一日一技:用一个奇技淫巧把字符串转成特定类型
我们有时候可能会需要把一个字符串转换成对应的类型。例如,把'123'转换为int类型的123;或者把'3.14'转成浮点数3.14。
我们有时候可能会需要把一个字符串转换成对应的类型。例如,把'123'转换为int类型的123;或者把'3.14'转成浮点数3.14。
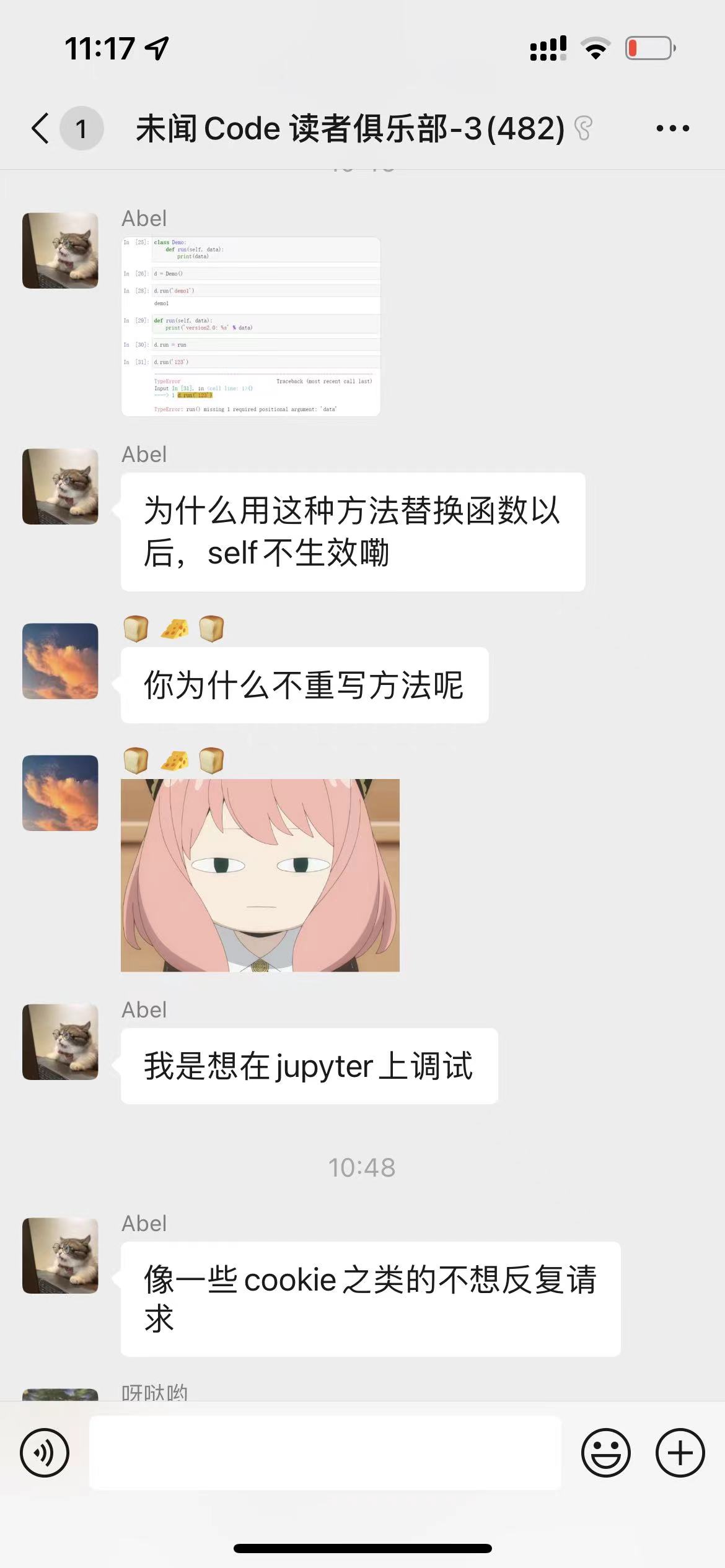
今天有同学在公众号粉丝群问了这样一个问题:
到今天就满30岁了。
我的结论是:统计Bug率有意义。但是统计千行代码Bug率没有意义。
如果你使用过嘀嗒清单或者Todoist,那你应该知道他们有一个很好用的功能,那就是自动识别任务中的时间,例如:
1 | 下周二下午三点给老板发邮件 |
它会自动识别为:

今天,公众号粉丝群里面,有一个叫做NowAnti的同学推荐了一个项目,叫做司南,它就可以让Python实现这样的功能。
我们知道,在Python里面,可以使用input获取用户的输入。例如:

但有一个问题,如果你什么都不输入,程序会永远卡在这里。有没有什么办法,可以给input设置超时时间呢?如果用户在一定时间内不输入,就自动使用默认值。
相信大家都知道二分搜索,在一个有序的列表中,使用二分搜索,能够以O(logN)的时间复杂度快速确定目标是不是在列表中。
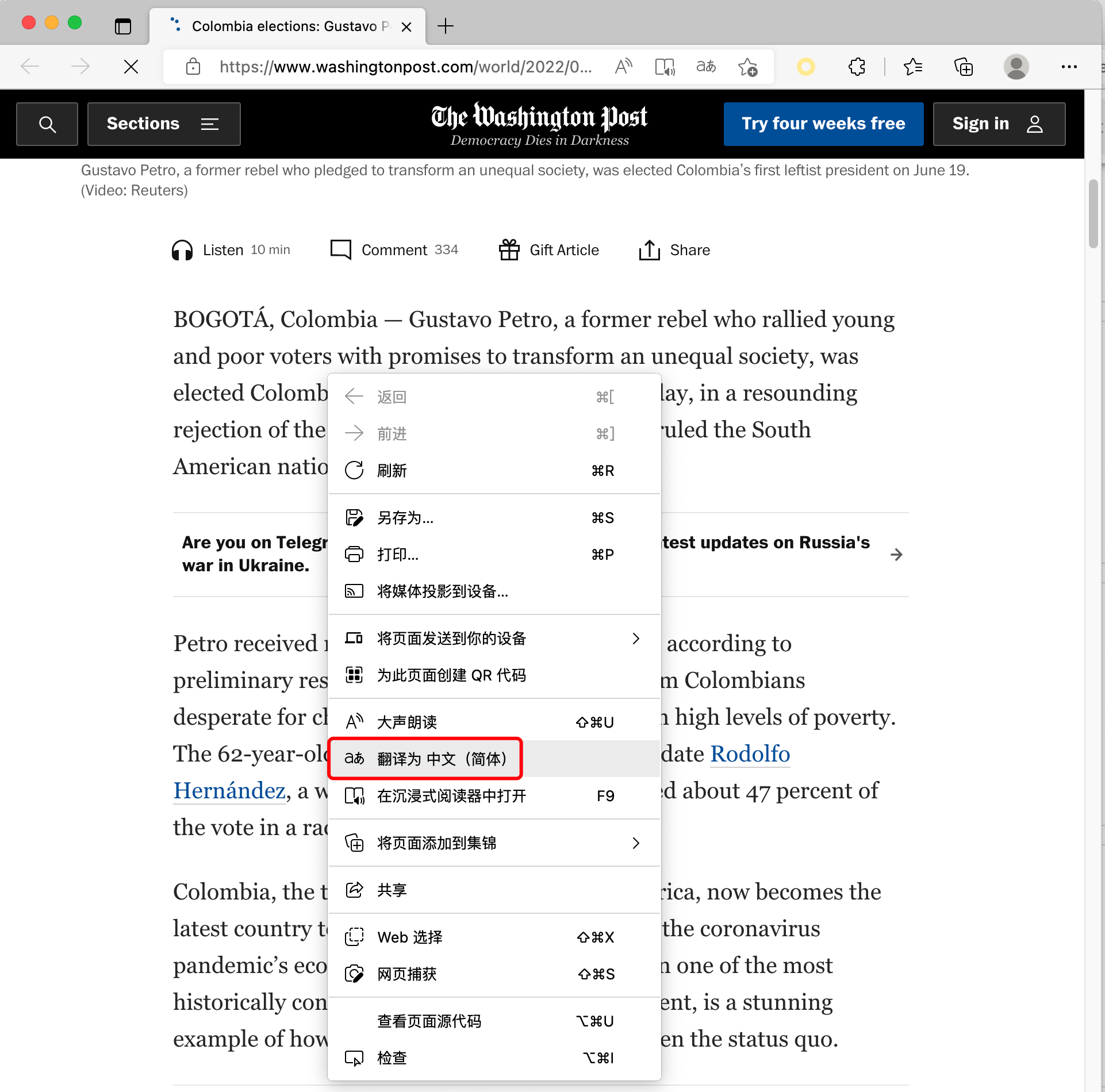
相信大家都用过浏览器的翻译网页功能,例如对于下图这个英文网页:
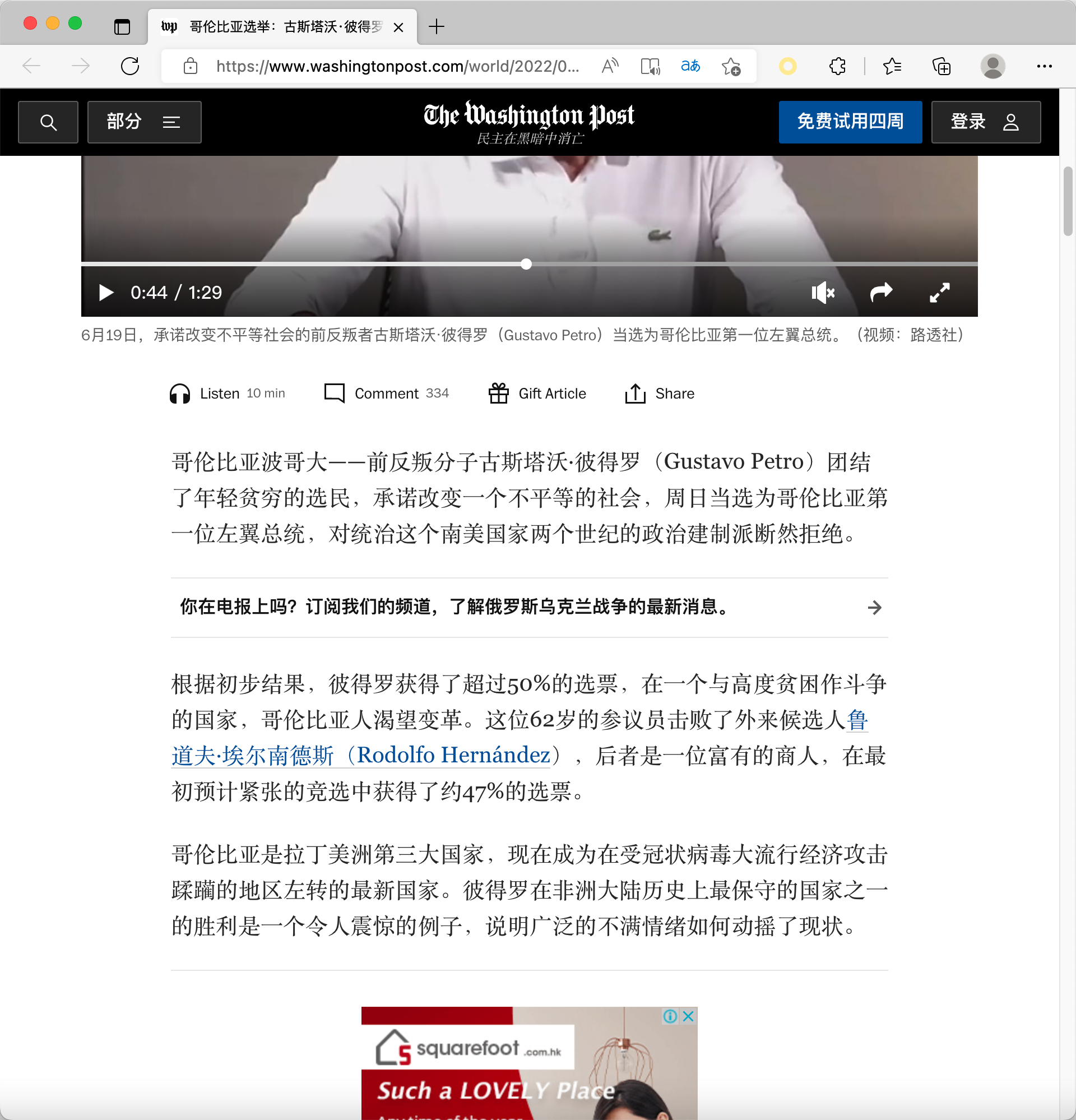
一键翻译成中文以后是这样的:
你可能会觉得这个功能很简单,不就是字符串替换吗?那你可以试一试把下面这个HTML片段中的<p>标签下面的英文翻译成中文。其它标签中的不要改动:
1 | <div> |
在<em>标签中的datetime和<span>标签中的datetime.datetime.now()不需要翻译。
公司有一个内部博客,大家可以在上面创建自己的账号,然后写文章在全公司分享。昨天这个内部博客开通了API,因此我准备写一个Python程序,把自己公众号文章都搬运上去。
正则表达式这个东西,强大是强大,但写出来跟个表情符号一样。自己写的表达式,过一个月来看,自己都不记得是什么意思了。比如下面这个:
1 | pattern = r"((?:\(\s*)?[A-Z]*H\d+[a-z]*(?:\s*\+\s*[A-Z]*H\d+[a-z]*)*(?:\s*[\):+])?)(.*?)(?=(?:\(\s*)?[A-Z]*H\d+[a-z]*(?:\s*\+\s*[A-Z]*H\d+[a-z]*)*(?:\s*[\):+])?(?![^\w\s])|$)" |