写uwsgi的配置文件。然后使用Unix 套接字沟通uwsgi与Nginx。所以uwsgi的配置文件里面一定会写成类似于下面这样:
1 | socket = /xxx/yyy/zzz.sock |
Nginx的配置一定有类似于下面这一段:
1 | location / { |
他们为什么要这样写?因为他们看的别的博客上就是这样写的!他们知其然,但是不知其所以然。