Python 装饰器装饰类中的方法
目前在中文网上能搜索到的绝大部分关于装饰器的教程,都在讲如何装饰一个普通的函数。本文介绍如何使用Python的装饰器装饰一个类的方法,同时在装饰器函数中调用类里面的其他方法。本文以捕获一个方法的异常为例来进行说明。
目前在中文网上能搜索到的绝大部分关于装饰器的教程,都在讲如何装饰一个普通的函数。本文介绍如何使用Python的装饰器装饰一个类的方法,同时在装饰器函数中调用类里面的其他方法。本文以捕获一个方法的异常为例来进行说明。
我们都有这样的生活体验
我清清楚楚的记得半个小时前还用手机打了电话,怎么现在手机找不到了?这半个小时我一直在房间里,难道手机还会长翅膀飞走了吗?
如果你有两个手机而且你的手机没有静音,那可以用另一个手机给不见的手机打一个电话。可是如果你的手机静音了呢?有人说可以等到晚上打电话,看家里哪里在发光。那么如果你的手机不仅静音,还屏幕朝下呢?
看了这篇文章以后,只要你的手机在家里,只要手机开机,只要手机可以上网,那么你就可以在30秒以内找到它,不论它是否静音。
在对安卓手机设计自动化测试用例的时候,判断一个测试场景是否可以自动化的依据在于其是否需要人的参与。对于wifi能否自动打开关闭,短信能否自动收发这样的场景,不需要人参与就可以通过程序来判断,因此对Wifi与短信这样的测试,可以通过程序来实现自动化测试。但是另外还有一些测试场景,需要人的眼睛来看,这种场景要实现自动化就比较困难。
闹钟已经成了我们生活中必不可少的东西。如果全球每个国家的当地时间明天早上,所有的闹钟突然都不响了,不知道会发生什么样的混乱。
然而我们要讨论另外一种情况,闹钟每天定时响起来,真的是最好的情况吗?你有过醒来以后等闹钟的经历吗?如果你有时候在闹钟响之前就起来了,那么你会不会希望闹钟能知道你已经起来了?如果你提前醒了,那么闹钟就不响,只有你一直睡着的时候,闹钟才会按时响起来。
virtualenv 可以虚拟出一个独立的Python环境,在这个环境中安装的第三方库不会对系统中的Python产生影响。作为一个系统洁癖,我的系统中的Python环境只安装最主要的第三方库,我在开发Python项目的时候一般使用virtualenv生成的独立环境来安装项目需要的第三方库。但是如果同时使用了zsh的alias 和virtualenv,有可能就会导致virtualenv下面的python不能使用第三方库。
一般我们会使用以下两种方式之一来运行Python:
1 | python xxx.py |
或者在代码的第一行加上python的路径:
1 | #! /usr/local/bin/python |
这两种方式,使用的是系统中的Python来解释代码。
如果电脑上安装了Python2 和Python3, 那么想运行Python3写的代码的时候,我们可以使用以下方法来运行:
1 | python3 xxx.py |
但是由于有人不想写数字3, 于是就使用了zsh的alias功能,在~/.zshrc文件中,添加了一行:
1 | alias python=/usr/local/bin/python3 |
在这种情况下,使用:
1 | python xxx.py |
就可以通过Python3来解析代码了。这种方式使用系统中的Python没有问题,但是如果在virtualenv下面可就惨了。
我们创建一个虚拟环境并激活,安装Python的requests库,再启动python并导入requests库, 并其代码流程如下:
1 | $ virtualenv --python=python3 venv |
如果我们设置了上面的alias,那么你一定会得到下面的结果:
1 | Traceback (most recent call last): |
于是你打开venv/lib/python3.5/site-packages却发现requests安安静静的躺在里面。于是你百思不得其解,明明pip 是把requests安装在虚拟环境下面的,为什么Python不能正常导入呢?于是你再执行以下代码查看环境变量:
1 | import sys |
你看到的可能是下面的结果:
1 | ['', |
全部是系统下面Python的路径,和你的virtualenv 没有一点点的关系。
然后你退出Python,在虚拟环境下面打印PATH,你却发现:
1 | $ echo $PATH |
你的virtualenv环境好好的躺在你的环境变量的最前面。于是你快要疯掉了,到底是什么鬼,怎么会发生如此灵异的事件?系统不应该是首先找环境变量第一个位置下面的Python吗?怎么会跳过虚拟环境,去打开了系统中的Python呢?应该直接打开虚拟环境下面的Python才对啊!
问题的根源就在你的alias上面。
zsh 的alias的优先级是非常高的,它会首先替换为等号后面的内容,然后再执行。那么即使在虚拟环境下,在终端输入python并回车以后,实际执行的代码是:
1 | /usr/local/bin/python3 |
你使用了绝对路径打开了系统中的Python3。
而由于你没有对pip 设定alias, 因此你使用pip 安装requests的时候,它调用的是虚拟环境下面的pip,所以requests会正确安装在虚拟环境下面。
解决办法有两个:
~/.zshrc中删除下面的代码,并重启终端:1 | alias python=/usr/local/bin/python3 |
~/.zshrc中的:1 | alias python=/usr/local/bin/python3 |
修改为
1 | alias python=python3 |
本文首发地址: http://kingname.info/2016/06/27/alias-vs-virtualenv/转载请注明出处。
我曾经是一个对Java非常反感的人,因为Java的语法非常啰嗦。而用惯了动态类型的Python再使用静态类型的Java就会觉得多出了很多的工作量。
因为工作的关系,我开始使用Java来做项目。在这个过程中,我发现Java在某些方面确实和Python不一样。
有一句话说的好:
语言决定了世界观。
当我Java用的越来越多的时候,我渐渐发现我不是那么讨厌它了。
今天我要讲的,是我从Java里面学到的,一个被称为JavaBeans的东西。
In computing based on the Java Platform, JavaBeans are classes that encapsulate many objects into a single object (the bean). They are serializable, have a zero-argument constructor, and allow access to properties using getter and setter methods.
一句话概括起来: 当一些信息需要使用类似于字典套字典套列表这种很深的结构来储存的时候,请改用类来储存。
在Python里面,我以前会写这样的代码:
1 | person_list = [{ |
由于Python动态类型的特点,字典里面的value经常是包含了各种类型,有时候,字典里面包含了字典,里面的字典里面还有列表,这个内部字典里面的列表里面又包含了字典……
当我刚刚开始写Java代码的时候,也会保留了这个坏习惯,于是我定义的一个变量类似于这样:
1 | public Map<String, List<Map<String, Map<String, Object>>>> info = ..... |
并且由于Java是静态类型语言,有时候Map里面的Value类型还不一致,需要使用Object来代替,等要使用的时候再做类型转换。
对于这样的写法,真可谓是写代码一时爽,调试代码火葬场。我过几天读自己的代码,自己都不知道这个字典里面有哪些内容,也不知道它们有哪些类型,必须到定义的地方去看。
我的Mentor看了我的Java代码以后,让我去用一下JavaBeans,于是我的世界瞬间就简洁多了。后来我将JavaBeans的思想用到Python中,果然Python代码也变得好看多了。
使用上面person_list这个复杂的结构为例,我用JavaBeans的思想,在Python里面重构它:
1 | class Person(object): |
1 | class Detail(object): |
从这里可以看到,我把字典变成了类。于是,当我想保存我自己的信息和小明的时候,我就可以这样写:
1 | detail_kingname = Detail(address='xxx', work='engineer', salary=10000), |
这样写,虽然说代码量确实翻了不止一倍,但是当我们后期维护的时候或者遇到问题来调试代码,我们就能发现这样写的好处。
举一个很简单的例子,在写了代码一年以后,我已经对这段代码没有多少印象了,现在我得到了变量person_list, 我想查看每个人的工资。首先,由于Person和Detail这两个类是已经定义好的,分别放在Person.py和Detail.py两个文件中,于是我点开它们,就知道,原来工资是保存在Detail这个类中的,关键词是salary, 而Detail又是保存在Person中的,关键词是detail。
所以要查看每个人的工资,我可以这样写:
1 | for person in person_list: |
但是如果我使用的是最上面字典的那种方式,那么情况就没有这么简单了。因为我不知道工资是在这个字典的什么地方。于是我首先要找到person_list是在哪里初始化的,然后看它里面有什么。在这个例子中,我是一次性把整个列表字典初始化完成的,直接找到列表初始化的地方就知道,原来这个person_list下面有很多个字典,字典有一个key 叫detail,这个detail的value本身又是一个字典,它下面的keysalary保存了工资的信息。这似乎还比较方便。但是如果字典里面的信息不是一次性初始化完成的呢?万一detail这一个key是后面再加的呢?于是又要去找detail初始化的地方……
第二个好处,使用Beans的时候,每个关键字是定义好的,salary就只能叫做salary,如果写成了salarv, 集成开发环境会立刻告诉你,Detail没有salarv这个属性。但是如果使用字典的方式,我在给字典赋值的时候,一不小心:
1 | detail['salarv'] = 0.5 |
由于这里的salarv是字符串,所以集成开发环境是不会报错的,只有等你运行的时候,尝试读取detail['salary']里面的值,Python会告诉你:
1 | Traceback (most recent call last): |
将JavaBeans的思想用在Python中,避免字典套字典这种深层嵌套的情况,对于一些需要反复使用的字典,使用类来表示。这样做,别人读代码的时候会更加的容易,自己开发的时候,也会避免出现问题。
本文首发于:http://kingname.info/2016/06/19/bean-in-python/ 转载请注明出处。
MarkdownPicPicker 是基于Python3 的Markdown写作辅助工具, 作者是我。它能将剪贴板中的图片上传到网络图床中,并将markdown格式的图片链接()复制到剪贴板中。
项目地址:https://github.com/kingname/MarkdownPicPicker
第0.2版有以下功能:
配置文件保存在config.ini文件中,其意义分别如下:
1 | [basic] |
其中access_key 和 secret_key 可以在七牛云的控制面板中看到,如图: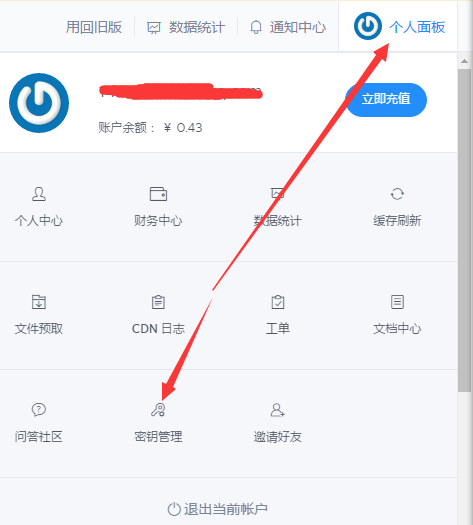
container_name 为下图所示内容: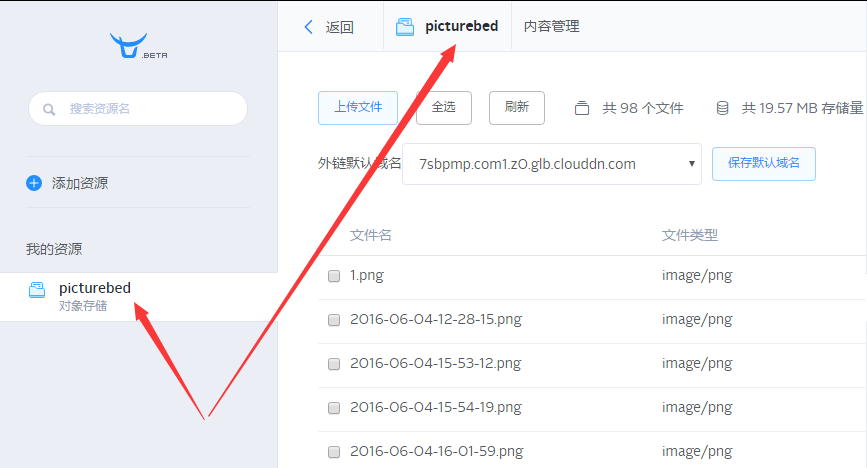
short_key_one 和 short_key_two 为快捷键的两个按键,默认为左侧windows徽标键(Lwin) 和 字母 C。
将程序配置好以后运行,创建一个批处理文件markdownpicpicker.bat, 其内容如下:
1 | @echo off |
路径请根据实际情况修改。
由于我使用了virtualenv, 所以需要在批处理中进入virtualenv的环境才能正常运行程序。对于将requirements.txt里面包含的库直接安装在全局的情况,bat 可以简化:
1 | @echo off |
不论哪种方式,均不要在任何相关的路径上出现中文,否则会导致不可预知的问题。
然后右键选择批处理,发送到桌面快捷方式。接着右键快捷方式,属性,在“快捷键” 这一栏按下字母Q,它将自动填充为 Ctrl + Alt + Q, 确定。
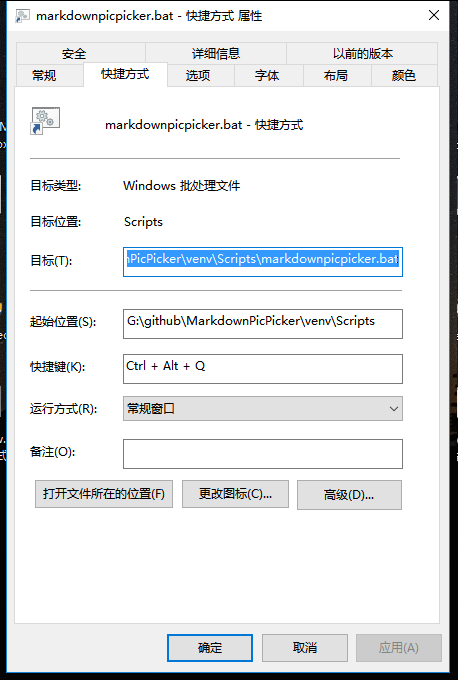
只需要首先使用QQ截图或者其他截图工具将图片保存到剪贴板中,然后按下设定好的快捷键即可。Markdown格式的图片链接就已经保存到剪贴板中了。在需要使用的地方直接粘贴。
不过这样设定的快捷键,按下以后会有大概一秒钟的延迟。推荐大家使用AutoHotKey来触发这个bat文件。
本程序使用了Pillow库中的 ImageGrab.grabclipboard() 方法来获取剪贴板中的数据,但是由于这个方法有一个bug, 导致可能会爆以下错误:
1 | Unsupported BMP bitfields layout |
这个问题从Pillow 2.8.0开始,一直到3.2.0都没有被官方解决。目前有一个间接的解决办法。
请打开Python安装目录下的\Lib\site-packages\PIL\BmpImagePlugin.py文件,将以下代码:
1 | if file_info['bits'] in SUPPORTED: |
修改为:
1 | if file_info['bits'] in SUPPORTED: |
就能解决本问题。
本程序还有一个功能是全局监听键盘,通过特殊的快捷键组合就可以直接触发读取图片上传图片的操作。但是由于这个功能使用到了pyHook这个库。但是这个库在设计上存在缺陷,如果当前窗体的标题包含Unicode字符时,会导致Python崩溃。因此这个功能默认不启动。
如果不清楚某个键盘按键对应的字符串是什么样子的,可以运行QueryKey.py这个文件,运行以后按下某个键,控制台上就会显示相应的信息。其中Key就是可以设置到SHORT_KEY_ONE和SHORT_KEY_TWO的内容。如图为按下键盘左Shift键以后显示的信息。
本文首发地址-> http://kingname.info/2016/06/04/markdownPicPicker/ 转载请注明出处
软件开发的过程是一个从简单到复杂的过程。我们在开发的时候,会首先写出具有核心的功能的原型,满足基本的需求。但是这个原型使用非常的麻烦,有无数的配置,数据的格式也需要严格的规定,稍微一个不合法的输入输出就有可能导致程序的崩溃。
接下来,在这个基本的原型上,我们逐渐进行完善,逐渐提高了程序的鲁棒性,用户体验逐渐的提高。新的需求出现了,于是又添加新的功能来满足新的需求。
在这样一个逐渐搭建(迭代)起来的过程中,我们要进行不间断的测试来保证修改没有破坏代码的已有功能,也要防止引入新的bug.如果是团队开发,要保持代码风格的一致。如果多个人同时开发,又要防止代码修改的地方出现冲突。一个版本的代码开发完成了,测试也没有问题了,同时部署到几百台服务器上,完成新功能的上线。
这样一个流程,如果手动来完成是相当痛苦的。于是,就需要持续集成来帮助我们完成这些琐碎的工作。开发者开发好了程序,本地测试没有问题了。使用Git提交到代码仓库,然后触发一系列的检查流程,如果出问题就给提交者发邮件提示问题,如果一切正常就开始代码审核(code review),审核完成,合并代码。合并完成以后,会自动做好部署前面的集成测试,然后等待下一次部署周期到达以后自动将代码部署到各个服务器。
持续集成这个系列的文章,就是要完成以上各个环节的搭建工作,从而让开发者把精力放在开发上,而不是一些无谓的体力劳动上。
我会使用树莓派2 来搭建持续集成的环境,树莓派的系统为ArchLinux.
Jenkins是一个用Java编写的开源的持续集成工具。它是持续集成的核心部分,扮演了一个总管的角色,统筹联系各个部分。
1 | sudo pacman -S jenkins |
由于jenkins是Java写的,所以这个时候如果你的系统中没有Java的运行环境,他就会让你选择安装jre7-openjdk 或者是jre8-openjdk, 我选择的是安装jre8-openjdk. 这个时候我没有意识到,隐患已经埋下来了。
在ArchLinux中,什么东西都喜欢使用systemd来启动,所以执行以下命令来启动Jenkins:
1 | sudo systemctl start jenkins.service |
理论上这样就能使用了。但是当我在浏览器打开http://192.168.2.107:8090的时候却发现网页无法打开。于是检查它的log:
1 | journalctl -u jenkins |
发现原来报错了。如图: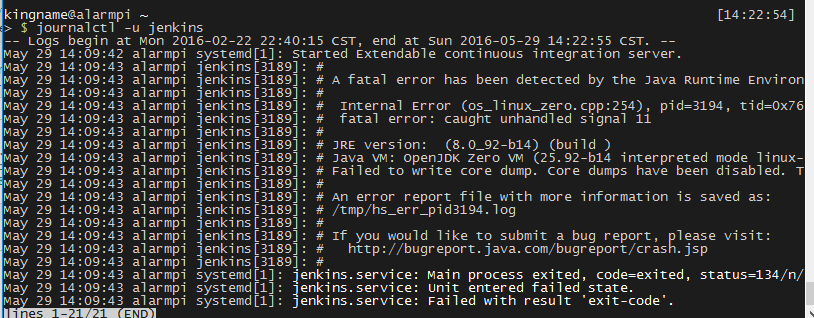
难道说Java环境有问题?于是我是用:
1 | java -version |
来检查Java环境,果然, 连查看Java 的版本都报错了,如图: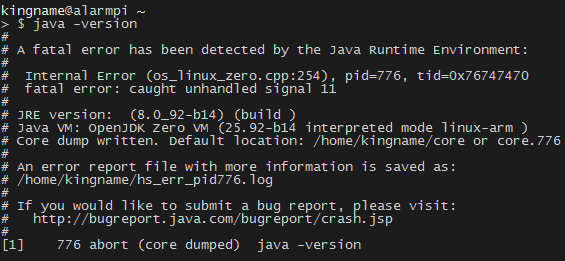
对于这种情况,看起来不能使用openJDK了,于是去安装Oracle的JDK。
首先要卸载openJdk:
1 | sudo pacman -Rdd jre8-openjdk |
这里使用-Rdd 而不是-R就是为了忽略依赖性。如果直接使用-R的话,会报错,无法卸载。
如何判断卸载是否完成呢?
1 | java -version |
提示找不到Java的时候,就说明卸载完成了。如果此时依然会爆出上面的core dumpd的错误, 就说明openJDK没有卸载干净。输入:
1 | sudo pacman -Rdd jre |
然后按键盘上面的Tab键,让自动完成功能来探测到底是哪个部分还没有卸载。
完全卸载干净openJDK以后,就可以安装Oracle的JDK了。
由于Oracle的JDK不能直接使用pacman来安装,所以需要使用AUR。树莓派的CPU是ARM架构,所以使用使用arm版的JDK。如果有朋友是在X86的电脑上面安装的话,可以使用x86版的JDK。
对于安装AUR的文件,首先从左侧Download snapshot下载pkg文件,然后使用以下命令来安装:
1 | tar -xvf jdk-arm.tar.gz |
然后就等待下载安装文件然后完成安装。如图: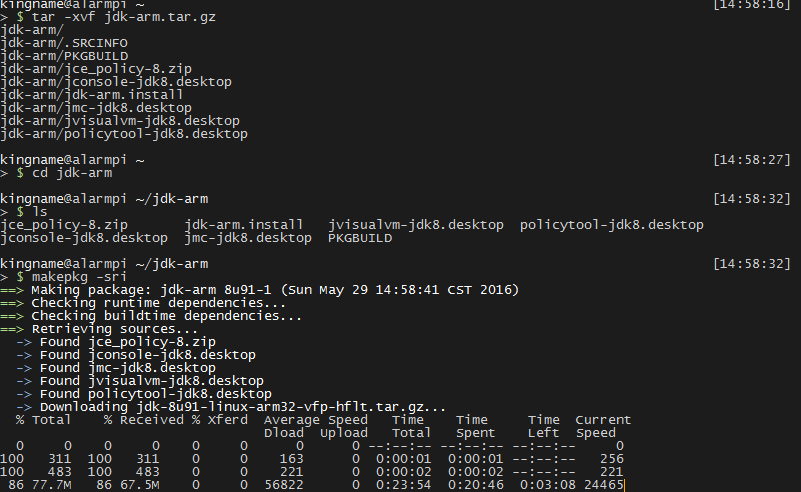
完成以后,我们再执行:
1 | java -version |
就可以正常看到Java的版本信息了。
再一次启动Jenkins:
1 | sudo systemctl start jenkins.service |
也可以正常启动了。(输入命令以后等待1分钟左右,让服务完全启动起来。)如图:
根据它的提示读取密码,并填写到网页上,于是Jenkins就算是安装成功了。
插件是Jenkins的精华,在第一次进入的时候,Jenkins就会让你选择插件。这里我选择Select plugins to install.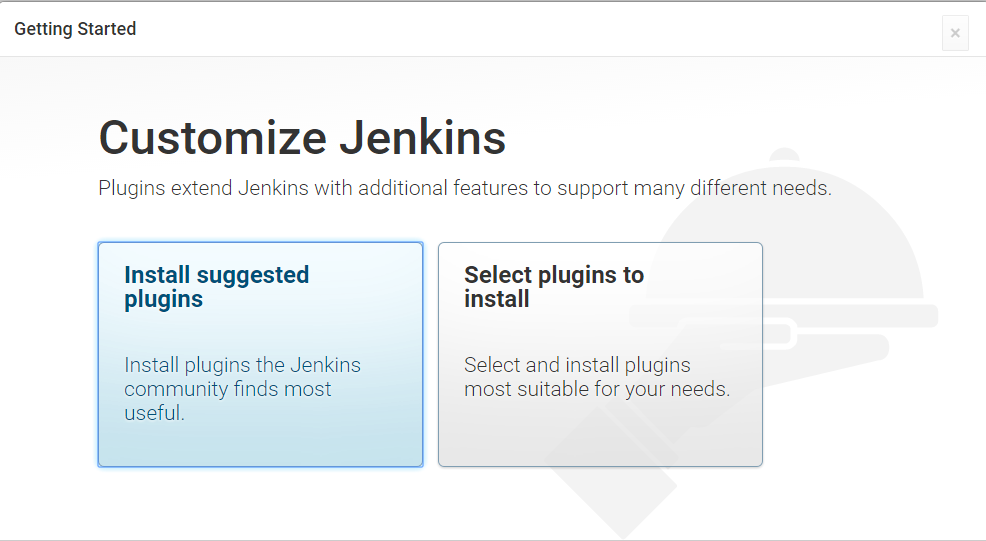
它默认已经勾选了一些插件,我增加了以下的插件:
选择好以后点击 install就可以等待它安装了。如果发现漏选了或者多选了也没有关系,因为之后还可以手动管理这些插件。
这一篇讲到了如何在树莓派上面搭建Jenkins并安装插件。下一篇将会讲到Jenkins Job的创建和配置和使用。
在极客学院讲授《使用Python编写远程控制程序》的课程中,涉及到查看被控制电脑屏幕截图的功能。
如果使用PIL,这个需求只需要三行代码:
1 | from PIL import ImageGrab |
但是考虑到被控端应该尽量的精简,对其他模块尽量少的依赖,这样才能比较方便的部署,因此我考虑能否有一种方法,不依赖PIL来实现截图的功能。
由于被控端使用了win32api, 因此有一个方法:
1 | win32api.keybd_event |
这个方法可以模拟键盘的按键动作。因此,解决方法就比较的明显了:
第一步非常的简单,实用win32api 和 win32con,两行代码就能实现:
1 | import win32api |
其中win32con这个库里面包含了很多定义好的和Windows相关的常量,而VK_SNAPSHOT就是Print Screen键的键位码。后面的数字0表示截取整个屏幕。如果改成数字1,表示截取当前窗口。
那么现在问题来了,在不实用PIL的情况下,如何将剪贴板你们的图片保存到本地?
win32api有一个模块 win32clipboard 是负责剪贴板相关的操作。它有一个方法:
1 | win32clipboard.GetClipboardData(formats) |
这个方法可以从剪贴板里面读取数据。但是需要指定数据的格式。从这里可以查看到更多的标准剪贴板格式(Standard Clipboard Formats).
一开始我使用的formats是CF_BITMAP,程序返回的是一串整数,怀疑应该是一个内存地址。这也和这个format的描述:
A handle to a bitmap (HBITMAP).
是一致的,它是一个handle。
我也尝试过CF_TIFF, 不过程序直接报错了,可见我使用Print Screen截图以后,剪贴板里面的图片格式并不是TIFF。
经过查阅其他资料,我最后确定使用了CF_DIB。
A memory object containing a BITMAPINFO structure followed by the bitmap bits.
这个描述说明,CF_DIB返回的是一个内存对象,包含了BIT格式图片的信息。经过测试使用:
1 | win32clipboard.GetClipboardData(win32con.CF_DIB) |
以后,可以得到一个很大的字符串。显然这个字符串就是图片的内容了。但是当我把这个字符串写入到bmp格式的文件后,却发现图片无法打开。
在StackOverflow上,我遇到了一个非常好的老先生: Mr. martineau他为了解答了问题,并给我提供了解决办法。以下内容翻译自martineau先生的回答,原文请戳->http://stackoverflow.com/a/35885108/3922976
你的方法的主要问题在于,你写入文件的字符串缺少了.bmp 文件头,这个文件头是
BITMAPFILEHEADER结构。
为了创建这个文件头,使用
GetClipboardData()返回的字符串必须要进行解码(decoded)。对于CF_DIB格式来说,返回的字符串的前面一部分就是BOTMAPINFOHEADER。
对于各种各样有不同种类压缩的
DIB来说,这种文件头结构是非常的普遍的。不过幸好对截图来说,只需要简单的无压缩的RGBA像素。
由于
BOTMAPFILEHEADER被放在了bf0ffBits的区域里,所以事情就变得很容易了。而其他的情况,例如大尺度的颜色表跟在BITMAPINFOHEADER和像素数组的开头。
(这一段我看不太懂,还请如果有能正确解释这段话的朋友指正。原文是:
That fact makes things much easier because otherwise determining the value to put in the bfOffBits field of the BITMAPFILEHEADER would be complicated by the fact that in most other cases there’s also a variably-sized color table following the BITMAPINFOHEADER and the start of the pixel array.)
下面的代码是一个简单的例子(仅仅针对这个需求):
1 | import ctypes |
经过测试,这一段代码成功的实现了读取剪贴板的图片并保存到本地。
这段代码使用ctypes库来实现指针的功能,从而在内存中操作数据。这里定义了两个结构体,BITMAPFILEHEADER 和BITMAPINFOHEADER,于是,使用sizeof获取到了他们的大小。那么使用指针,从使用GetClipboardData()获取到的数据的头部开始移动,分别移动这两个结构体的大小,也就获取到了这两个结构体在内存中的数据。
代码中使用了memmove和memset两个内存操作的方法。从ctypes的官方文档上,我们可以看到这两个方法有如下的定义:
ctypes.memmove(dst, src, count)
Same as the standard C memmove library function: copies count bytes from src to dst. dst and src must be integers or ctypes instances that can be converted to pointers.
ctypes.memset(dst, c, count)
Same as the standard C memset library function: fills the memory block at address dst with count bytes of value c. dst must be an integer specifying an address, or a ctypes instance.
所以可以看出,代码里面的:
1 | bmih = BITMAPINFOHEADER() |
从内存中拷贝出来了BITMAPINFOHEADER这么大的一块的数据,并保存到了bmih这个变量中。
1 | bmfh = BITMAPFILEHEADER() |
这一段在内存中开辟出了BITMAPFILEHEADER这么大一块区域,并全部填充为0.
1 | bmfh.bfType = ord('B') | (ord('M') << 8) |
这一行代码使用了位操作。首先ord('B')的值为66,换成二进制就是1000010;ord('M')的值为77,换成二进制就是1001101,然后向左移动8位,得到100110100000000,这个值再与1000010取位或,得到100110101000010。
最后,使用:
1 | bmfh.bfOffBits = SIZEOF_BITMAPFILEHEADER + SIZEOF_BITMAPINFOHEADER + SIZEOF_COLORTABLE |
拼装出头部的大小。然后以二进制方式,首先写文件头, 再写剪贴板获取到的字符串到本地的.bmp文件中,完成图片的生成。
Python一些轮子确实非常好的提高了开发效率,例如PIL,三行代码实现了我的需求。Python在快速开发方面确实非常的方便,但是涉及到底层的一些操作的时候,还是不得不使用C语言的一些接口来进行内存的操作。