一日一技:从Pandas DataFrame两个小技巧
今天我从网上下载了一批数据。这些数据是Excel格式,我需要把他们转移到MySQL中。这是一个非常简单的需求。
今天我从网上下载了一批数据。这些数据是Excel格式,我需要把他们转移到MySQL中。这是一个非常简单的需求。
相信很多同学或多或少都在Python中使用过GPT API,通过Python安装openai库,来调用GPT模型。
OpenAI官方文档中给出了一个示例,如下图所示:
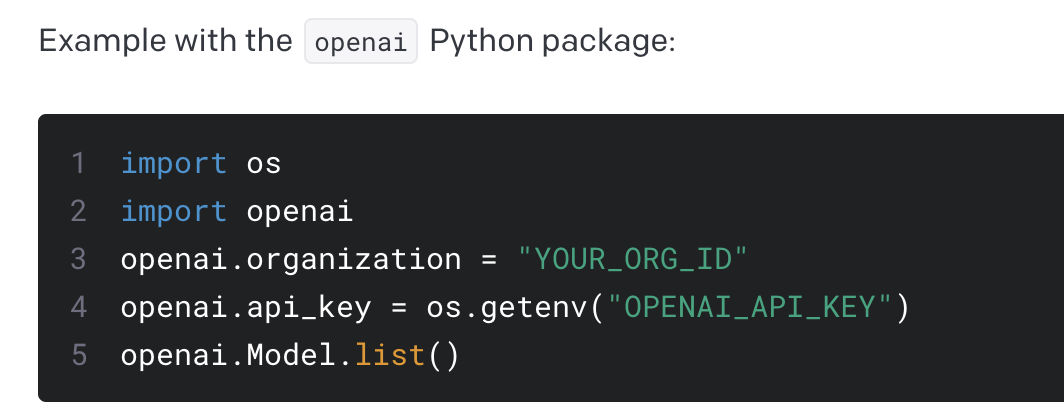
如果你只有一个API账号,那么你可能不觉得这样写有什么问题。但如果你想同时使用两个账号怎么办?
在之前很长一段时间,从PDF文件中提取表格都是一个老大难的问题。无论你使用的是PyPDF2还是其他什么第三方库,提取出来的表格都会变成纯文本,难以二次利用。
但现在好消息来了,专业处理PDF的第三方库PyMuPDF升级到了1.23.0,已经支持完美提取PDF中的表格了。还可以把表格转换为Pandas的DataFrame供你分析。
我们知道,在使用Requests发起GET请求时,可以通过params参数来传递URL参数,让Requests在背后帮你把URL拼接完整。例如下面这段代码:
1 | # 实际需要请求的url参数为: |
那么在Scrapy中,发起GET请求时,应该怎么写才能实现这种效果呢?
有不少同学在写爬虫时,会使用Scrapy + scrapy_redis实现分布式爬虫。不过scrapy_redis最近几年更新已经越来越少,有一种廉颇老矣的感觉。Scrapy的很多更新,scrapy_redis已经跟不上了。
目前市面上没有任何方法能够完全避免你的程序被人反编译。即便是3A游戏大作,发布出来没多久也会被人破解。现在只能做到增大反编译的难度,让程序相对无法那么快被破解。
我们知道,Python代码默认是公开的。当你要把一个Python项目给别人运行的时候,一般来说别人就能看到你的全部源代码。我们可以使用Cython、Nuitka对代码进行打包,编译成.so文件、.dll文件或者是可执行文件,从而在一定程度上避免别人看到你的源代码。我在字节的时候,内部的一个系统就是使用Cython打包的,然后部署到客户的服务器上。
最近遇到一个需求,需要抓取Docusaurus上面的全部文档。如下图所示:
抓文档的正文非常简单,使用GNE高级版,只要有URL直接就能抓取下来,如下图所示:
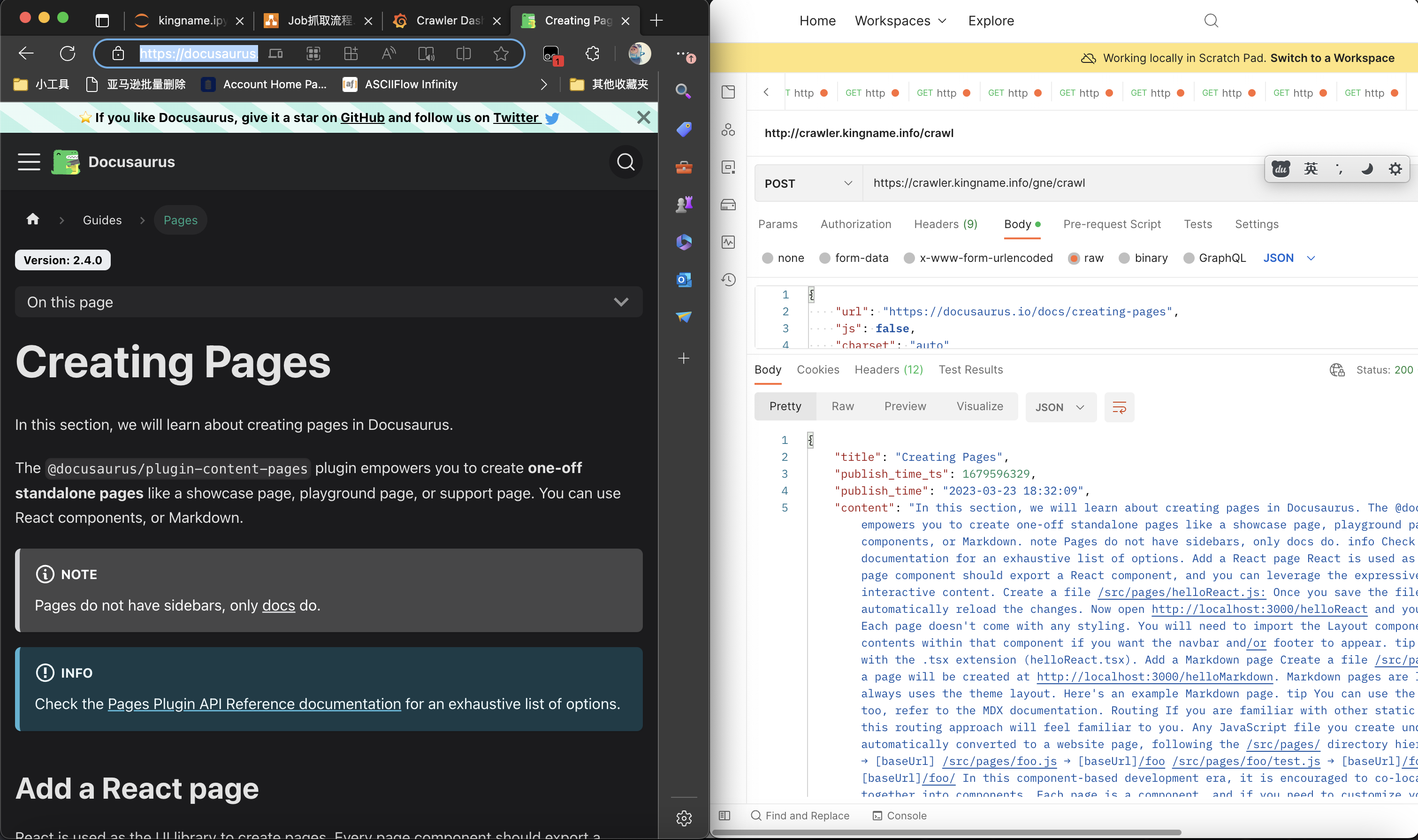
但现在的问题是,我怎么获取到每一篇文档的URL?
写过爬虫的同学都知道,当我们想对App或者小程序进行抓包时,最常用的工具是Charles、Fiddler或者MimtProxy。但这些软件用起来非常复杂。特别是当你花了一两个小时把这些软件搞定的时候,别人只用了15分钟就已经手动把需要的数据抄写完成了。
如果你不是专业的爬虫开发者,那么大多数时候你的抓包需求都是很小的需求,手动操作也不是不能。这种时候,我们最需要的是一种简单快捷的,毫不费力的方法来解放双手。
例如我最近在玩《塞尔达传说——王国之泪》,我有一个小需求,就是想找到防御力最大的帽子、衣服和裤子来混搭。这些数据,在一个叫做『Jump』的App上面全都有,如下图所示:
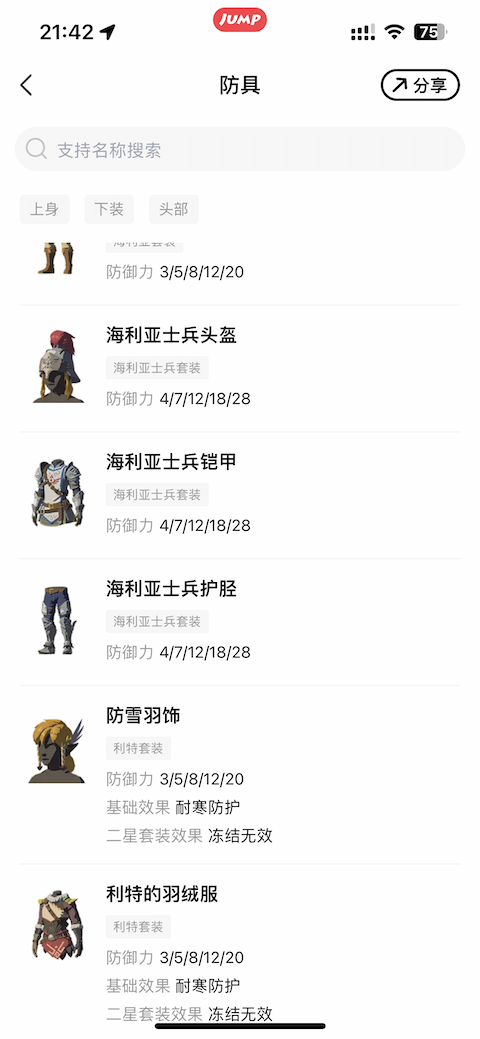
防具总共也就几十个,肉眼一个一个看也没问题,就是费点时间而已。那么,如果我想高效一些,有没有什么简单办法通过抓包再加上Python写几行代码来筛选,快速找到我想要的数据呢?
程序员是一个需要持续学习的群体,如果你发现你现在写的代码跟你5年前的代码没什么区别,说明你掉队了。
我们在做Python开发时,经常使用一些第三方库,这些库很多年来持续添加了新功能。但我发现很多同学在使用这些第三方库时,根本不会使用新的功能。他们的代码跟几年前没有任何区别。
关注我公众号的很多同学都会写爬虫。但如果想把爬虫写得好,那一定要掌握一些逆向技术,对网页的JavaScript和安卓App进行逆向,从而突破签名或者绕过反爬虫限制。
最近半年,大语言模型异军突起,越来越多的公司基于GPT3.5、GPT-4或者其他大语言模型实现了各种高级功能。在使用大语言模型时,Prompt写得好不好,决定了最终的产出好不好。甚至因此产生了一门新的学问,叫做Prompt Engineer.
有些公司经过各种测试,投入大量人力,终于总结了一些神级Prompt。这些Prompt的效果非常好。他们会把这些Prompt当作魔法咒语一样视为珍宝,轻易不肯示人。
这个时候,另外一门对抗技术就产生了,我给他取名,Prompt Reverse Engineering:Prompt逆向工程。