一日一技:分布式系统的低成本权限校验机制
经常关注未闻Code的同学都知道,我做了一个叫做GNE的开源项目,它能够自动提取新闻类网页的正文。效果远远好于市面上其他的开源新闻提取工具。
大家可能不知道,GNE还有一个高级版,叫做GnePro。它可以让你输入URL就自动提取新闻的正文,提取的字段比GNE多得多。并且已经在8个国家13万个网站上做过测试,识别准确率100%。
经常关注未闻Code的同学都知道,我做了一个叫做GNE的开源项目,它能够自动提取新闻类网页的正文。效果远远好于市面上其他的开源新闻提取工具。
大家可能不知道,GNE还有一个高级版,叫做GnePro。它可以让你输入URL就自动提取新闻的正文,提取的字段比GNE多得多。并且已经在8个国家13万个网站上做过测试,识别准确率100%。
当我们在维护公司项目时,可能会遇到这样的场景:我正在开发一个新功能,突然需要修一个Bug。
这个时候,有些同学是这样做的:
1 | git add . |
更有一些经验的同学,可能会这样写:
1 | git stash |
但如果在修这个Bug的时候,又来了一个更紧急的Bug需要修怎么办?到后面很容易就把前面的代码搞忘了。
在之前的多篇文章中,我都反复告诫大家,不要滥用字典来传大量数据。因为当你的函数收到一个字典的时候,你根本不知道这个字典里面有哪些Key,你必须有一层一层往上看,找到所有尝试往字典里面添加新Key的地方,你才能知道它总共有哪些Key。
但是,在正常公司项目中,我们可能会需要维护一些历史遗留代码。代码规模大,函数调用层级非常深。并且之前的人已经使用字典来传递了大量的数据。
短时间内,我们没有办法直接把字典改成Dataclass。那么我们能做的,就是尽量避免后续的维护者往里面加入新的Key。我以前遇到过一个项目,它有一个字典,刚刚开始初始化的时候,只有5个Key。这个字典作为参数被传入了很多个函数,每个函数都会往它里面加很多个Key。到最后,这个字典里面已经有40多个Key了。
前两天的OpenAI发布会,相信很多同学看完以后都热血沸腾。我之前一直使用的是ChatGPT的免费版本,看完这个发布会以后,立刻就充值了ChatGPT Plus,来试一试这些高级功能。
这两天GPTs功能上线了,短短三天时间,全球网友创建了几千个GPT机器人。我今天也来搞一个玩玩。
使用GPTs创建机器人非常简单,不需要懂任何编程知识,甚至不需要懂Prompt工程,你只需要跟着他的向导,一步一步描述你的想法就可以了。
写后端的同学,有时候需要在网站上实现一个功能,让用户上传或者编写自己的Python代码。后端再运行这些代码。
涉及到用户自己上传代码,我们第一个想到的问题,就是如何避免用户编写危险命令。如果用户的代码里面涉及到下面两行,在不做任何安全过滤的情况下,就会导致服务器的Home文件夹被清空。
1 | import os |
有人想的比较简单,直接判断用户的代码里面有没有os.system、exec、subprocess……这些危险关键词不就可以了吗?
这种想法乍看起来没有问题,但细想下,就会发现非常天真。如果用户的代码像下面这样写,你又要如何应对?
我们在开发爬虫的过程中,经常发现有一些网站,会直接把数据放到HTML中的<script>标签里面。这些数据长得有点像JSON,但又有差异,如下图所示:
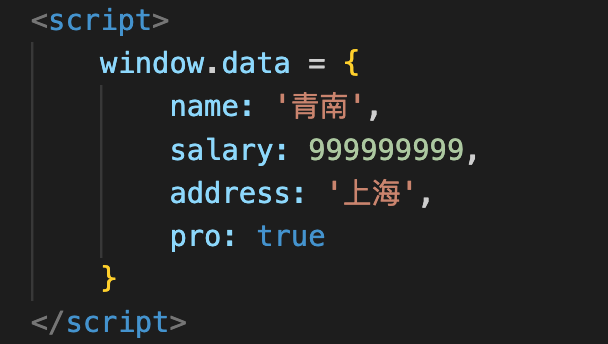
这种格式,我们叫做JavaScript Object。长得很像Python的字典,又很像是JSON。但是这个格式在Python里面,无论直接当字典解析,还是当JSON解析,都会报错,如下图所示:
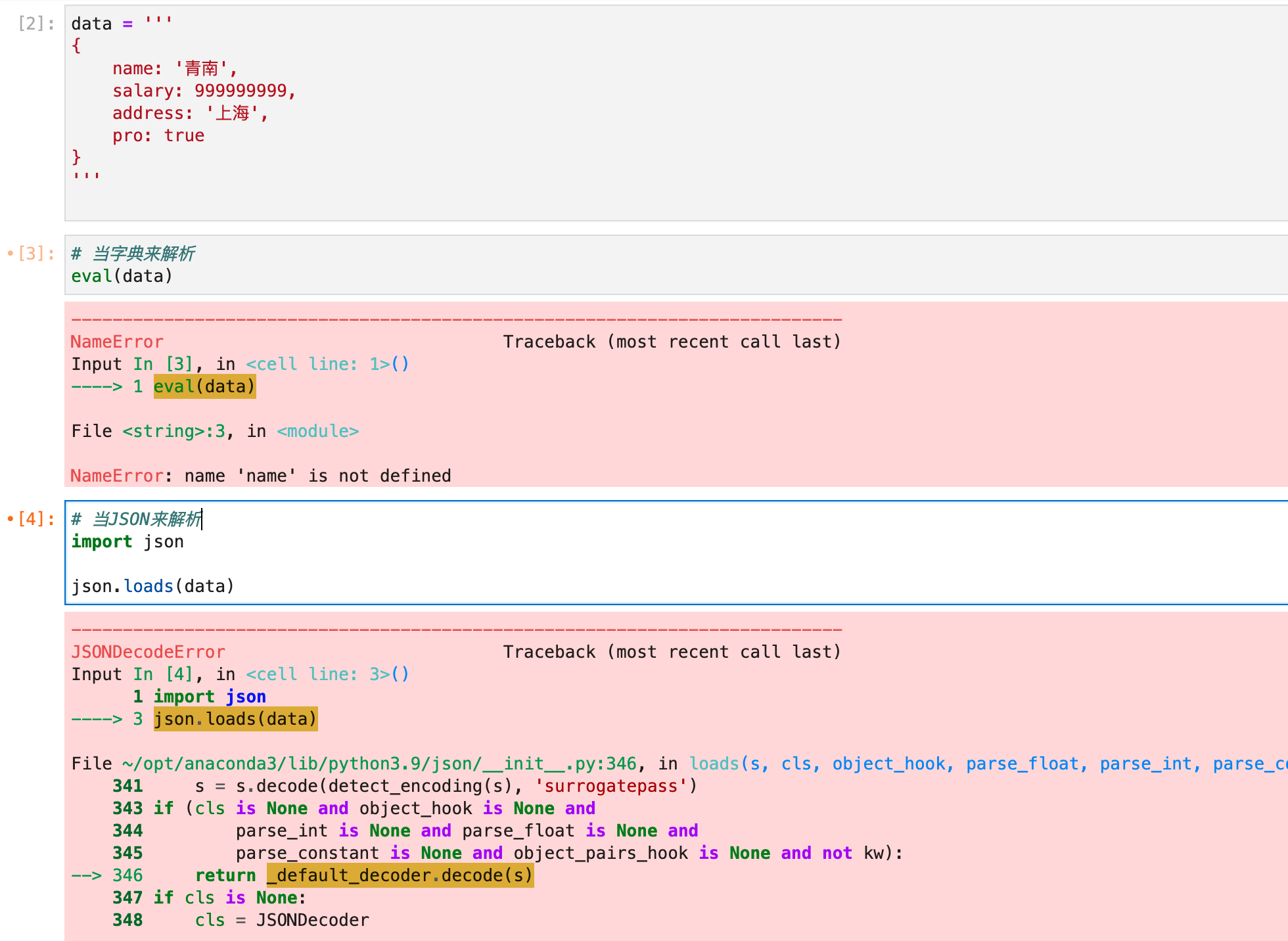
遇到这种情况,有同学准备使用正则表达式来解析,又有同学直接放弃。
我们在开发爬虫的过程中,经常发现有一些网站,会直接把数据以JSON的形式,通过<script>标签放到页面源代码中。如下图所示:
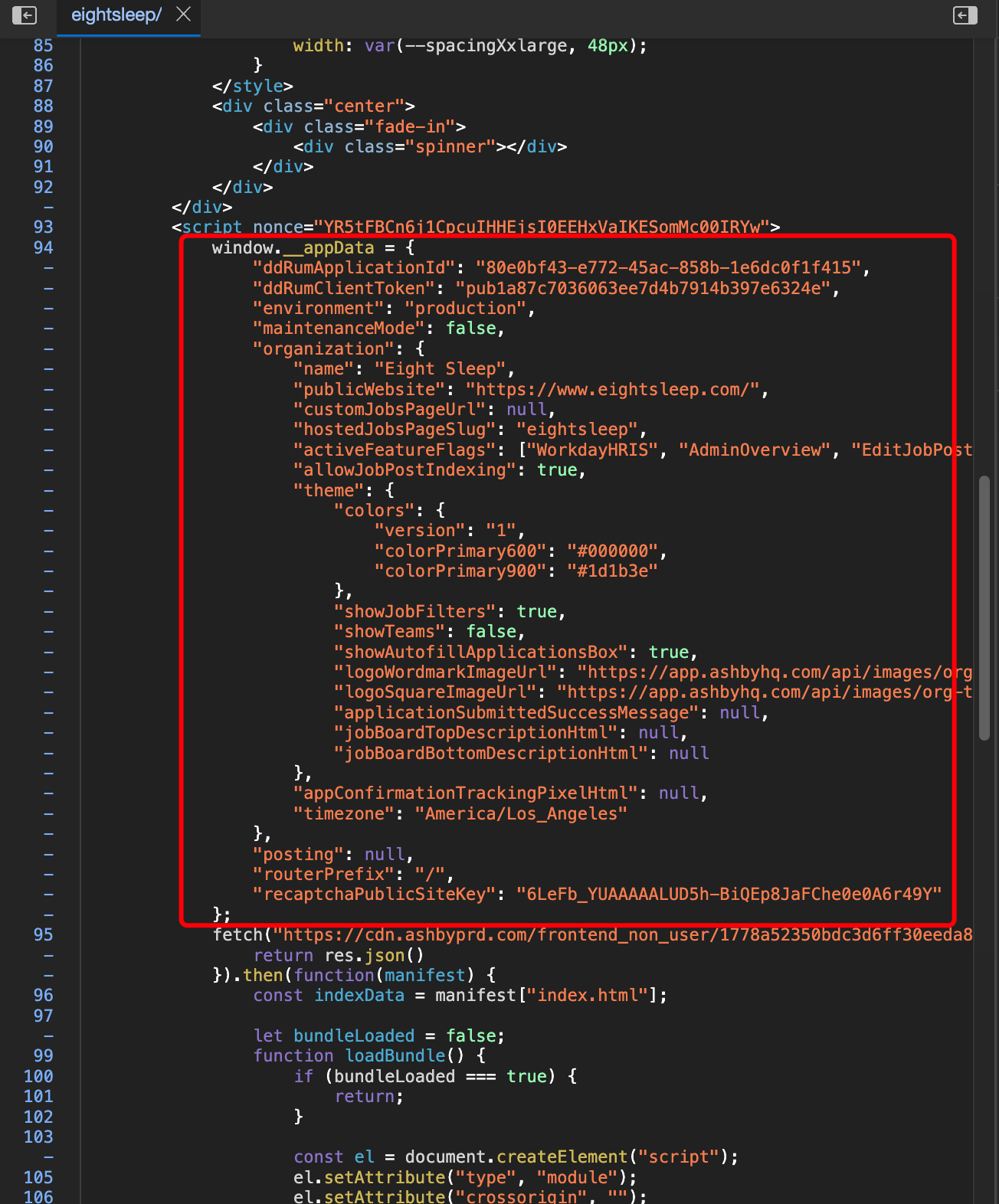
有时候请求URL拿到HTML的过程比较麻烦,有些同学习惯先把HTML复制到代码里面,先把解析的逻辑写好,然后再去开发请求HTML的代码。
现在有很多网站,已经能够通过JA3或者其他指纹信息,来识别你的请求是不是Requests发起的。这种情况下,你无论怎么改Headers还是代理,都没有任何意义。
我之前写过一篇文章:Python如何突破JA3,但方法非常复杂,很多初学者表示上手有难度。那么今天我来一个更简单的方法,只需要修改两行代码。并且不仅能过JA3,还能过Akamai。
产品经理这两天在跟我抱怨他们公司的一个码农。听的我火冒三丈,差点把跟了我十多年的搪瓷水杯砸烂。
正好在知识星球和微信群里面,有不少同学跟我咨询程序员的职业发展以及怎么应对三十岁危机。
借此机会,我准备用几篇文章来讲讲自己的经验和个人的观点。
我们知道,在Python里面,要把JSON转成字典是非常容易的,只需要使用json.loads(JSON字符串)就可以了。
但如果这个JSON转成的字典,嵌套比较深,那么要读取里面的数据就非常麻烦了。如下图所示:

如果我要读取把图中的end减去start字段,那么用字典的时候,代码要写成这样:
1 | result = info['data'][0]['entities']['annotations'][0]['end'] - info['data'][0]['entities']['annotations'][0]['start'] |
光是看到这些方括号和单引号,就够让人头晕了。