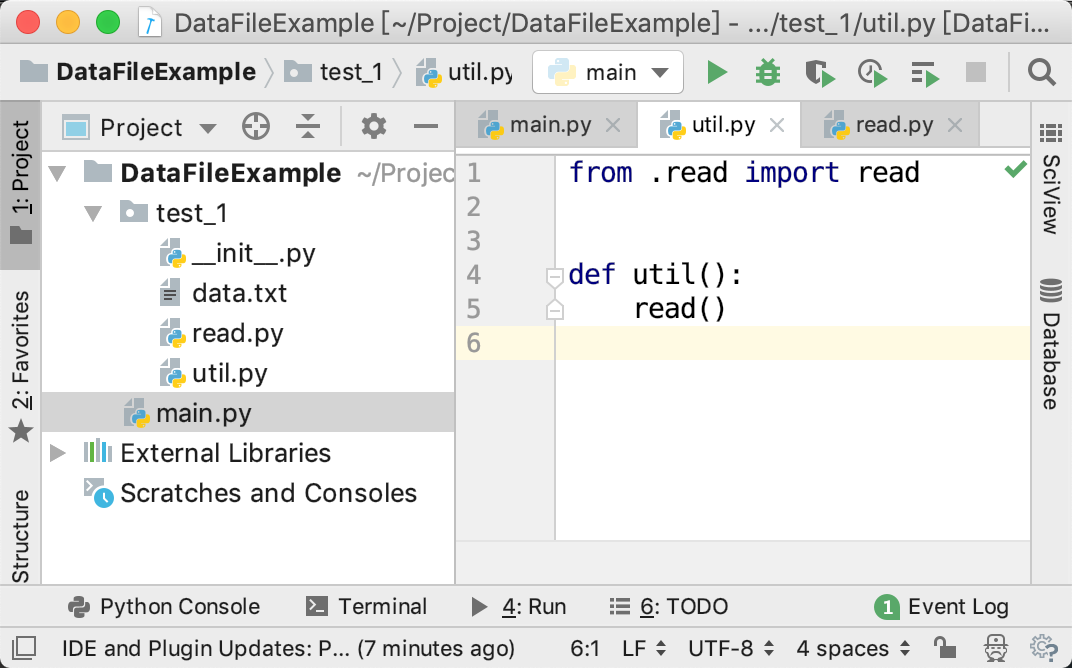
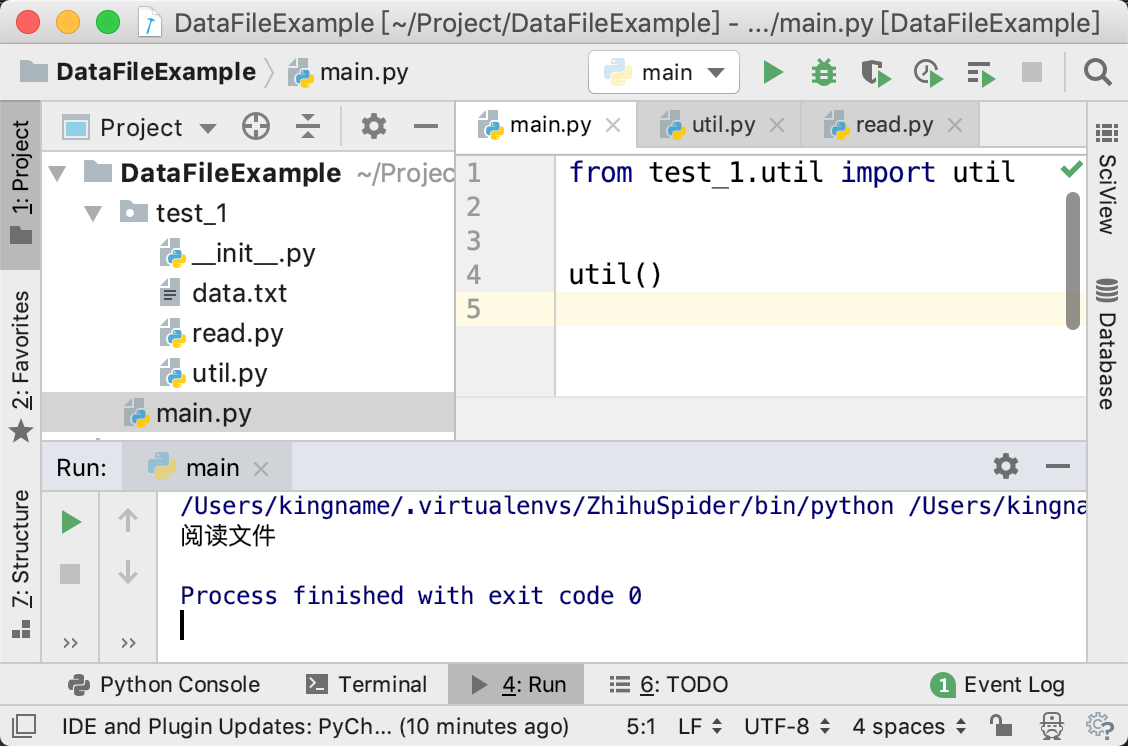
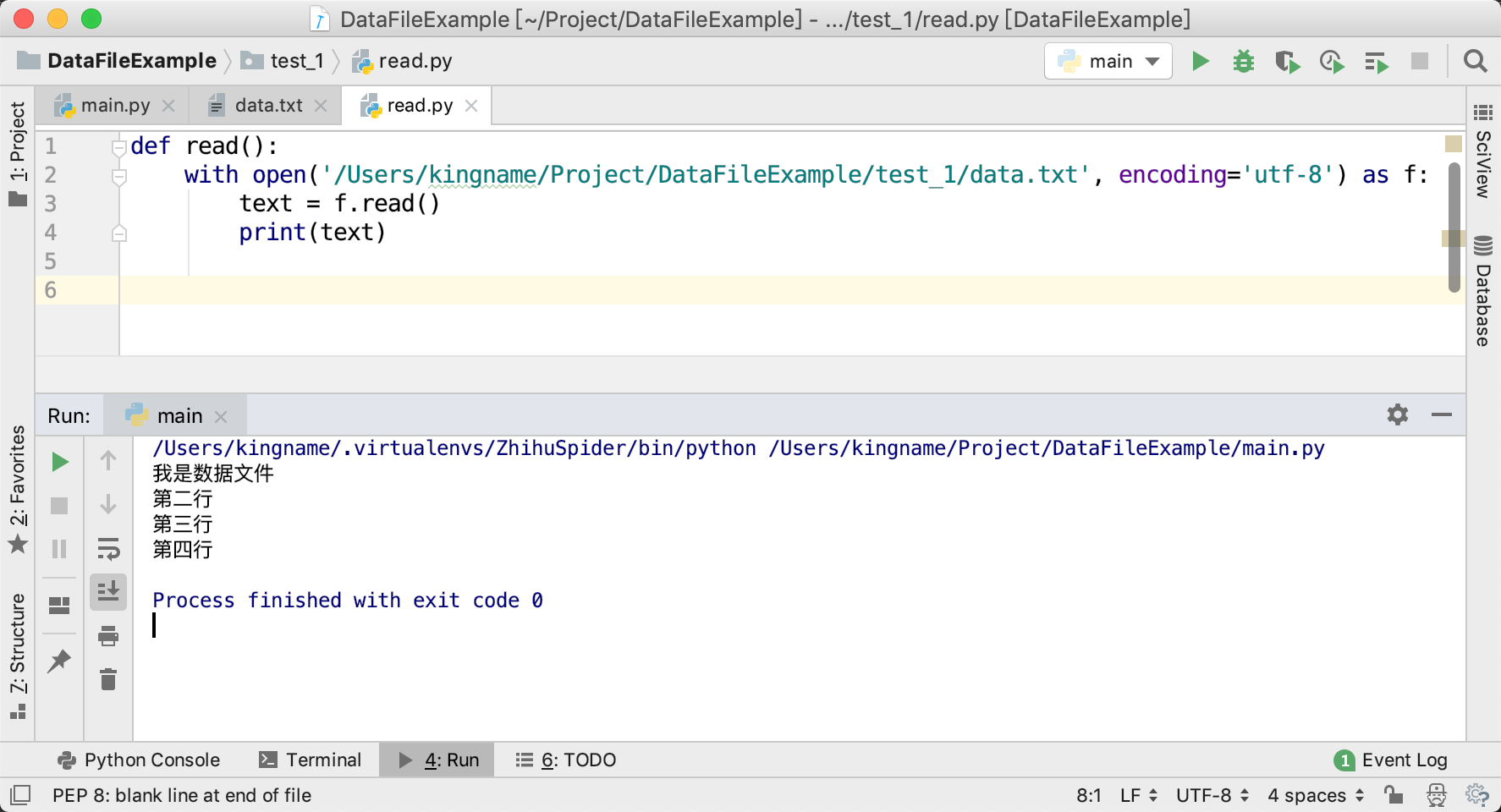
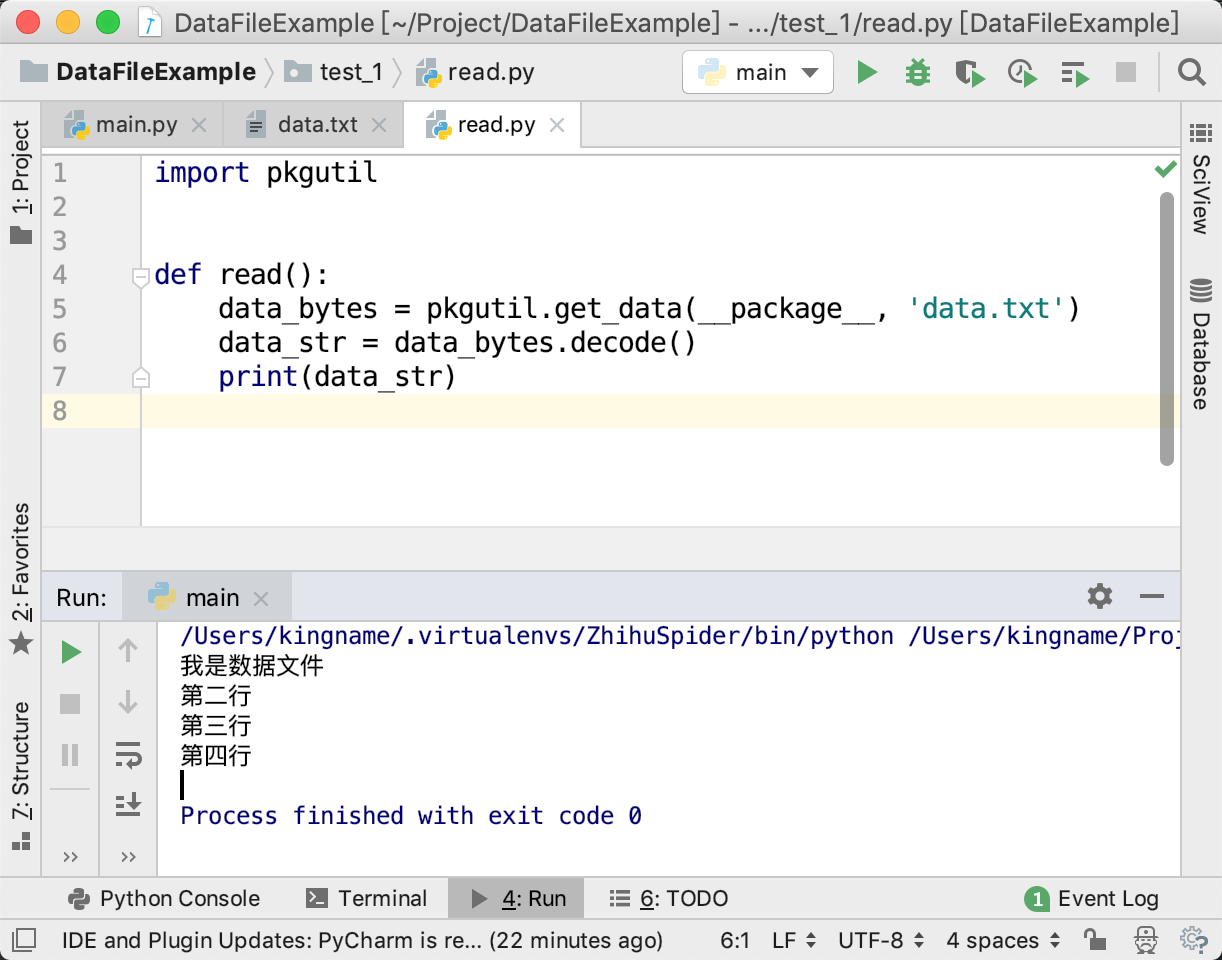
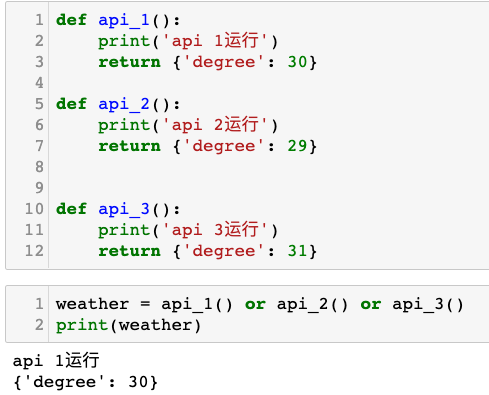
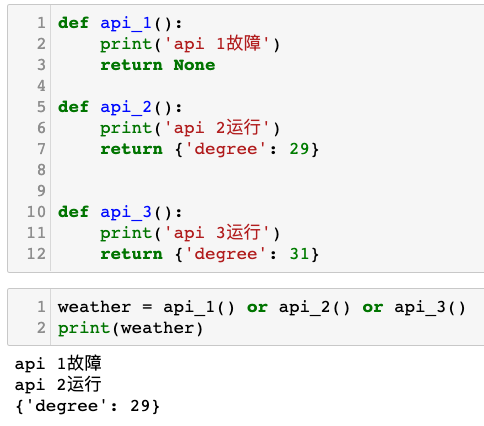
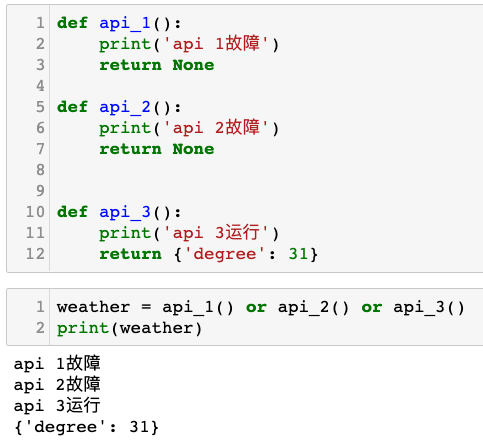
deffindall(pattern, string, flags=0): """Return a list of all non-overlapping matches in the string. If one or more capturing groups are present in the pattern, return a list of groups; this will be a list of tuples if the pattern has more than one group. Empty matches are included in the result.""" return _compile(pattern, flags).findall(string)
如下图所示:
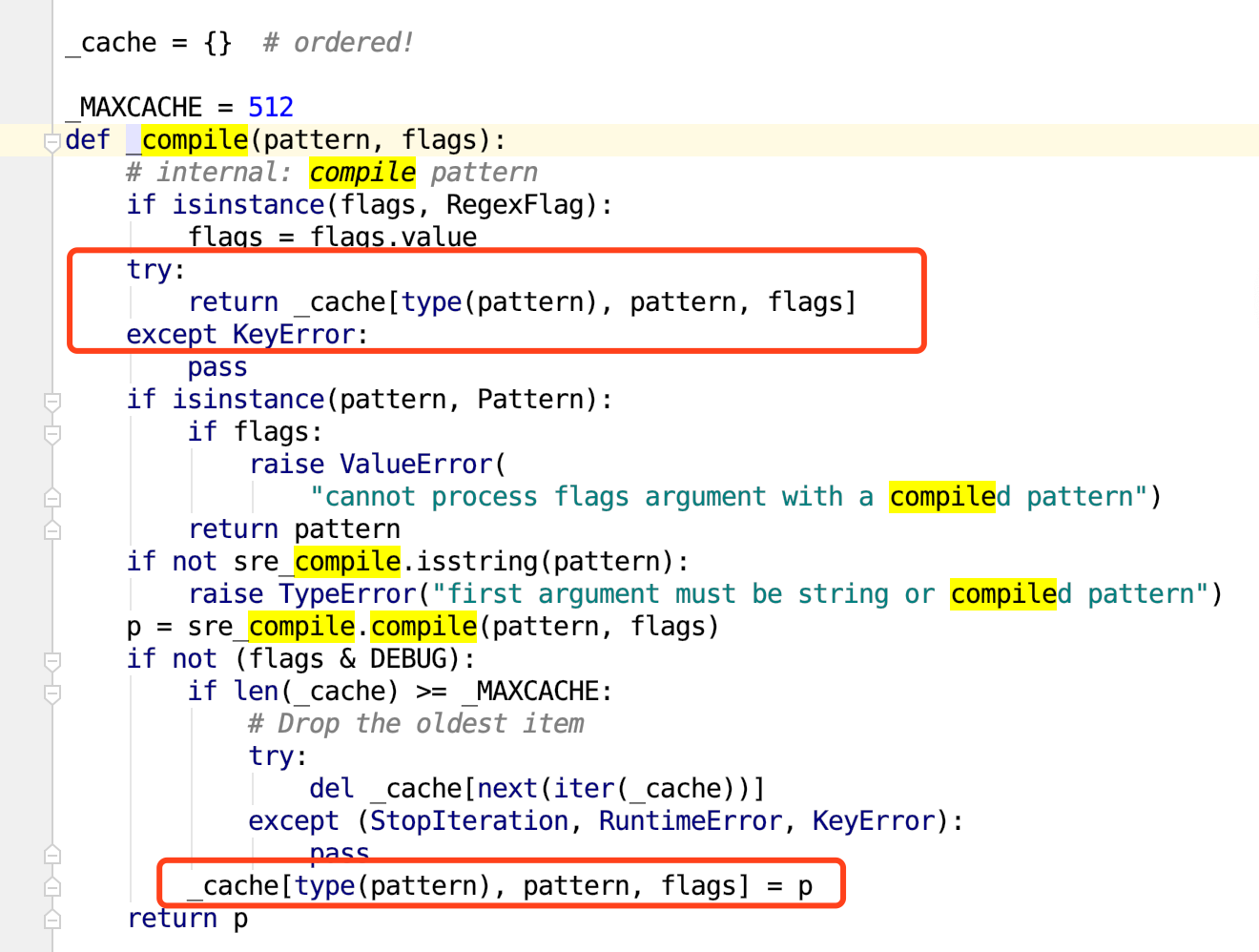
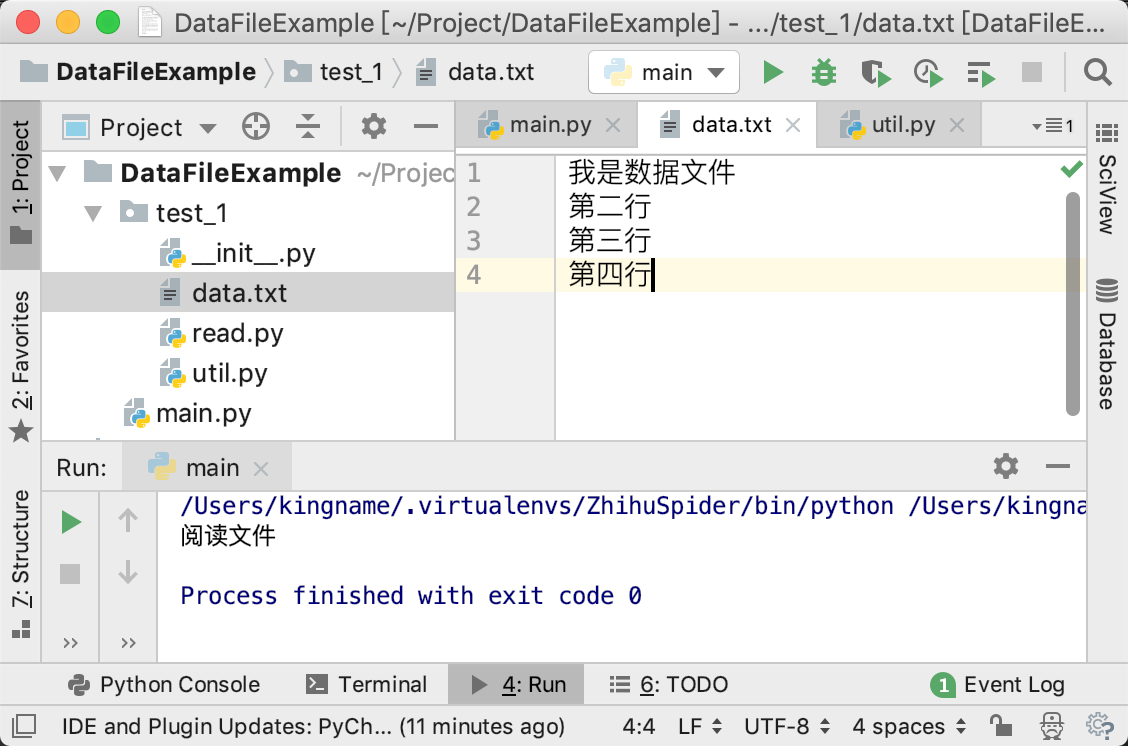
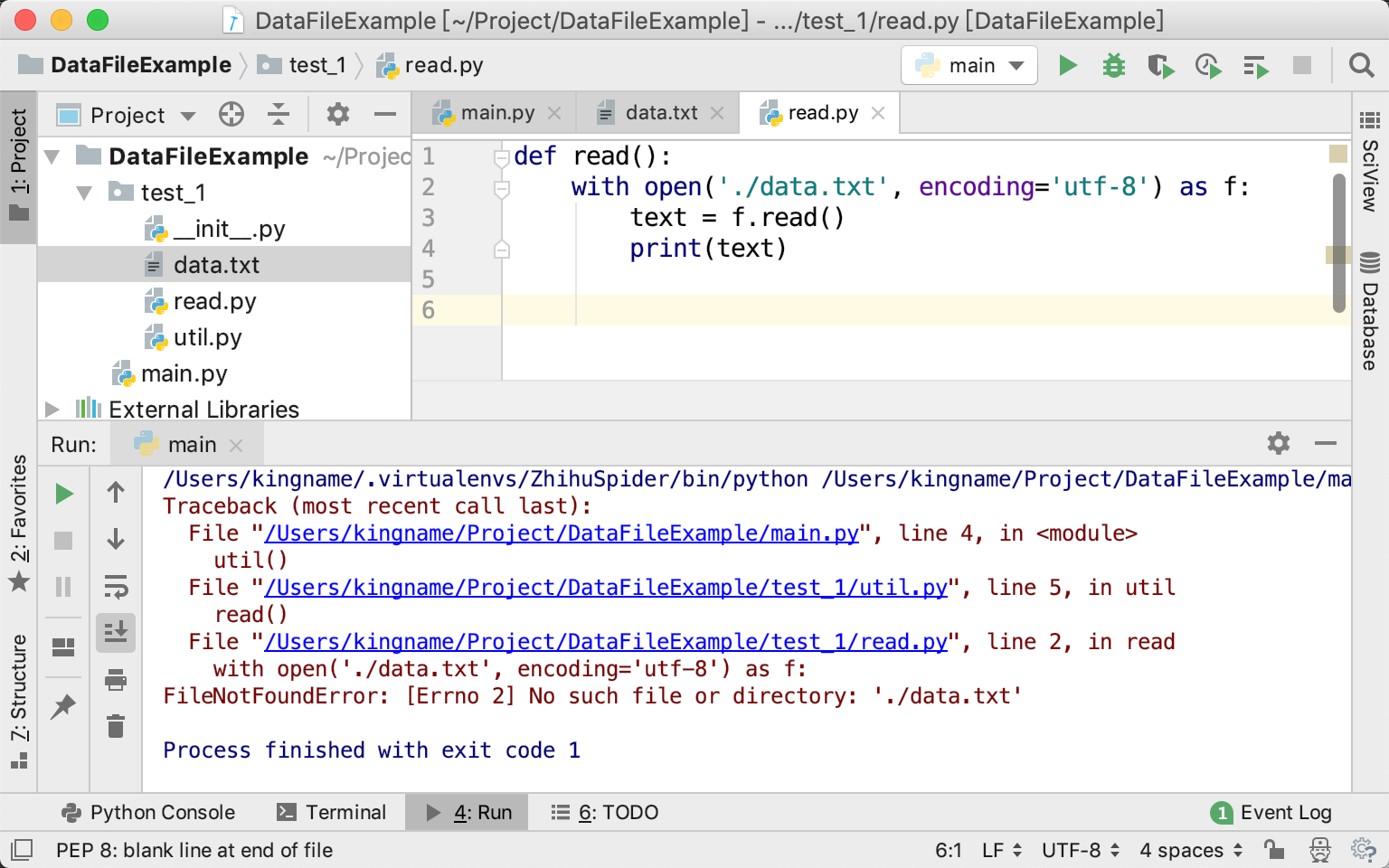
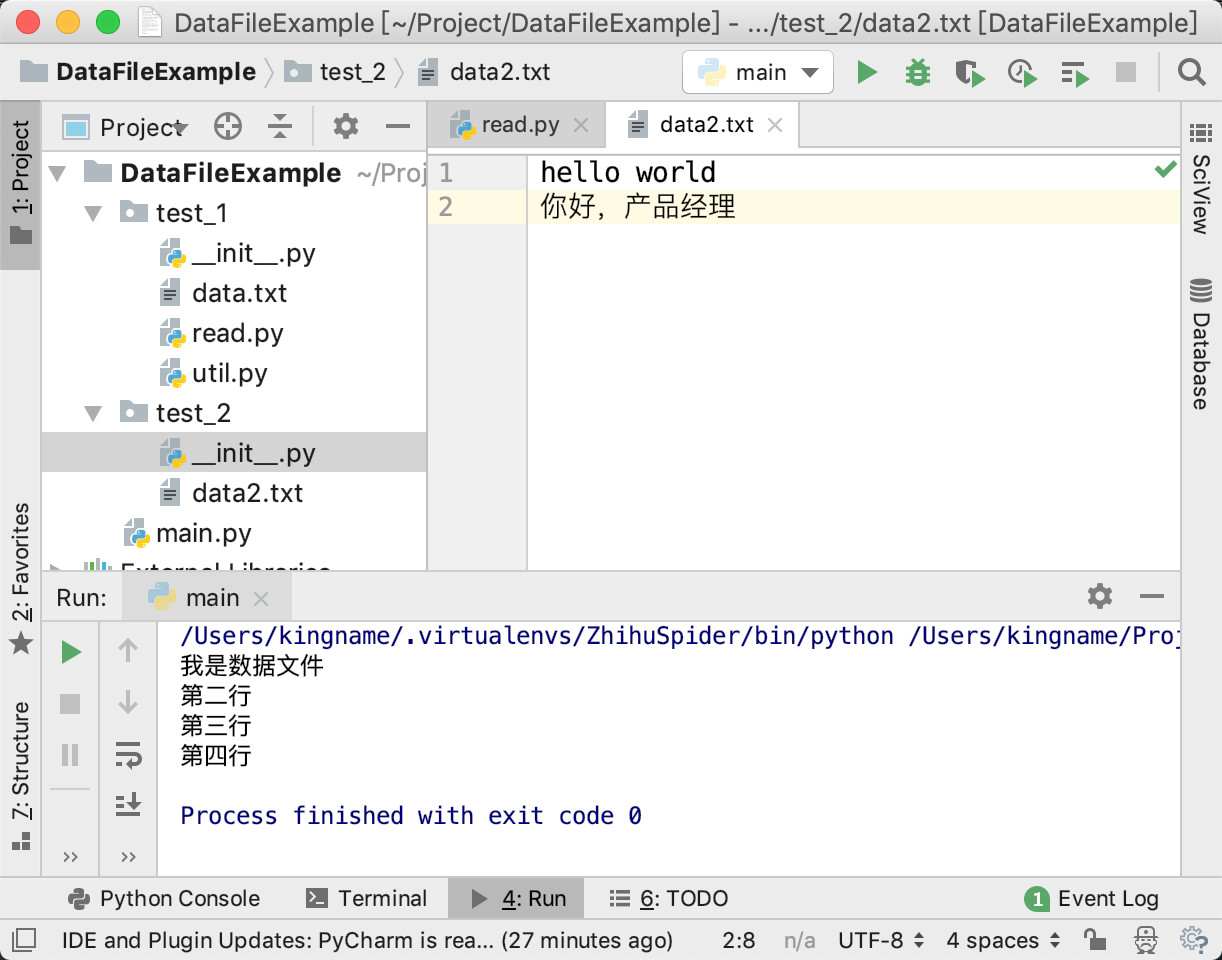
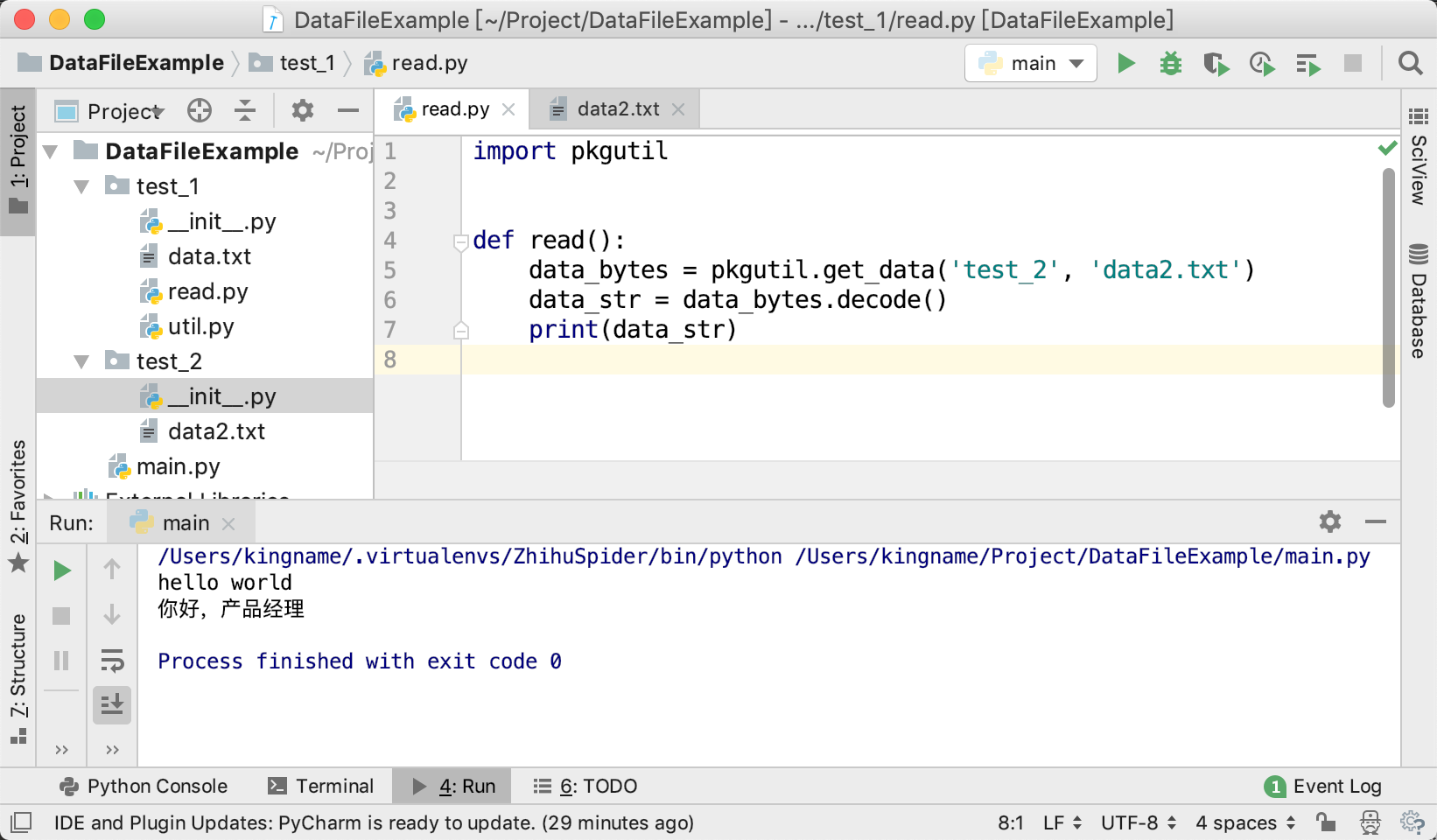
然后我们再来看compile:
1 2 3
defcompile(pattern, flags=0): "Compile a regular expression pattern, returning a Pattern object." return _compile(pattern, flags)
如下图所示:
看出问题来了吗?
我们常用的正则表达式方法,都已经自带了compile了!
根本没有必要多此一举先re.compile再调用正则表达式方法。
此时,可能会有人反驳:
如果我有一百万条字符串,使用某一个正则表达式去匹配,那么我可以这样写代码:
1 2 3 4
texts = [包含一百万个字符串的列表] pattern = re.compile('正则表达式') for text in texts: pattern.search(text)
这个时候,re.compile只执行了1次,而如果你像下面这样写代码:
1 2 3
texts = [包含一百万个字符串的列表] for text in texts: re.search('正则表达式', text)