彻底搞懂Scrapy的中间件(三)
在前面两篇文章介绍了下载器中间件的使用,这篇文章将会介绍爬虫中间件(Spider Middleware)的使用。
在前面两篇文章介绍了下载器中间件的使用,这篇文章将会介绍爬虫中间件(Spider Middleware)的使用。
在上一篇文章中介绍了下载器中间件的一些简单应用,现在再来通过案例说说如何使用下载器中间件集成Selenium、重试和处理请求异常。
中间件是Scrapy里面的一个核心概念。使用中间件可以在爬虫的请求发起之前或者请求返回之后对数据进行定制化修改,从而开发出适应不同情况的爬虫。
“中间件”这个中文名字和前面章节讲到的“中间人”只有一字之差。它们做的事情确实也非常相似。中间件和中间人都能在中途劫持数据,做一些修改再把数据传递出去。不同点在于,中间件是开发者主动加进去的组件,而中间人是被动的,一般是恶意地加进去的环节。中间件主要用来辅助开发,而中间人却多被用来进行数据的窃取、伪造甚至攻击。
在Scrapy中有两种中间件:下载器中间件(Downloader Middleware)和爬虫中间件(Spider Middleware)。
这一篇主要讲解下载器中间件的第一部分。

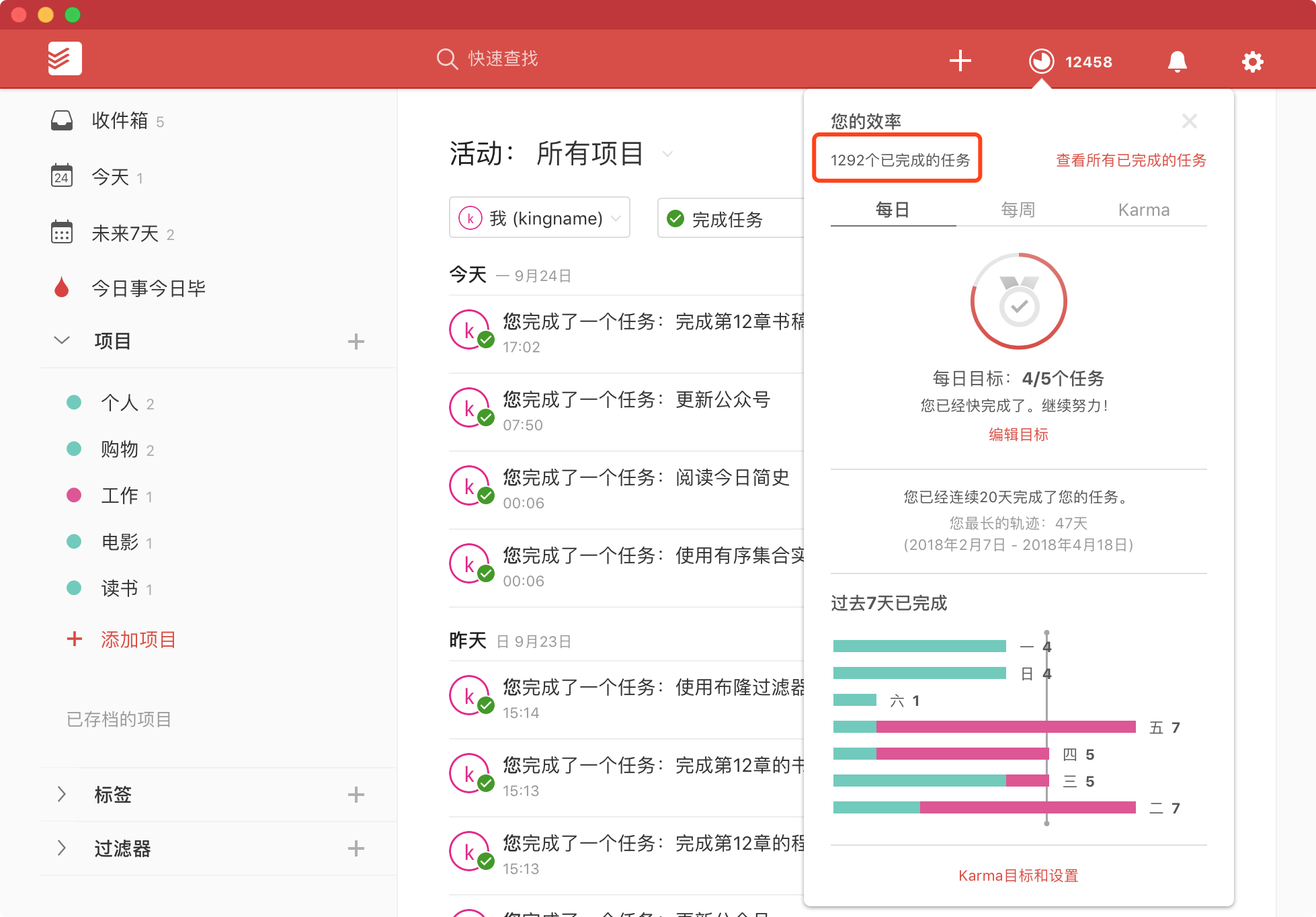
写这篇文章,我不是要黑任何一个任务管理类的App或者方法论。相反,我是一个工具控,在试用各种任务管理类App上总是不遗余力。常见的Things 3,Todoist,Teambition,Trello,Any.do,Doit.im我都试用过。最后,我选择了Todoist,在Todoist上,我已经完成了1292个任务。如下图所示。

以CSDN为首,知乎其次,cnblog带路的一大批博客上充斥着大量低质量的编程入门教程,代码粗制滥造,毫无缩进,没有高亮,东抄西抄。初学者如果长期参照这种垃圾博客来解决问题,将会适得其反,走入歧途。
其实,初学者最应该看的,是编程软件的官方文档,是软件工具的官方文档,是开源项目的官方文档……
但是鉴于有一些文档没有中文翻译,让不少不会英文的同学望而却步。
为此,我将会启动英文文档代查、翻译计划。
如果你想学习一门编程语言,但是它没有官方中文文档;如果你想实现一个功能,但是官方教程对API的描述是英文;如果你想用一个软件,但是这个软件没有中文说明书;如果你想参与一个开源项目,但是看不懂上面的英文讨论……那么你可以在这个公众号上获得帮助。
扫描本文末尾的微信公众号二维码添加未闻Code,公众号私聊中,把你的诉求发送给我。我帮你寻找官方文档,帮你翻译,然后用公众号文章的形式发布出来,让更多人看到。
例如:
1 | #文档翻译#我想知道Scrapy的下载器中间件中,process_response可以返回哪些数据。 |
如下图所示。

总之,你的需求越具体,我就越能找到你需要的内容并为你翻译。
当然,你也可以尝试给我发送一些非技术性的内容,例如《经济学人》《华盛顿邮报》中的具体某个段落,如果我有时间的话,也会帮你翻译。
我会汇总每一周的请求,并在周六更新的公众号文章中,为你呈现你需要的结果。
本计划完全免费。不会以任何形式收取任何费用。不收费不代表没有成本,因此请勿滥用。
请扫描下面的二维码,添加我的微信公众号未闻Code。

在爬虫开发过程中,你肯定遇到过需要把爬虫部署在多个服务器上面的情况。此时你是怎么操作的呢?逐一SSH登录每个服务器,使用git拉下代码,然后运行?代码修改了,于是又要一个服务器一个服务器登录上去依次更新?
有时候爬虫只需要在一个服务器上面运行,有时候需要在200个服务器上面运行。你是怎么快速切换的呢?一个服务器一个服务器登录上去开关?或者聪明一点,在Redis里面设置一个可以修改的标记,只有标记对应的服务器上面的爬虫运行?
A爬虫已经在所有服务器上面部署了,现在又做了一个B爬虫,你是不是又得依次登录每个服务器再一次部署?
如果你确实是这么做的,那么你应该后悔没有早一点看到这篇文章。看完本文以后,你能够做到:
1 | docker build -t localhost:8003/spider:0.01 . |
1 | docker service scale spider=500 |
1 | docker service scale spider=0 |
1 | docker build -t localhost:8003/spider:0.02 . |
这篇文章没有代码,请放心阅读。
多年以后,面对人工智能研究员那混乱不堪的代码,我会想起第一次和S君相见的那个遥远的下午。那时的B公司,还是一个仅有6个人的小团队,Mac和显示器在桌上依次排开,大家坐在一起,不需要称呼姓名,转过脸去,对方就知道你在和他说话。一切看起来都那么美好,我们所有人,都希望自己和这个公司能够一起成长。
彼时S君刚从加拿大回来,老板把他介绍给我们,于是S君作为数据产品经理跟我有了项目上的接触。
创业公司里面,每一个人都需要会很多的技艺,于是S君开始自学Python。
有一天,S君问我:“你玩MineCraft吗?“
“玩,但我更喜欢在B站上看别人的世界。”我答道。
“我觉得我现在写程序,像是在玩我的世界。”S君笑着说道。
“是不是觉得你已经掌握了Python的基本语法,看着别人把Python用的溜溜转,而你自己却不知道用它来做什么?”
“是这样的,你懂我。”
“那你学一门杂学吧。”
于是S君被我诱拐过来跟我一起写爬虫。
后来,S君离开了B公司。
三个月后,我也离开了。
从此,我们再也没有见过。
问题的起因来自于一段正则替换。为了从一段HTML代码里面提取出正文,去掉所有的HTML标签和属性,可以写一个Python函数:
1 | import re |
这段代码的使用了正则表达式的替换功能re.sub。这个函数的第一个参数表示需要被替换的内容的正则表达式,由于HTML标签都是使用尖括号包起来的,因此使用<.*?>就可以匹配所有<xxx yyy="zzz">和</xxx>。
第二个参数表示被匹配到的内容将要被替换成什么内容。由于我需要提取正文,那么只要把所有HTML标签都替换为空字符串即可。第三个参数就是需要被替换的文本,在这个例子中是HTML源代码段。
至于re.S,在4年前的一篇文章中我讲到了它的用法:Python正则表达式中的re.S。
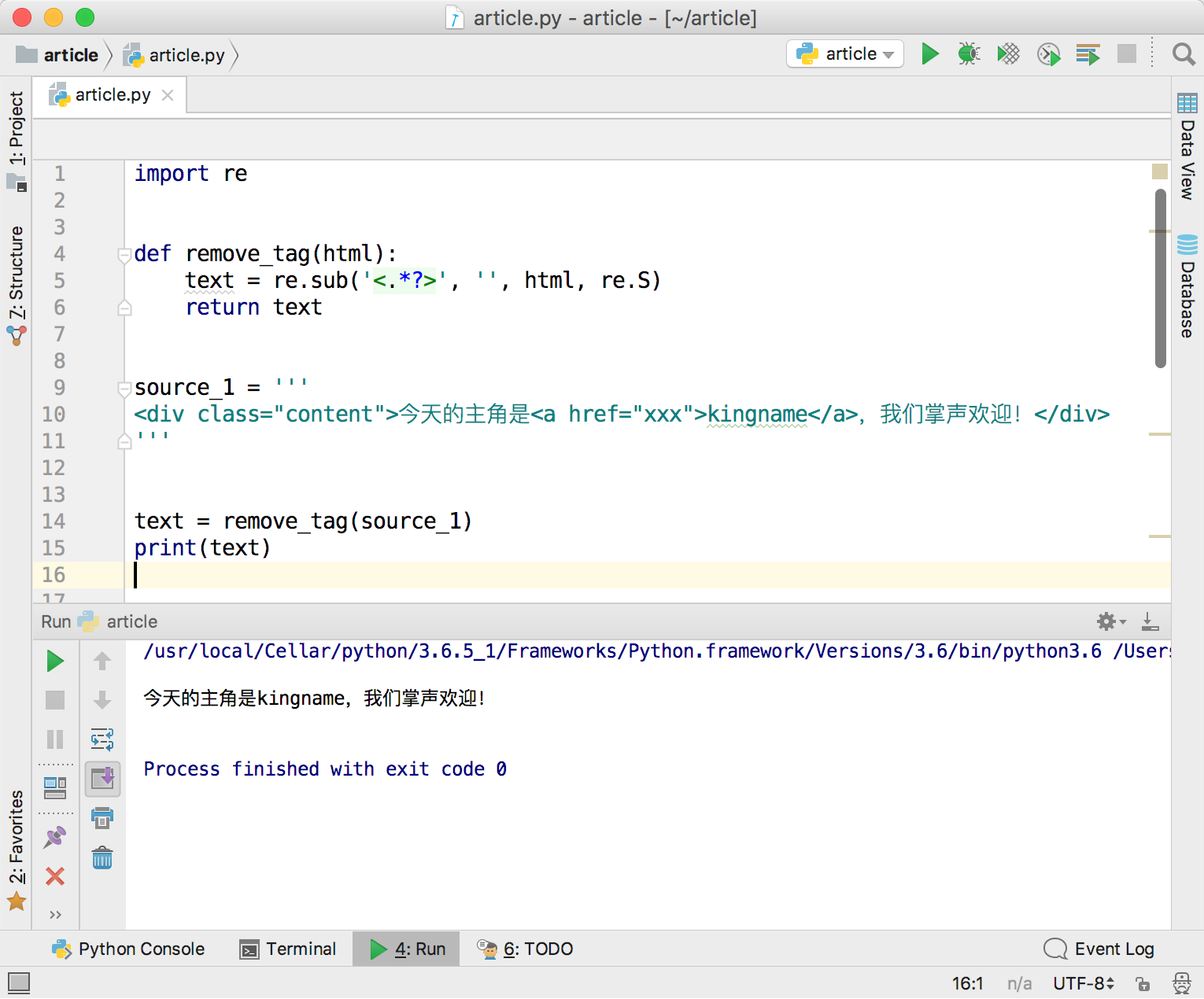
现在使用一段HTML代码来测试一下:
1 | import re |
运行效果如下图所示,功能完全符合预期
再来测试一下代码中有换行符的情况:
1 | import re |
运行效果如下图所示,完全符合预期。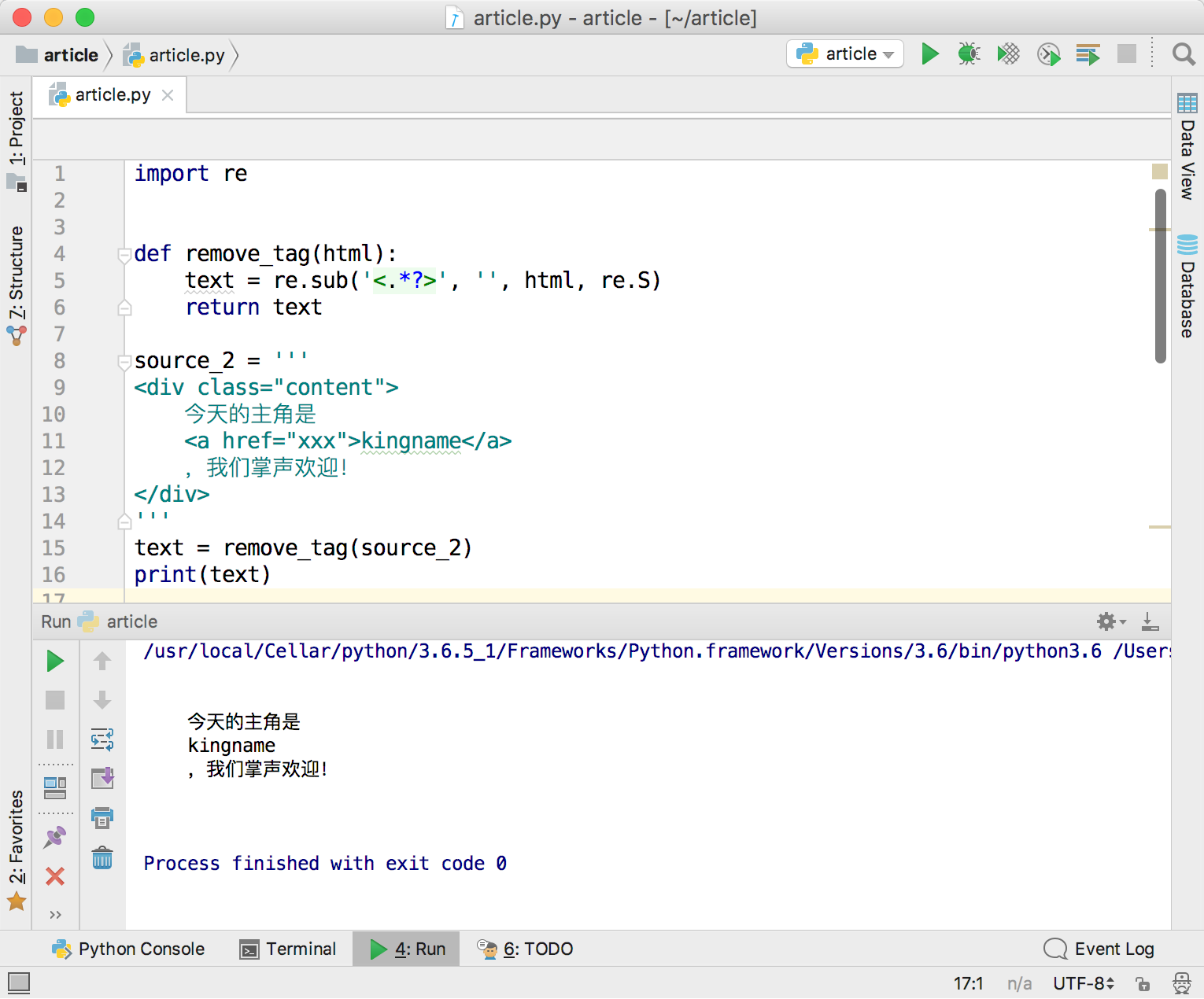
经过测试,在绝大多数情况下,能够从的HTML代码段中提取出正文。但也有例外。
通过本文你会知道Python里面什么时候用yield最合适。本文不会给你讲生成器是什么,所以你需要先了解Python的yield,再来看本文。