
一日一技:怎么中文也属于字母?
我最近在使用一个第三方库,叫做RapidFuzz。它有一个工具函数,叫做utils.default_process,在官方文档里面,是这样介绍的:
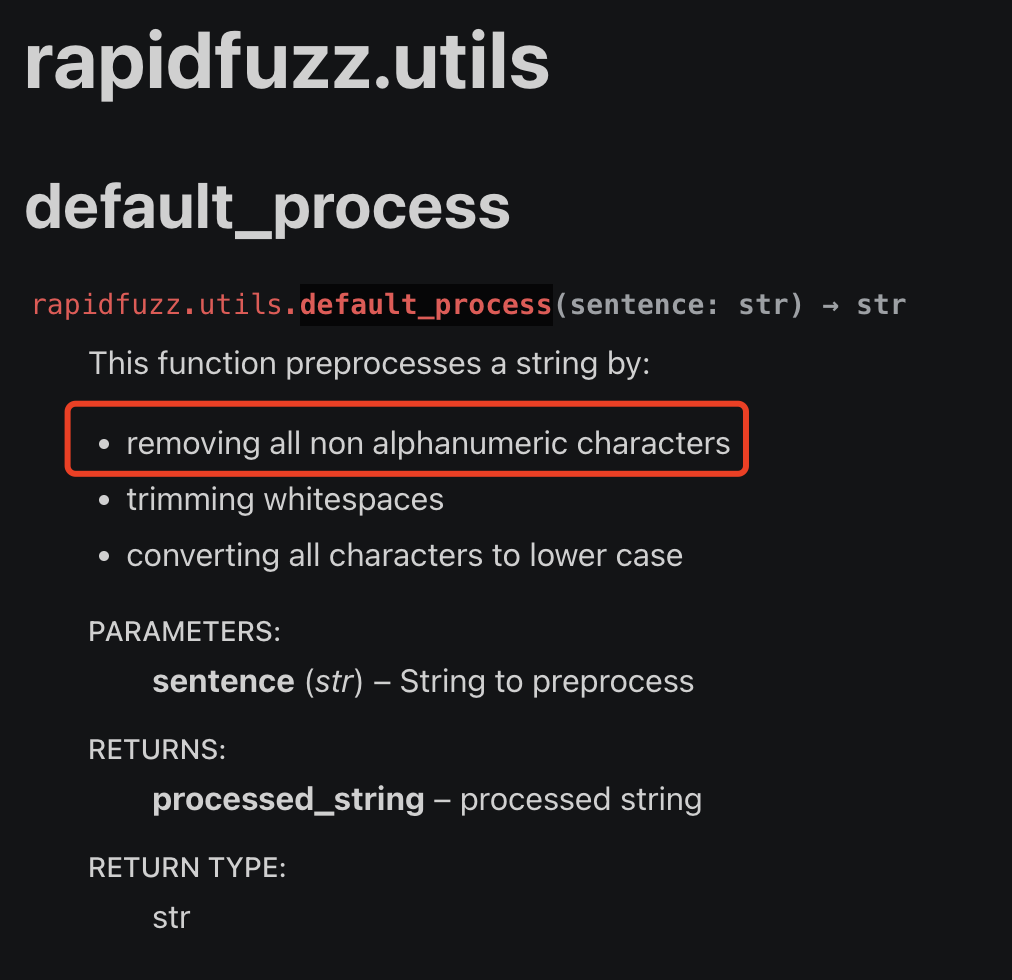
红色方框里面说,这个函数可以移除所有的非alphanumeric字符。如果我们使用翻译软件,会发现alphanumeric的意思是字母和数字。如下图所示:
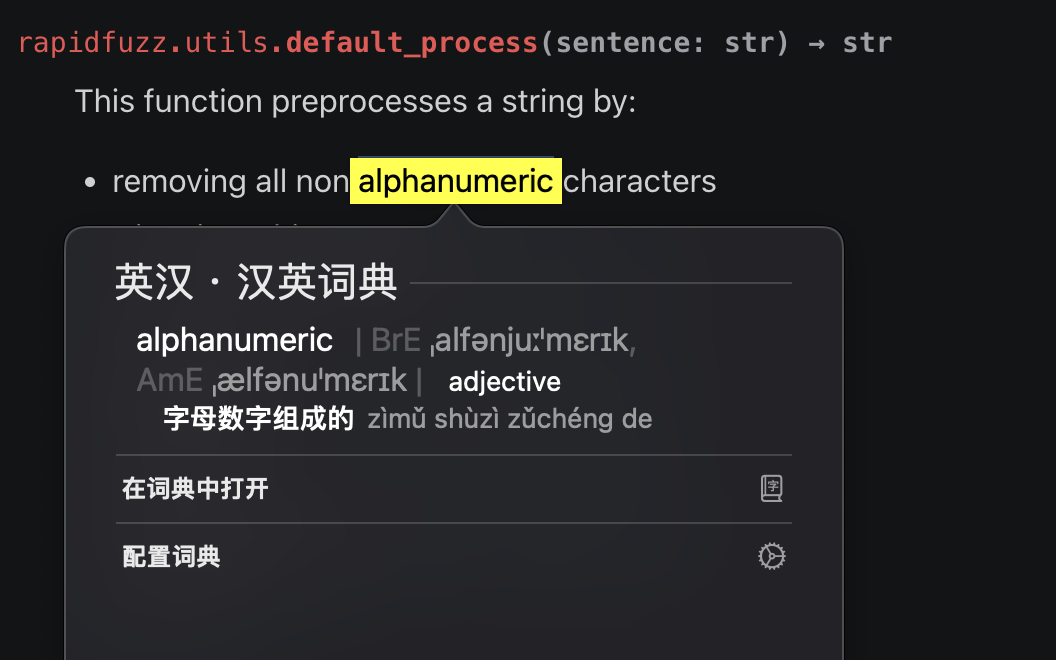
因此,我想当然的觉得,这个功能函数,只会保留26个英文字母的大小写加上10个数字,一共62个字符。把除此之外的所有其他字符都移除掉。
一日一技:Python工具脚本如何调用外层模块
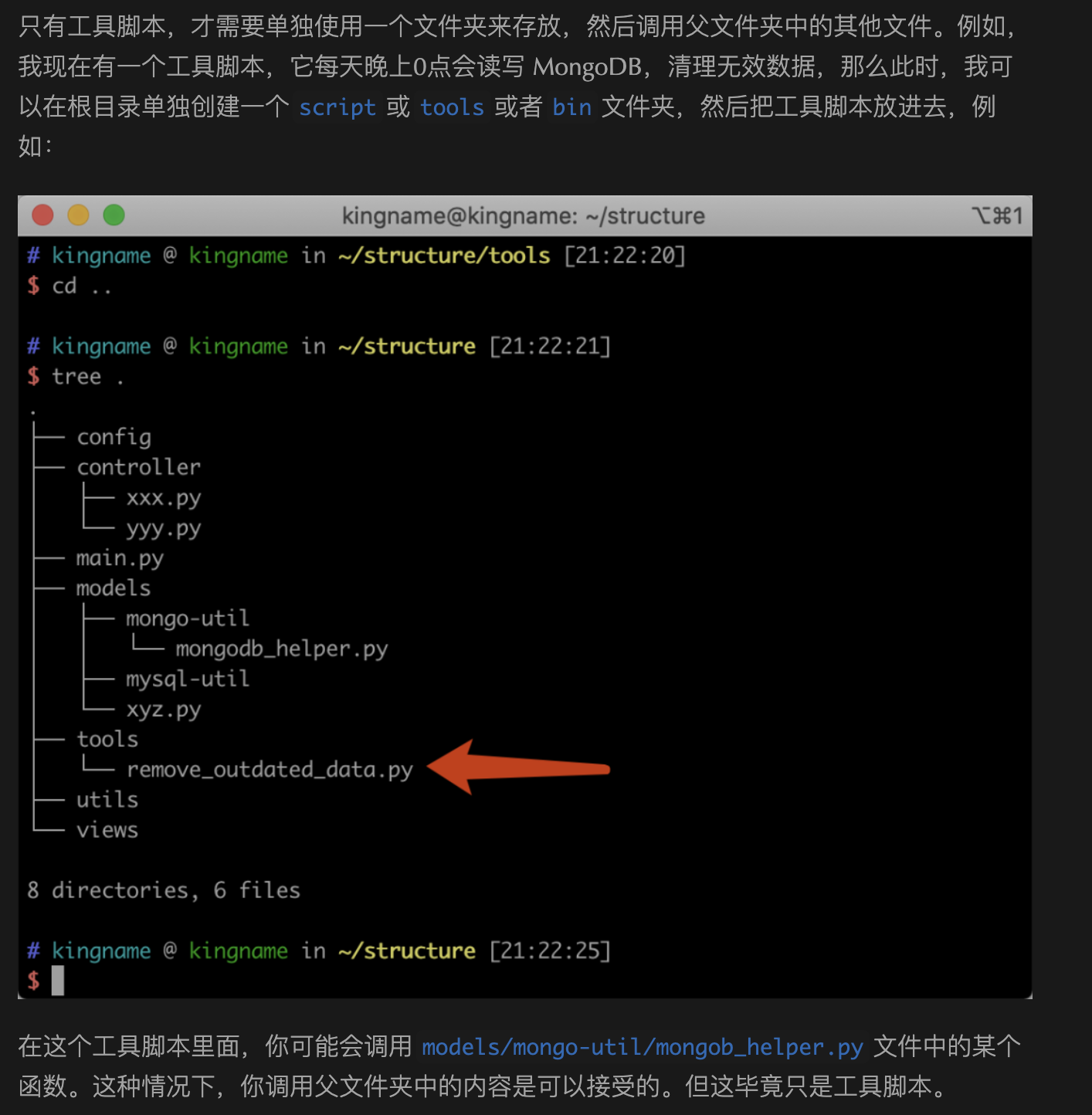
我三年前写过一篇文章:《小问题大隐患:如何正确设置 Python 项目的入口文件?》。讲到Python项目应该如何正确组织代码结构。入口文件应该在最外面,调用关系应该是从外向内调用。而不要学Java,从一个很深层的文件夹里面往外调用。
不过我在这篇文章的最后,也提到了一种例外情况,那就是工具脚本不受这个规则的限制。如下图所示。
一日一技:三分钟离线运行开源大模型
经过一年多的发展,各种开源大模型现在已经相当不错了。国产的Qwen 1.5的生成效果已经能满足一些日常使用。
有一些同学可能之前一直在用网页版的ChatGPT、Kimi Chat、文心一言或者通义千问,那么你可能会遇到如下一些问题:
- 网络问题。例如ChatGPT需要特殊的网络才能访问。
- 审查问题。国产大模型会大量屏蔽关键字,有一些你觉得完全没有任何问题的回答,它会告诉你不符合法律规范,不能回答。
- 不能自定义模型,网页版的这些大模型,你没有办法做微调,难以自定义内容。当你花了大量时间设计了一个高级Prompt,把模型洗脑成了猫娘,结果第二天它又不能用了。
- 隐私泄漏问题,担心大模型的开发商把你问的问题和上传的信息挪作他用。
当你被这些问题困扰,那么你可以考虑离线运行开源大模型。完全不需要网络,因此不存在隐私泄漏的问题。你可以随意对模型进行微调,想弄成猫娘还是伪娘都随你的想法。没有任何审查,想怎么问怎么答都可以调整。
一日一技:iOS下的开源免费消息推送服务
我们在部署代码到线上以后,可能会需要在一些情况下给自己发报警通知。如果是公司的线上业务,一般会有公司内部的各种通知工具。
但如果是自己的个人服务,我们应该怎么推送消息呢?有些同学可能使用过叮叮或者飞书机器人,但是这些机器人要发送通知还需要拉个群,稍微有点麻烦。有些同学可能使用的是Telegram,但使用它需要梯子也不太方便。
如果你的手机是iPhone,那么你可以使用一个开源免费超级轻量级的消息推送服务:Bark.
一日一技:next.js如何正确处理跨域问题?
我以前一直使用Vue来写前端。去年下半年接手了一个基于React + Next.js的项目,于是顺带学习了一下Next.js。由于Next.js的特点,这个项目的前后端是放在一起的。一开始没什么问题,看了半天文档就上手了。
上周我们需要在另一个网页项目中,调用这个项目的后端接口,于是就需要处理跨域请求的问题。但我发现按照网上的方法,跨域问题依然存在。这个问题浪费了我不少时间,好在最后终于找到了原因。记录在这里,免得大家跟我一样踩坑。
再见2023,你好2024
跟风来写个年终总结。
我记得在2023年元旦,我发了个语音,说我要开始搞播客。结果1年过去了,播客还是没个影子。今年不设这个目标了,免得又拖到明年。
2023年开头的前5个月,是2022年痛苦的延续。我真的太讨厌字节了。每一天都过得非常痛苦。公众号没有时间写,自己的代码也没有时间写,连学习的时间都没有。每天下班就只想躺下。连躺下都躺不安稳,飞书上面的消息一直在轰炸,动不动就开语音。开你妈个锤子的语音。急急急,急你MLGB,你连一小时都活不下去了吗?我每天在心里骂字节和某些没有边界的同事一百遍。
一日一测:Bright Data的海外代理测试
上周的公众号文章提到了Bright Data提供的代理服务。没想到他们的运营同学竟然找上了门,问我能不能帮他们做一个评测。
我之前使用Bright Data的代理,是因为突然有一天我的HuggingFace爬虫挂了。比较奇怪的是,这个爬虫在我电脑上始终正常运行,但一放到服务器上就请求失败。联想到HuggingFace被封了,而这个爬虫之前一直使用的国内代理供应商,那么原因就很明显了。因为我的电脑是24小时挂着梯子的,所以能够正常访问HuggineFace,但爬虫部署到服务器上面以后,他会自动使用配置好的国内代理。由于国内代理也受到GFW的影响,因此也会出问题。
一日一技:自动提取任意信息的通用爬虫
使用过GNE的同学都知道,GNE虽然是通用爬虫,但只是文章类页面的通用爬虫。如果一个页面不是文章页,那么就无能为力了。
随着ChatGPT引领的大语言模型时代到来,这个问题基本上已经不是问题了。我们先来看一个效果。首先打开Linkedin,随便找一个招聘的岗位,如下图所示:
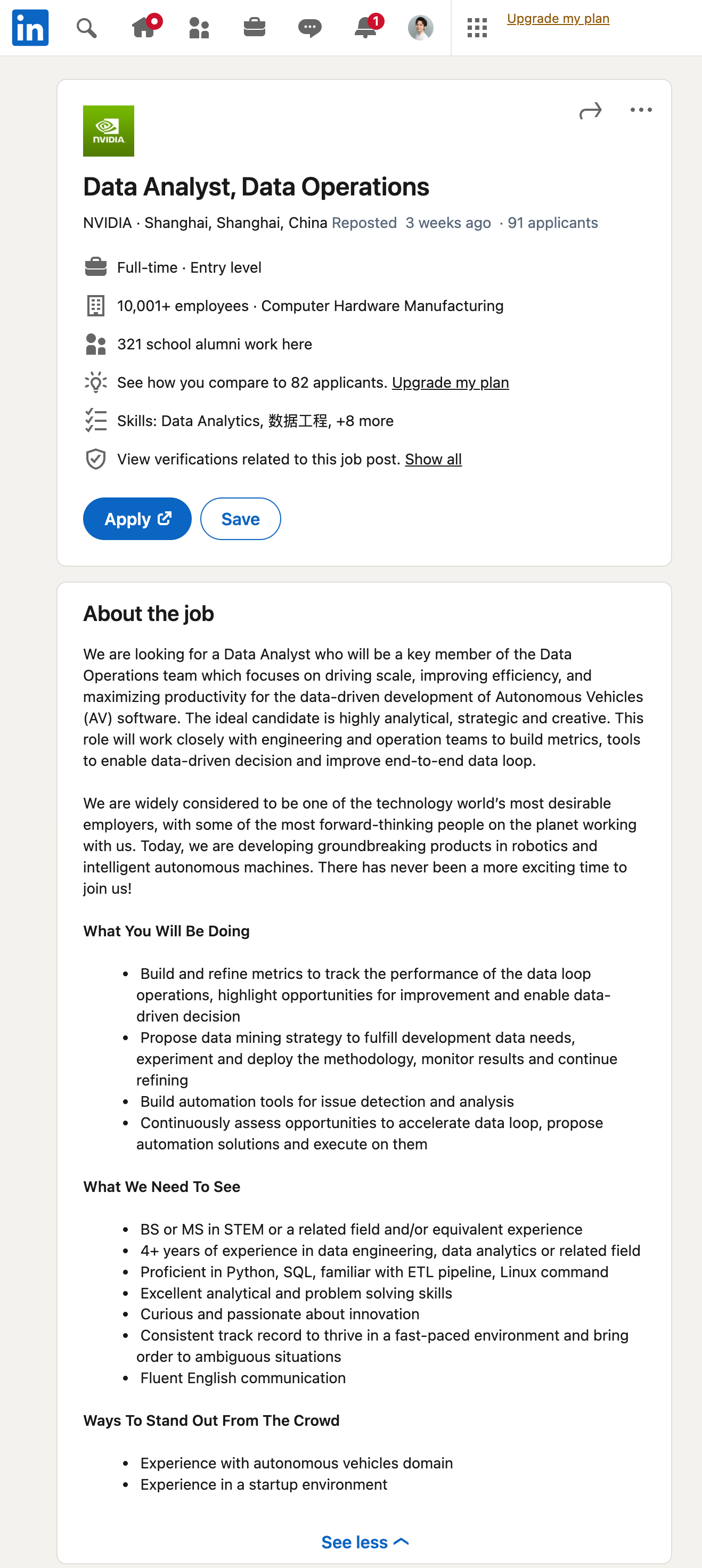
然后,我们直接使用GPT从这里提取信息:

GnePro:文章类通用爬虫接口
GnePro是开源项目GNE的付费版,能够实现如下功能:
- 输入任意文章页面的URL,返回标题/作者/正文/发布时间/图片/面包屑等一系列信息
- 支持异步加载文章页提取
- 支持上传自定义的HTML代码提取正文
- 支持自动检测网页编码
- 支持自动提取网页全部URL
- 在8个国家13万个新闻类网站进行测试,准确率高达90%