使用生成器把Kafka写入速度提高1000倍
通过本文你会知道Python里面什么时候用yield最合适。本文不会给你讲生成器是什么,所以你需要先了解Python的yield,再来看本文。
通过本文你会知道Python里面什么时候用yield最合适。本文不会给你讲生成器是什么,所以你需要先了解Python的yield,再来看本文。
Workflowy是一个极简风格的大纲写作工具,使用它提供的无限层级缩进和各种快捷键,可以非常方便的理清思路,写出一个好看而实用的大纲。如下图所示。

印象笔记更是家喻户晓,无人不知的跨平台笔记应用。虽然有很多竞争产品在和印象笔记争抢市场,但是印象笔记强大的搜索功能还是牢牢抓住了不少用户。
如果能够把用Workflowy写大纲的便利性,与印象笔记强大的搜索功能结合起来,那岂不是如虎添翼?如下图所示。
EverFlowy就是这样一个小工具。它可以自动把Workflowy上面的条目拉下来再同步到印象笔记中。如果Workflowy有更新,再运行一下这个小工具,它就会同步更新印象笔记上面的内容。Workflowy负责写,印象笔记负责存,各尽其能,各得其所。
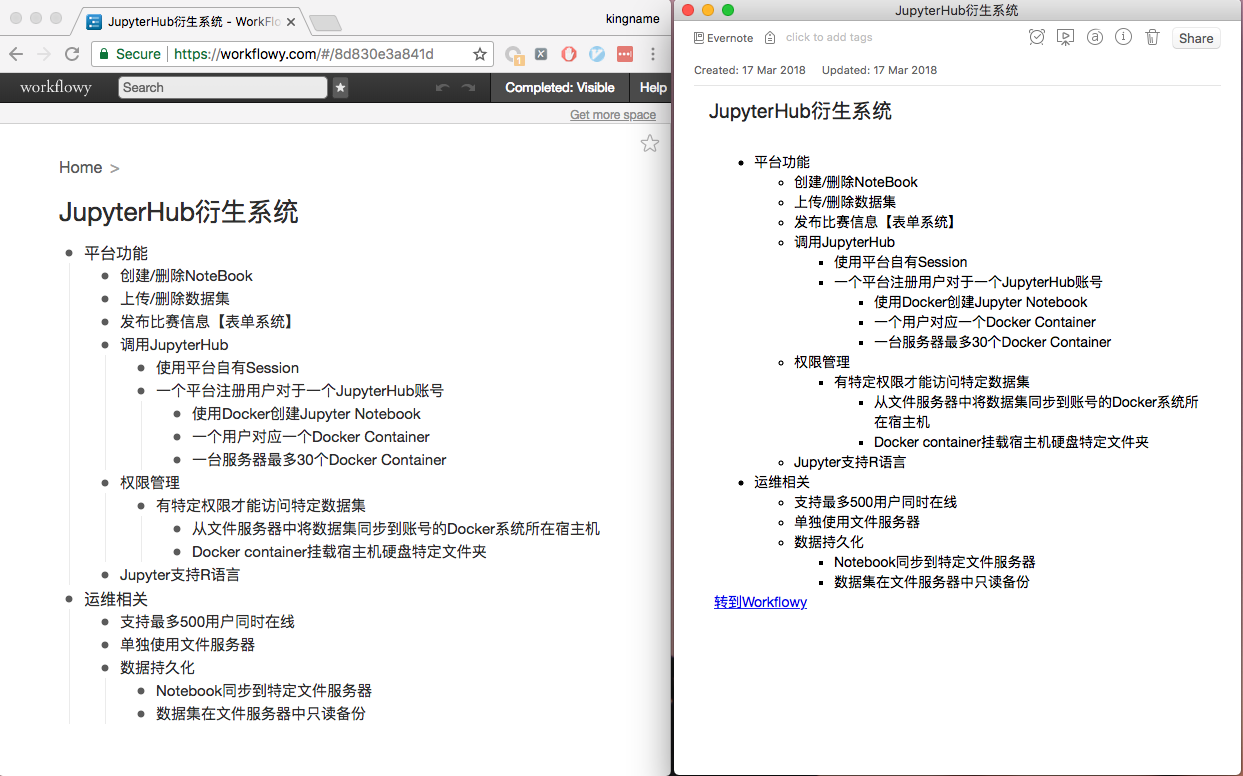
我是一个工具控,经常尝试各种生产力工具。我发现任务管理App汗牛充栋,项目管理工具乏善可陈,而目标管理App更是少得可怜。
我非常喜欢使用甘特图来做项目管理。不用甘特图的公司,我觉得很奇怪。
这篇文章比较简单,适合初学持续集成的读者,本文可以帮助你对基于Jenkins的持续集成有一个比较全局的概念。
Teambition是一个跨平台的团队协作和项目管理工具,相当于国外的Trello。使用Teambition可以像使用白板与便签纸一样来管理项目进度,如下图所示。

Teambition虽然便于管理项目,但是如果直接在Teambition上面创建一个项目对应的任务,却容易陷入面对茫茫白板,不知道如何拆分任务的尴尬境地。如下图所示。

面对这个空荡荡的窗口,应该添加哪些任务进去?直接用脑子现想,恐怕容易出现顾此失彼或者干脆漏掉了任务的情况。
当我要开始一个项目的时候,我一般不会直接打开Teambition就写任务,而是使用一个大纲工具——Workflowy来梳理思路,切分任务。等任务已经切分好了,在誊写到Teambition中,如下图所示。

但这样就出现了一个问题:首先在Workflowy上面把需要做的任务写好。然后再打开Teambition,把这些任务又誊写到Teambition中。为了减少“誊写”这一步重复劳动,于是就有了TeamFlowy这个小工具。它的作用是自动誊写Workflowy中的特定条目到Teambition中。
Python 装饰器装饰类中的方法这篇文章,使用了装饰器来捕获代码异常。这种方式可以让代码变得更加简洁和Pythonic。
在写代码的过程中,处理异常并重试是一个非常常见的需求。但是如何把捕获异常并重试写得简洁高效,这就是一个技术活了。
Python作为一门动态语言,其变量的类型可以自由变化。这个特性提高了代码的开发效率,却也增加了阅读代码和维护代码的难度。