正则表达式re.sub替换不完整的问题现象及其根本原因
问题描述
问题的起因来自于一段正则替换。为了从一段HTML代码里面提取出正文,去掉所有的HTML标签和属性,可以写一个Python函数:
1 | import re |
这段代码的使用了正则表达式的替换功能re.sub。这个函数的第一个参数表示需要被替换的内容的正则表达式,由于HTML标签都是使用尖括号包起来的,因此使用<.*?>就可以匹配所有<xxx yyy="zzz">和</xxx>。
第二个参数表示被匹配到的内容将要被替换成什么内容。由于我需要提取正文,那么只要把所有HTML标签都替换为空字符串即可。第三个参数就是需要被替换的文本,在这个例子中是HTML源代码段。
至于re.S,在4年前的一篇文章中我讲到了它的用法:Python正则表达式中的re.S。
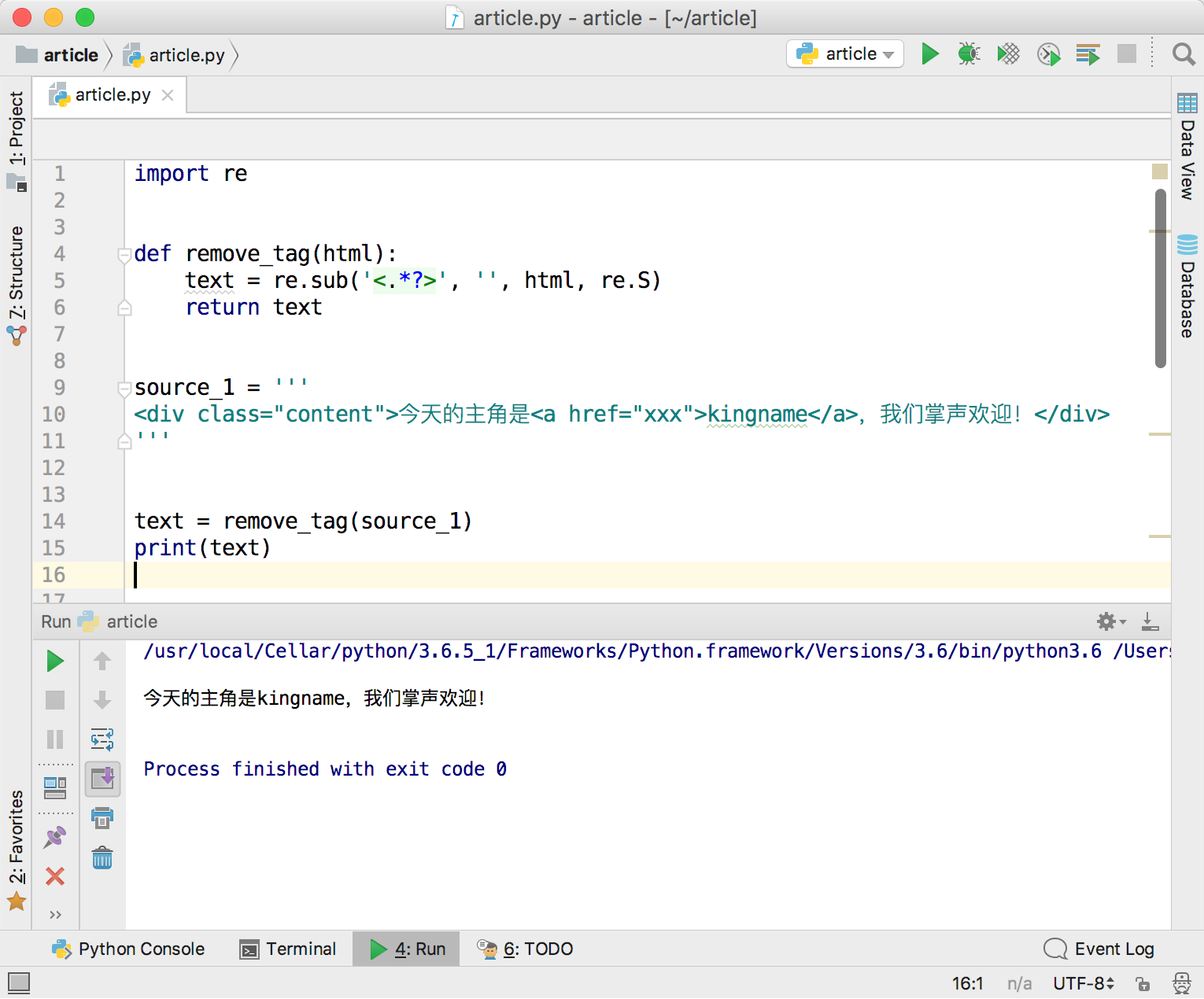
现在使用一段HTML代码来测试一下:
1 | import re |
运行效果如下图所示,功能完全符合预期
再来测试一下代码中有换行符的情况:
1 | import re |
运行效果如下图所示,完全符合预期。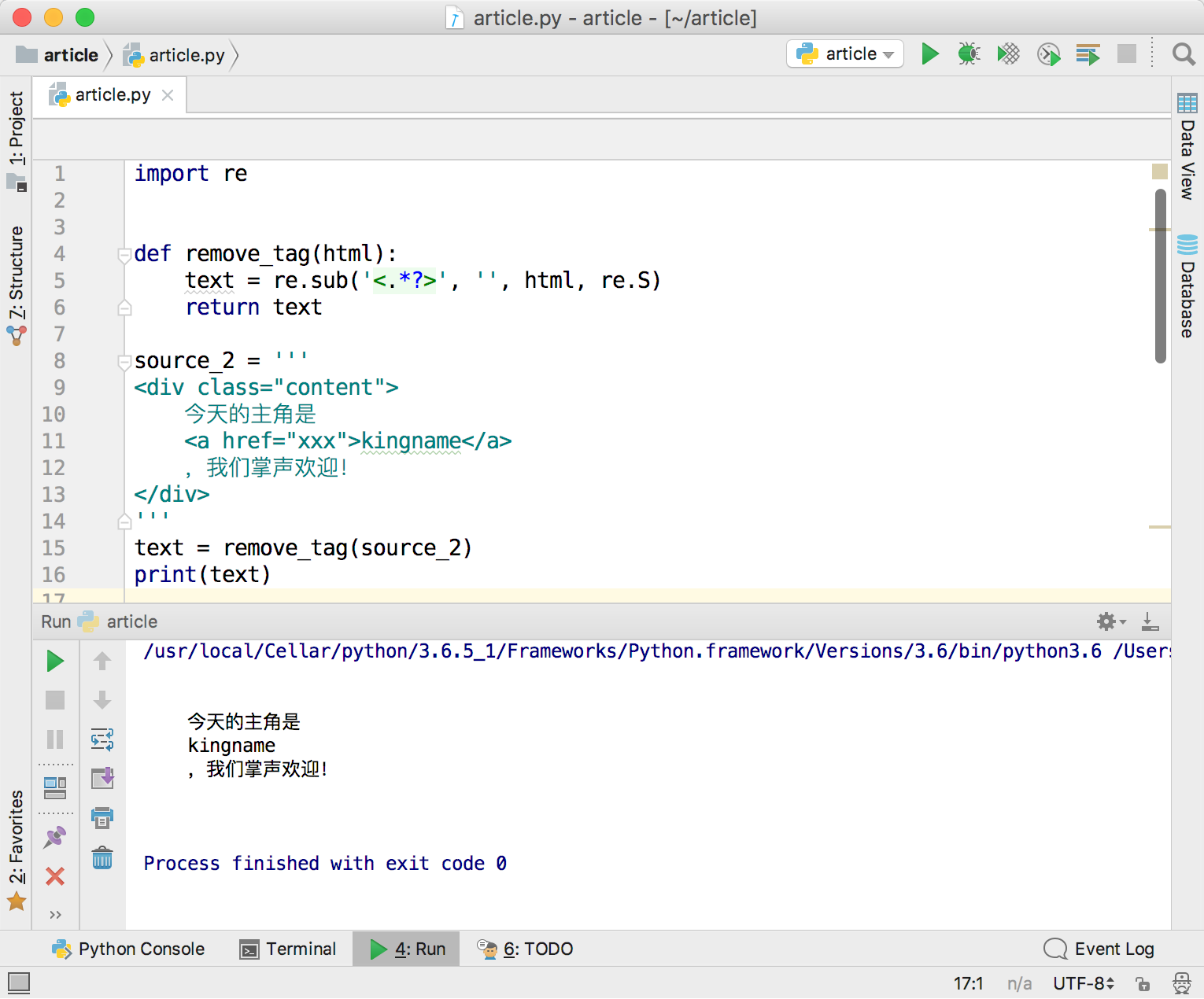
经过测试,在绝大多数情况下,能够从的HTML代码段中提取出正文。但也有例外。