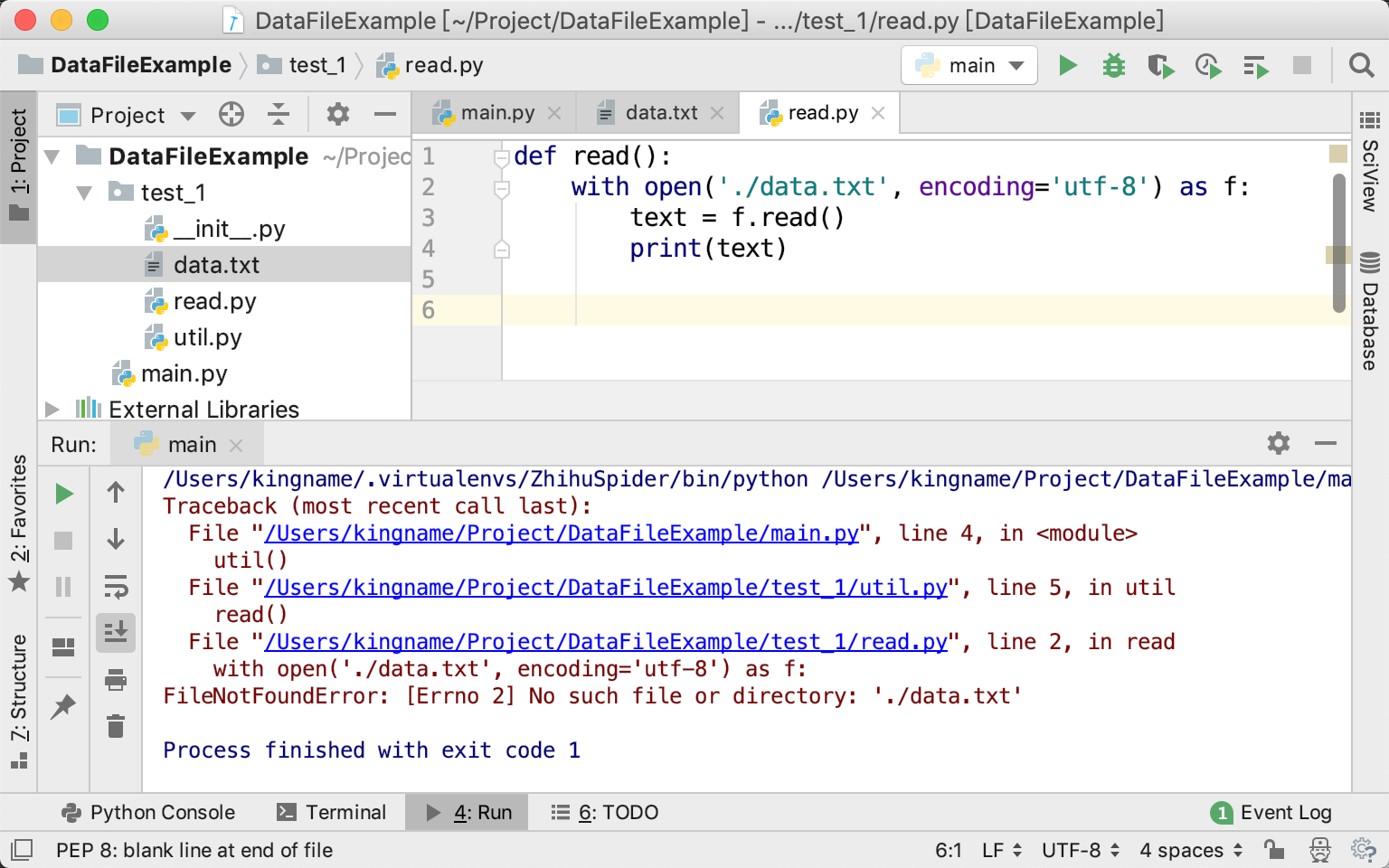
跟着Kenneth Reitz大神学习读取类属性的三种方法
在看Kenneth Reitz大神的Records项目时,注意到在Readme中,读取数据有三种写法:
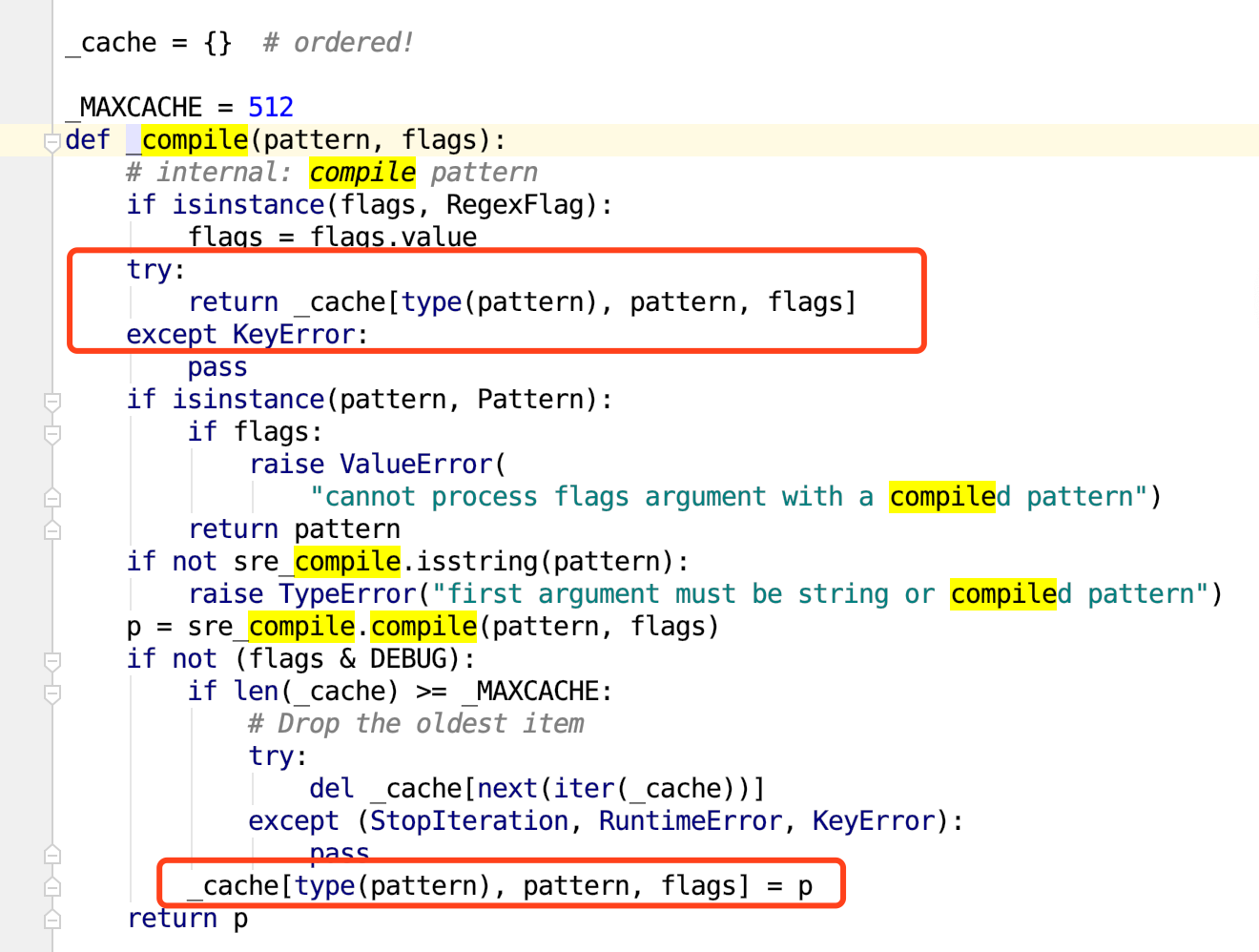
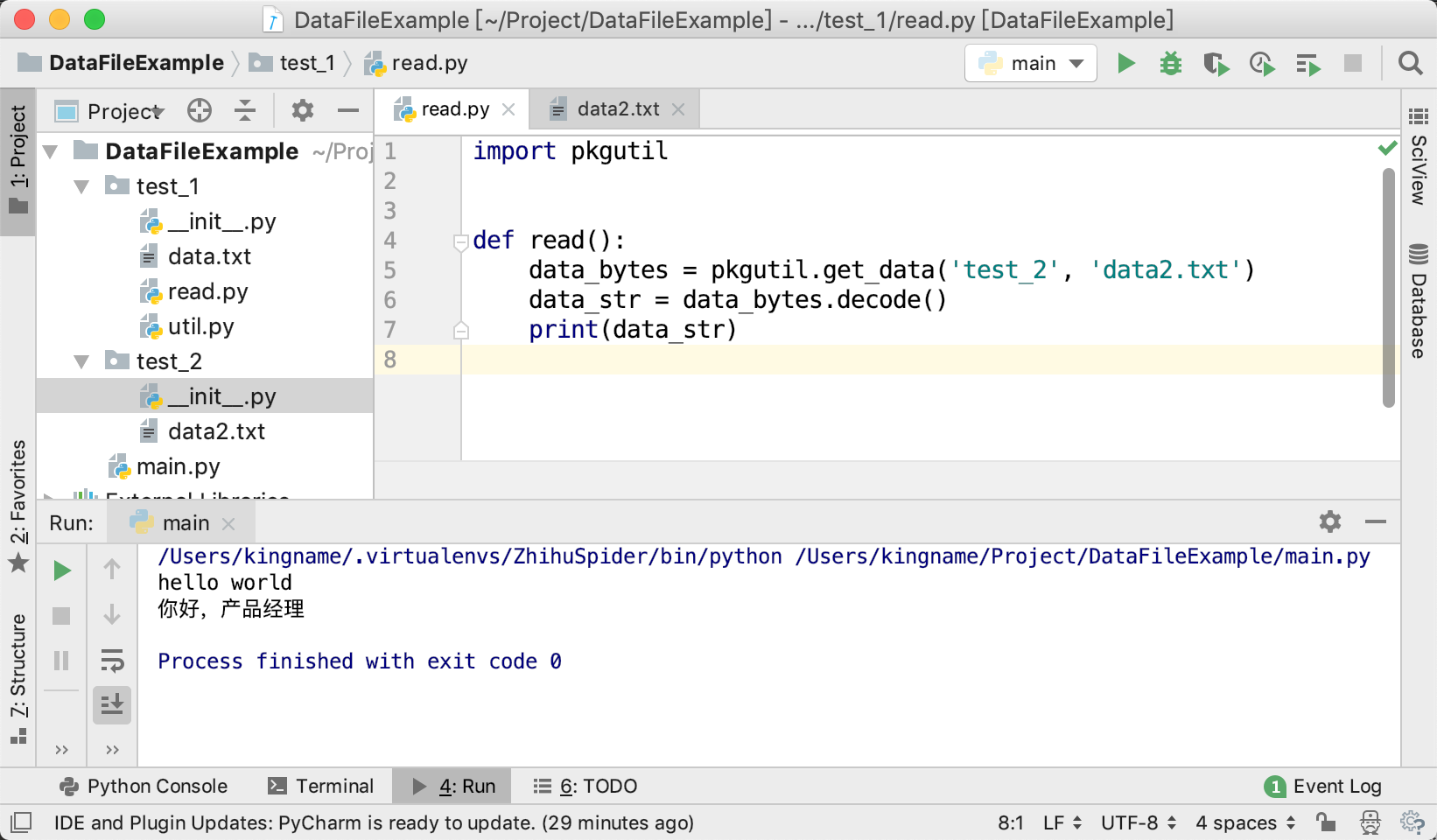
Values can be accessed many ways: row.user_email, row[‘user_email’], or row[3]
假设一个数据表如下所示:
| username | active | name | user_email | timezone |
|---|---|---|---|---|
| model-t | True | Henry Ford | model-t@gmail.com | 2016-02-06 22:28:23.894202 |
那么,当你想读取user_email这一列的时候,除了可以使用row.user_email和row['user_email']以外,由于user_email在第3列(username是第0列),所以还可以使用row[3]来读取。
今天我们就来研究一下,他是如何实现这个功能的。
假设我们现在有一个类:
1 | class People: |
基于这个类初始化一个对象kingname:
1 | kingname = People('kingname', 26) |
运行效果如下图所示:

可以看到,我们已经实现了类似于records项目中的row.user_email的写法。
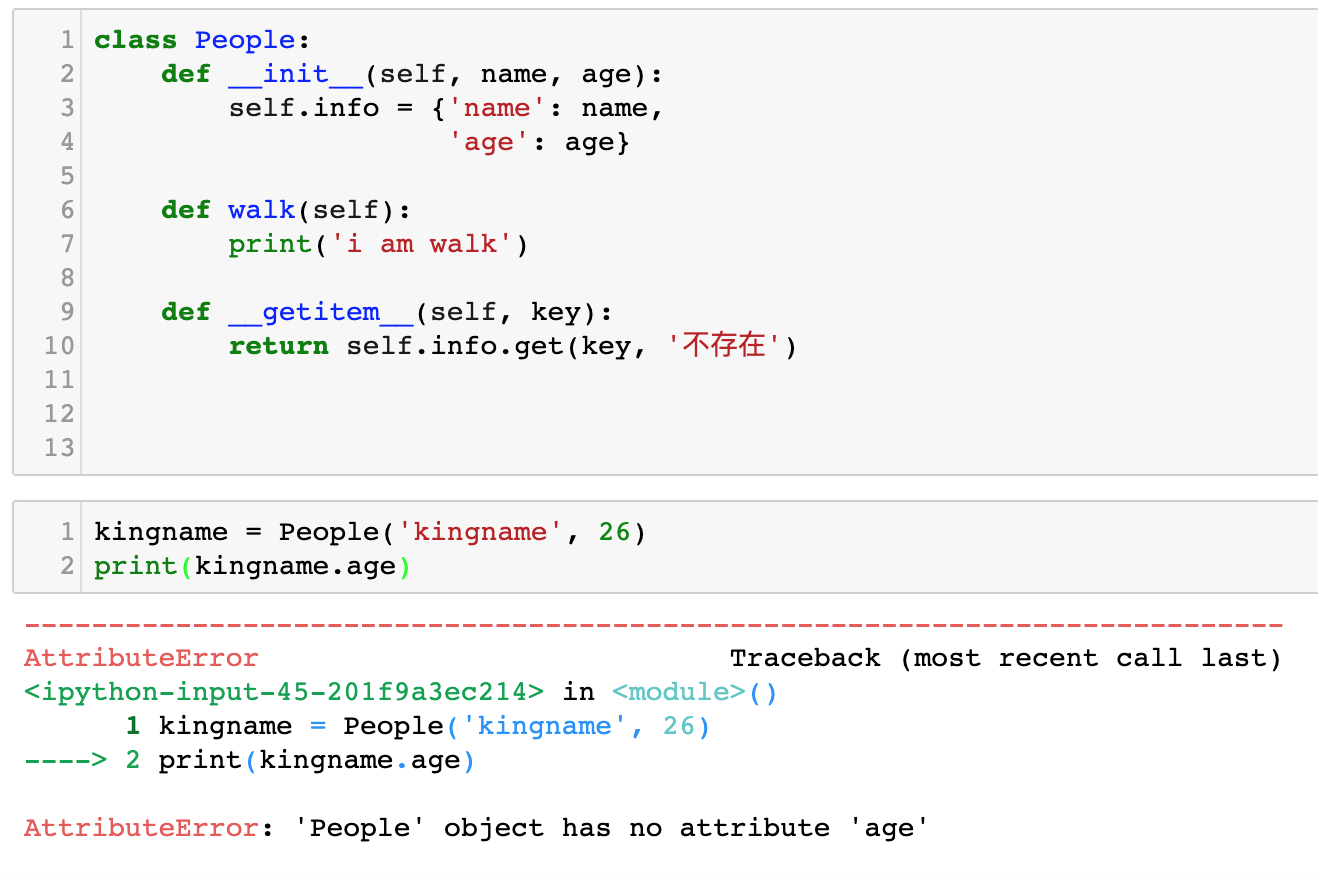
但是当我们想像字典一样取读取的时候,就会报错,如下图所示。

此时,为了让一个对象可以像字典一样被读取,我们需要实现它的__getitem__方法:
1 | class People: |
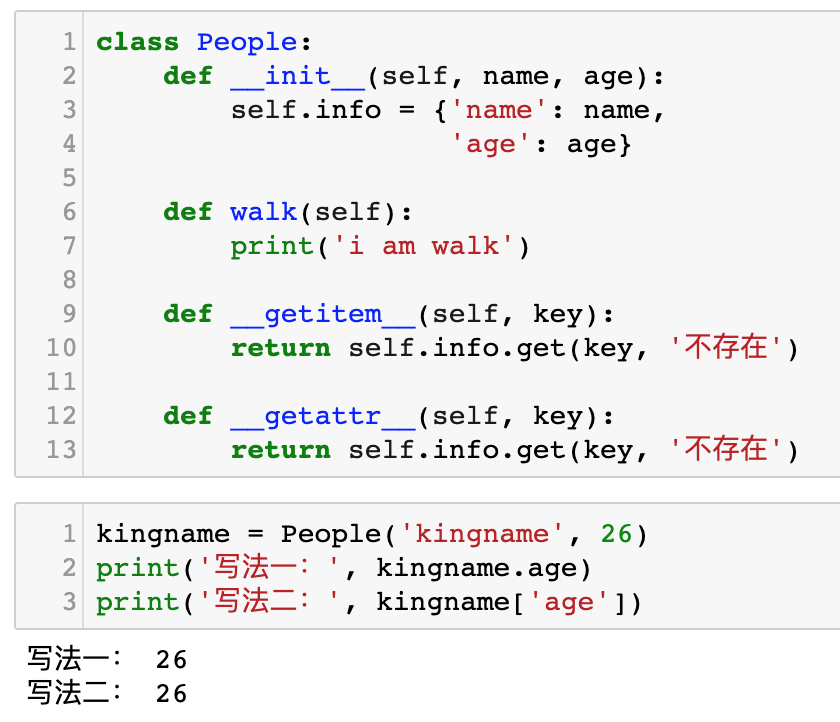
此时就可以像字典一样去读取了,运行效果如下图所示:

但新的问题又来了,不能直接读取使用kinganme.age读取数据了,这样写会导致报错,如下图所示:
为了解决这个问题,我们再来实现这个类的__getattr__方法:
1 | class People: |
运行效果如下图所示:
那么如何实现records里面的row[3]这种写法呢?这就需要先解释一下,records这个库是用来做什么的,以及它的数据是如何存放的。
K大写的records这个库,是用于来更加方便地读写SQL数据库,避免繁琐地写各种SQL语句。
这个库的源代码只有一个文件:源代码
我们今天要研究的这个写法,在Record这个类里面。这个类用来保存MySQL中的一行数据。Record这个类包含两个属性,分别为_keys和_values,其中_keys用于记录所有的字段名,_values用于记录一行的所有值。字段名和值是按顺序一一对应的。
例如_keys里面下标为3表示字段名user_email,那么_values里面下标为3的数据就是user_email的值。
正式由于这样一个一一对应的关系,所以row[3]才能实现row['user_email']、row.user_email相同的效果。
回到我们的People类,为了实现相同的目的,我们再次修改代码:
1 | class People: |
运行效果如下图所示:
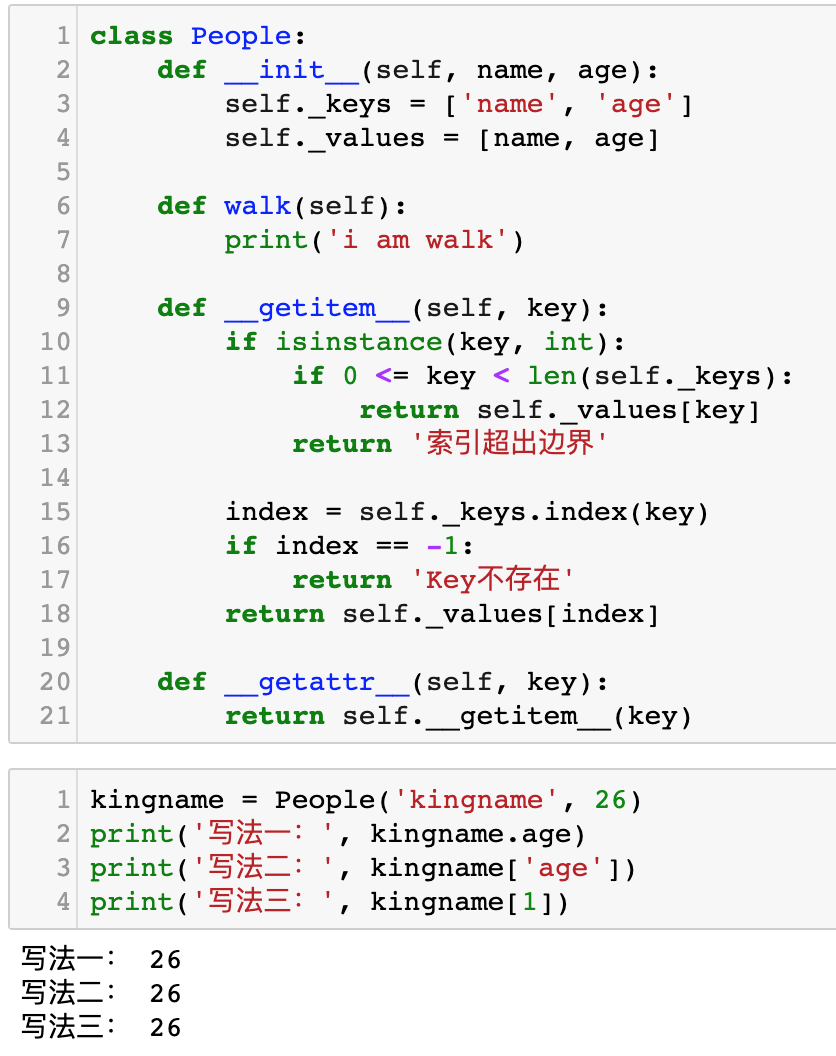
需要说明的是,无论是使用kingname['key']还是kingname[1],他们都会进入到__getitem__方法中去。
我这里给出的例子相较于records项目的代码做了简化,不过关键的部分都已经囊括了进来。
最后,推荐有兴趣的同学通读records这个项目的源代码,你将会从K大的代码中学到非常多的东西。