从Workflowy到印象笔记
Workflowy是一个极简风格的大纲写作工具,使用它提供的无限层级缩进和各种快捷键,可以非常方便的理清思路,写出一个好看而实用的大纲。如下图所示。

印象笔记更是家喻户晓,无人不知的跨平台笔记应用。虽然有很多竞争产品在和印象笔记争抢市场,但是印象笔记强大的搜索功能还是牢牢抓住了不少用户。
如果能够把用Workflowy写大纲的便利性,与印象笔记强大的搜索功能结合起来,那岂不是如虎添翼?如下图所示。
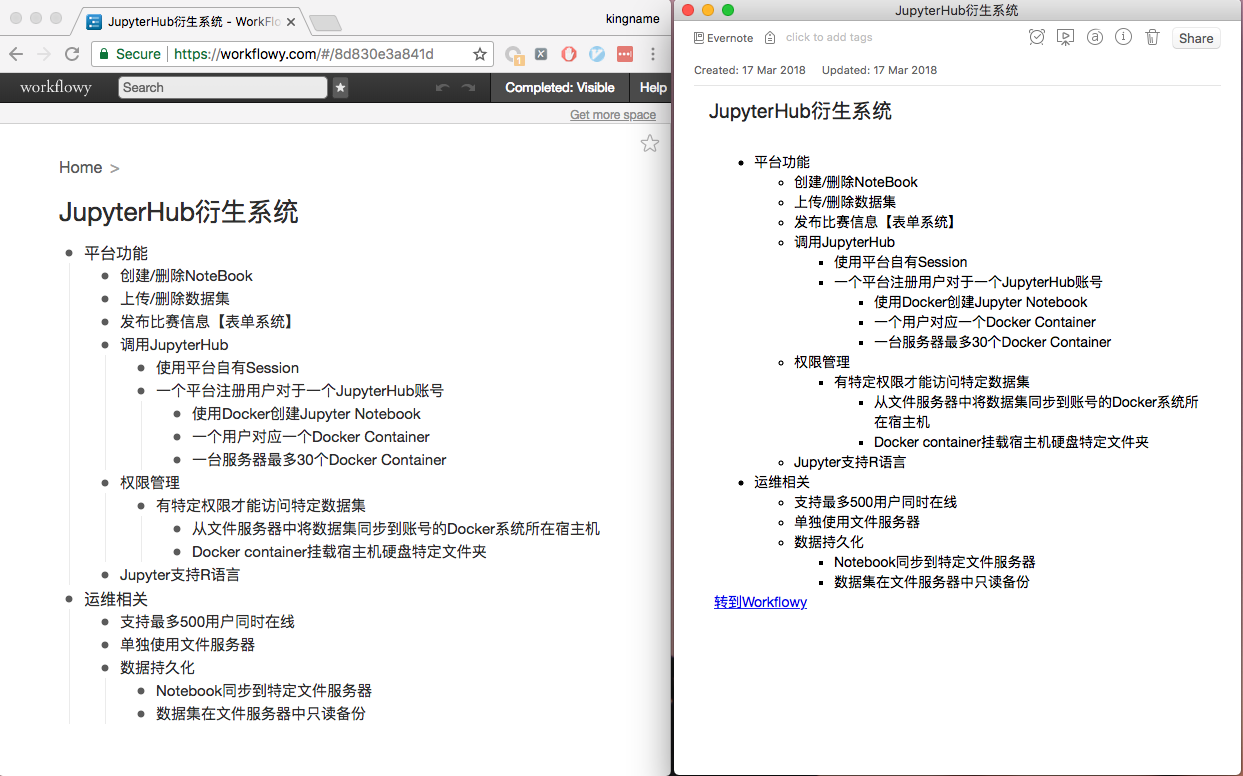
EverFlowy就是这样一个小工具。它可以自动把Workflowy上面的条目拉下来再同步到印象笔记中。如果Workflowy有更新,再运行一下这个小工具,它就会同步更新印象笔记上面的内容。Workflowy负责写,印象笔记负责存,各尽其能,各得其所。


