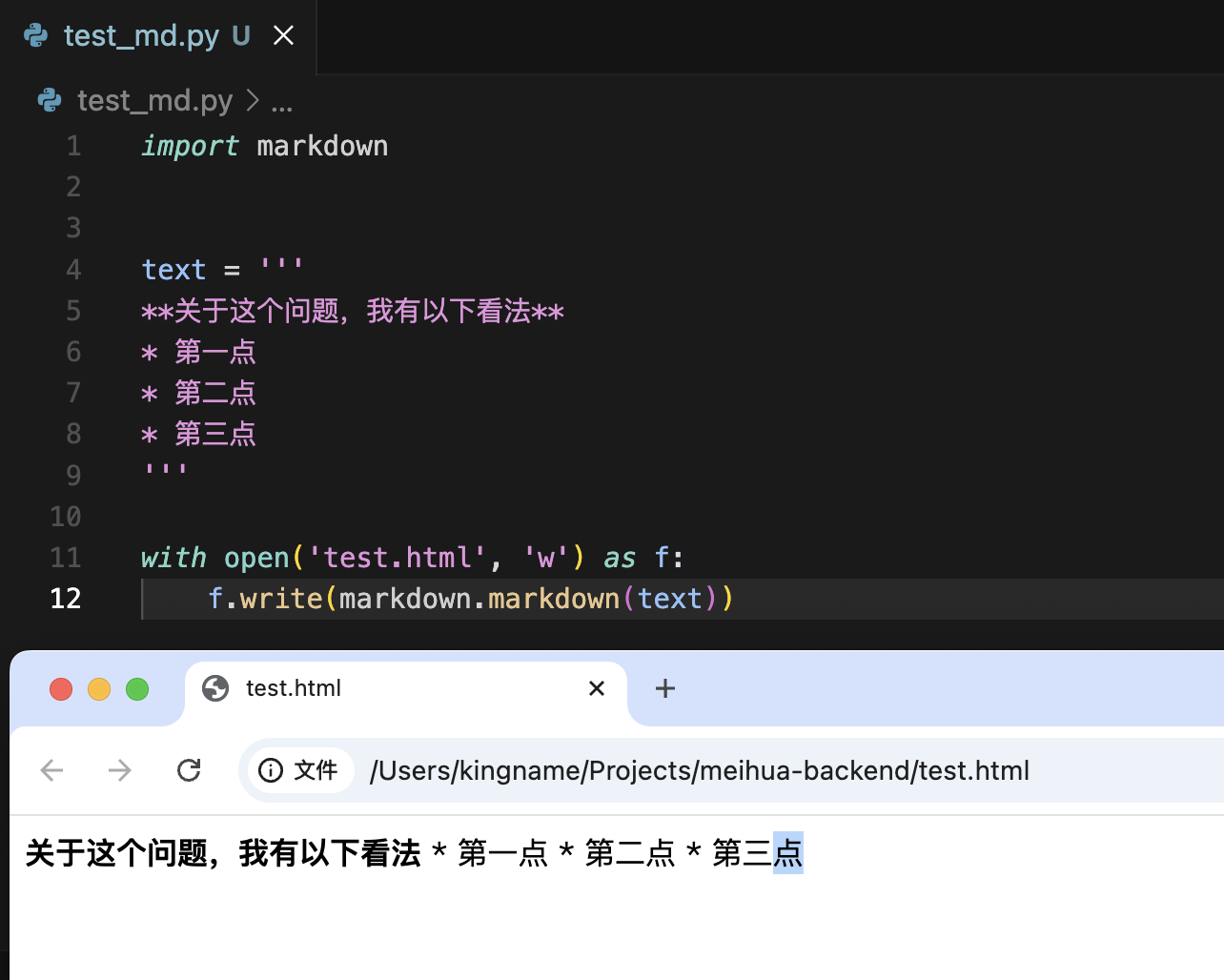
当我们采购数据集时,有时候供应商会以JSON Lines的形式交付给我们。这种格式,本质上是文本格式,它每一行是一个JSON。例如,供应商给我们了一个文件小红书全量笔记.json文件,我们可以使用如下Python代码来一行一行读取:
1
2
3
4
5
6
| import json
with open('小红书全量笔记.json') as f:
for line in f:
info = json.loads(line)
note = info['note']
print('笔记内容为:', note)
|
这个格式的好处在于,每一次只需要把少量内容读取到内存中。即便这个文件有1TB,我们也可以使用一个4GB内存的电脑来处理。
今天出了一个乌龙事件,某数据供应商在给我数据的时候,说的是以JSON Lines格式给我。但我拿过来解压缩以后一看,100GB的文件,里面只有1行,如下图所示:
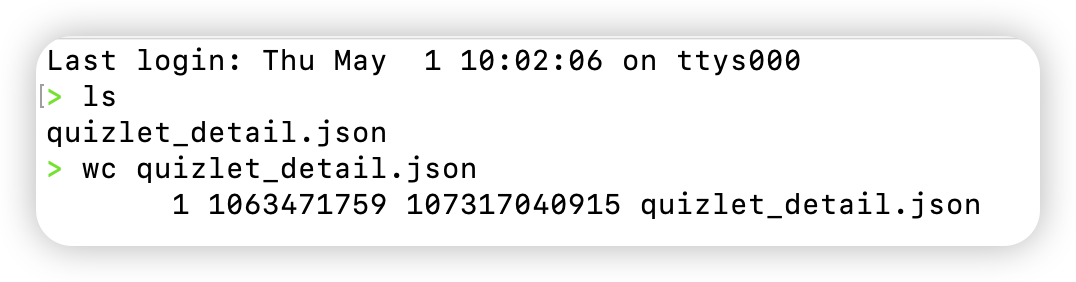
也就是说,他用的是一个超大JSON直接导出给我,并没有使用JSON Lines格式。正常情况下,如果我要直接解析这个数据,需要我的电脑内存超过100GB。
这个大JSON大概格式是这样的:
1
| [{"question": "xxx111", "answer": "aaa", "crawled_time": "2025-05-01 12:13:14"}, {"question": "xxx222", "answer": "aaa", "crawled_time": "2025-05-01 12:13:14"}, {"question": "xxx333", "answer": "aaa", "crawled_time": "2025-05-01 12:13:14"}, ...]
|
要解决这个问题,有三种方法。
如果这个JSON里面没有嵌套数据,只有一层key: value。那么非常简单。一个字符,一个字符读取。遇到}的时候,说明一条子JSON数据已经读取完成,解析以后再读取下一条子JSON。
如果这个JSON里面有嵌套结构,那么可以使用经典算法题里面的数括号算法来解决。当发现}的数量等于{的时候,说明一个子JSON已经读取完成,可以解析了。
今天我们来介绍第三种方法,使用一个第三方库,叫做ijson。它天然支持解析这种超大的JSON,并且代码非常简单:
1
2
3
4
5
6
7
8
9
| import ijson
a = '''
[{"question": "xxx111", "answer": "aaa", "crawled_time": "2025-05-01 12:13:14"}, {"question": "xxx222", "answer": "aaa", "crawled_time": "2025-05-01 12:13:14"}, {"question": "xxx333", "answer": "aaa", "crawled_time": "2025-05-01 12:13:14"}]
'''
items = ijson.items(a, 'item')
for item in items:
print(item)
|
运行效果如下图所示:

既不会占用大量内存,又能正常解析超大JSON。