一日一技:真正的自然语言编程
在之前的文章《一次性数据抓取的万能方法,半自动抓取任意异步加载网站》中,我讲到一个万能的爬虫开发方法。从浏览器保存HAR文件,然后写Python代码解析HAR文件来抓取数据。
但可能有同学连Python代码都不想写,他觉得还要学习haralyzer太累了,有没有什么办法,只需要说自然语言,就能解析HAR文件?
最近我在测试open-interpreter,发现借助它,基本上已经可以实现自然语言编程的效果了。今天我们用小红书为例来介绍这个方法。
在之前的文章《一次性数据抓取的万能方法,半自动抓取任意异步加载网站》中,我讲到一个万能的爬虫开发方法。从浏览器保存HAR文件,然后写Python代码解析HAR文件来抓取数据。
但可能有同学连Python代码都不想写,他觉得还要学习haralyzer太累了,有没有什么办法,只需要说自然语言,就能解析HAR文件?
最近我在测试open-interpreter,发现借助它,基本上已经可以实现自然语言编程的效果了。今天我们用小红书为例来介绍这个方法。
我们有时候临时需要抓取一批数据,数据不多,可能就几页,几百条数据。手动复制粘贴太麻烦,但目标网站又有比较强的反爬虫,请求有防重放的验证,写代码抓取也不方便。用模拟浏览器又觉得没必要,只用一次的爬虫,写起来很麻烦。
我经常逛Github Trend,看看每天有没有什么高级的开源项目出来。有时候发现一个项目非常好,想跟开发者交流。
一般情况下,开发者会在Github主页留下自己的联系邮箱,如下图所示,这是我的Github个人主页:
但有的开发者却不会留邮箱,如下图所示:
这种情况下,怎么联系上这个开发者呢?你可以直接发Issue,但是这样其他人就能看到你发的消息。其实还有一个更简单隐蔽的方法,可以直接拿到这个开发者的邮箱。
首先,在这个开发者的Repo中,随便找一条Commit记录,如下图所示:
这个Commit对应的URL是:https://github.com/didi/xiaoju-survey/commit/3dc15aeb688f04dfdf69f0f46b0f66902303f92d。
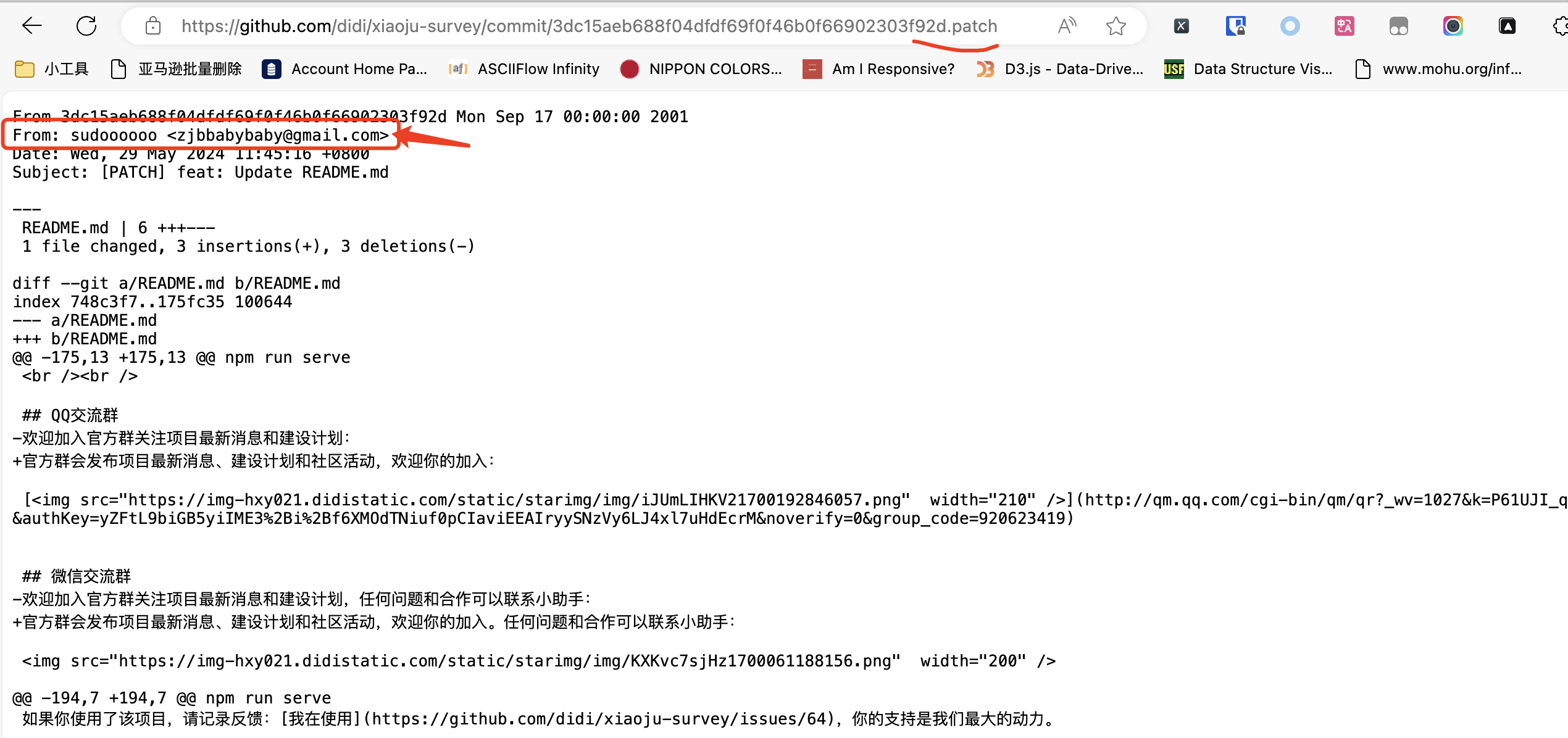
现在,只需要在这个URL的末尾加上.patch,变成https://github.com/didi/xiaoju-survey/commit/3dc15aeb688f04dfdf69f0f46b0f66902303f92d.patch,就可以看到纯文本形式的Commit记录。而开发者的邮箱地址就在上面,如下图所示:
有时候,我们需要使用多行字符串配合format格式化函数来生成Markdown文本。例如,我现在开发了一个AI对话机器人,我发送一个txt文件过去,他首先帮我总结整个文件的内容,然后以问答的形式列出10个要点。
我们知道,Python里面,json.dumps是序列化操作,json.loads是反序列化操作。当我使用json.dumps把一个字典转换为字符串以后,也可以使用json.loads把这个字符串转换为字典。
那么,有没有可能出现这样的情况:某个字典,使用json.dumps转换成了字符串s。但是当我使用json.loads(s)时,却会报错?
利益不相关声明,今天介绍的所有工具,都跟我没有任何软文合作,也没有金钱往来。我在这篇文章里面对他们做介绍仅仅是因为他们对我确实非常有用。
最近几个月,国产大模型相继推出了自己的 App,这些 App 不仅可进行 AI 对话,还能提供各种智能工具。谈论AI对话功能的文章太多了,我就不赘述了。今天聊聊他们的其他功能。不可否认,国产大模型比国外的大模型差了不少,但我一向秉持重器轻用的观点,我不管这些App提供了多少功能,我只看它里面有没有功能适合我,即便它提供了100个功能,我可能只会使用它其中一个适合我的功能。
最近大家都在说LLama3如何如何强大,追赶Claude3,超过GPT 4。但如果大家真的使用过,就会发现它连基本的中文都回答不好。如下图所示: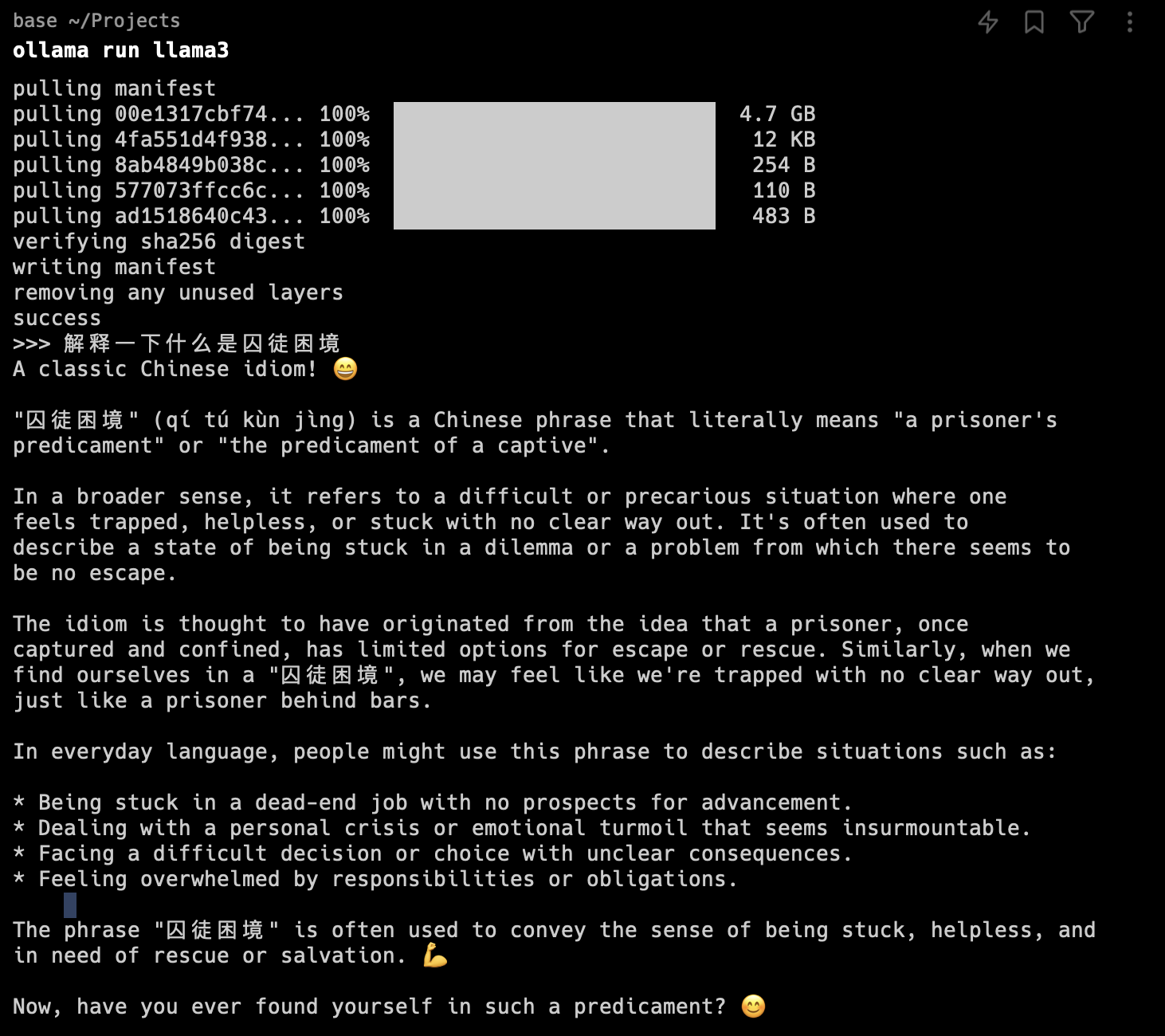 LLama3总是尽可能回复英文,并且还会加很多表情符号。
LLama3总是尽可能回复英文,并且还会加很多表情符号。
在《一日一技:自动提取任意信息的通用爬虫》这篇文章中,我提到可以通过大模型从网页内容里面提取结构化信息。为了节省Token,文章里面我直接提取了页面上的所有文本。
如果你使用macOS,想看上面某个软件使用什么技术开发的。那么你可以使用这个方法。它对普通人来说可能没什么用。如果你本来就做macOS软件开发,那么这个方法可能会很有用。
首先,我们知道macOS上面,安装的软件一般都放在/Applications/或者~/Applications文件夹里面。这里我以阿里网盘为例。
